Intro
Apache Solr 공식 튜토리얼 문서를 따라 진행해보며 조금은 더 이해하기 쉽게 각색 해 보았습니다.
모두 아시는 것처럼 최고의 레퍼런스는 공식 문서임에는 틀림이 없지만 공식문서가 항상 가장 이해하기 쉬운 것은 아닙니다. 최대한 쉽게 작성하기 위해 많은 노력이 있었겠지만 애초에 문서 작성자와 튜토리얼 사용자의 눈높이가 다를 수밖에 없고 언어도 영어로 작성되었기 때문에 시간과 집중력이 더 많이 필요합니다.
Apache Solr를 처음 사용해보는 입장에서도 쉽게 따라할 수 있도록 생소한 용어들에는 주석을 달았으며 어려울 수 있겠다고 생각 되는 부분들은 최대한 자세히 풀어서 진행해 보았습니다.
해당 튜토리얼을 통해 Solr를 로컬에 설치 및 실행하고, 다양한 종류의 데이터 소스를 Solr 컬렉션으로 이관 시켜 볼 예정입니다. 또한 Solr 관리자 모드와 검색 인터페이스를 쉽게 사용해보며 익숙해지는 과정도 거치게됩니다. 튜토리얼을 마친다고 바로 Solr 전문가가 되는건 아니지만 확실히 전체적인 흐름은 파악할 수 있게 됩니다.
본 튜토리얼은 크게 3가지의 실습 단계로 구분됩니다.
- 실습1. Solr 실행 및 컬렉션 생성, 기본 document들을 색인하고 간단한 검색 시연해보기
- 실습2. 다양한 데이터셋으로 실습해보고, requesting facets(요청 패싯) 으로 탐색해보기
- 실습3. 본인의 데이터로 작업 해 보고 스스로 검색 엔진 구현하기
만만치 않은 분량이지만 검색엔진 입문에 이정도면 충분히 시도 해 볼만 하고 누구나 따라할 수 있게 작성 되었다고 생각합니다. 간혹 막히는 부분이 있다면 댓글을 남겨 주시면 최대한 빨리 도와드리도록 하겠습니다.
차근차근 시작 해 보겠습니다.
Solr 설치
Downloads
최신 버전의 Binary release를 다운 받아 줍니다. 저는 solr-8-11.1.zip 파일을 다운로드 했습니다.
Unzip
원하는 폴더에 압축을 풀어 줍니다.
bash
unzip solr-8.11.1.zip -d ~/Documents/utils/
실습 1. Techproducts 예제 색인
이번 실습을 통해 Solr를 두개의 노드 클러스터로 띄우고 Collection을 생성 하게 됩니다. 그러고 나서 Solr에 기본적으로 포함된 실습 데이터를 색인 하고 몇몇 기본적인 검색을 해 보도록 하겠습니다.
SolrCloud 모드로 Solr 실행
/bin
Solr를 시작 하기 위해 Linux나 MacOS에서는 bin/solr start -e cloud 명령어를, Windows 에서는 bin/solr.cmd start -e cloud명령어를 입력 해 줍니다.
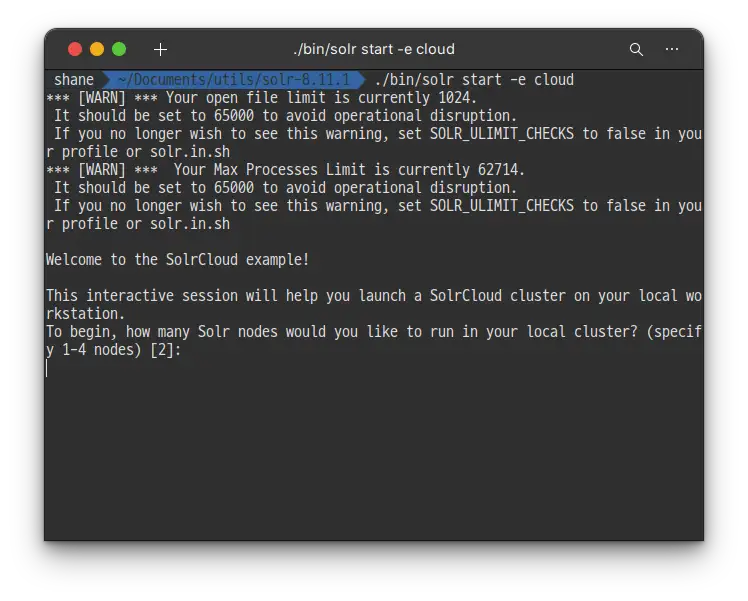
처음에는 몇개의 Solr node를 실행하고 싶은지 물어봅니다. 마지막에 [2] 라고 써있는 것처럼 기본값이 이미 2로 설정 되어 있으니, 간단하게 엔터키만 입력해 줍니다.
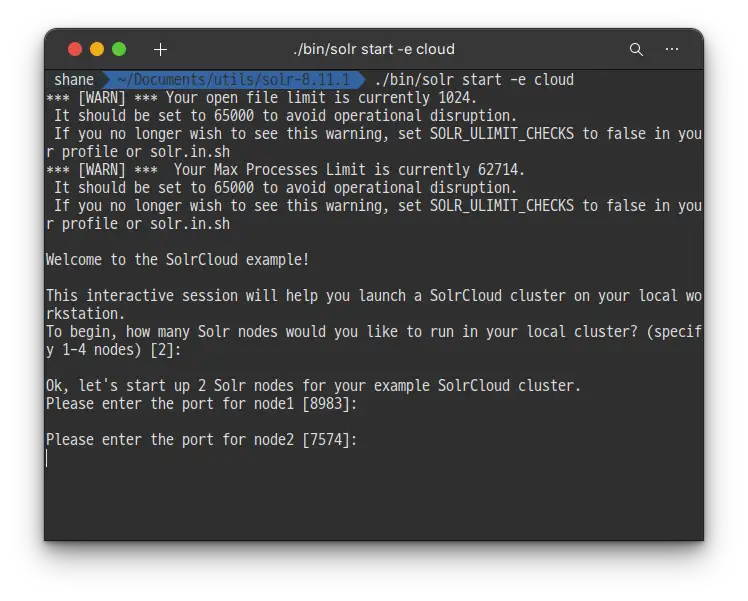
이번에는 각각의 노드에 할당할 포트 번호를 설정하는데요, 각각의 포트를 사용하는 곳이 딱히 없다면 엔터키를 입력해 각각 8983/ 7574 포트를 사용하게 해 줍니다. Solr의 기본 포트는 8983 입니다.
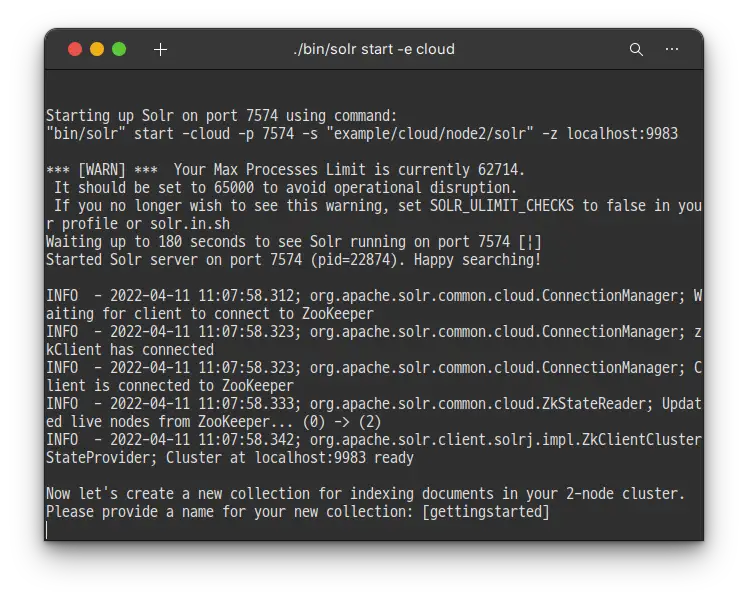
2개의 Solr 인스턴스가 2개의 노드에서 실행 되었습니다.
SolrCloud 모드로 솔라를 실행 했고, 외부 ZooKeeper 클러스터를 따로 지정 해 주지 않았기 때문에 Solr가 자체 ZooKeeper를 실행 하고 두개의 노드를 여기에 연결 하였습니다.
Apache ZooKeeper는 클라우드 어플리케이션들의 안정적인 분산 코디네이션을 위한 오픈소스 서버 입니다. 처음에는 하둡의 서브 프로젝트 였지만 지금은 독립적인 Top-Level-Project가 되었습니다.
실행이 잘 되었고, 이제는 색인을 위한 Collection을 생성 할테니 이름을 입력 하라고 합니다.
드디어 첫번째로 엔터를 치지 않고 값을 입력 할 때가 되었는데요.. 이번 튜토리얼에서 Solr에 포함되어 있는 샘플 데이터인 techproducts를 색인 해 볼 예정이기 때문에 techproducts 라고 입력 하도록 하겠습니다.
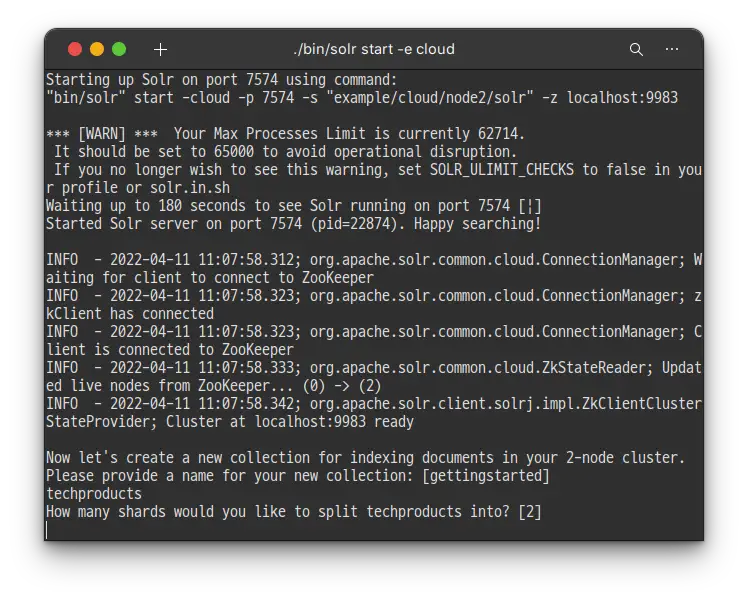
techproducts
그러면 이제 몇개의 shard를 만들어서 techproduct를 나눌지 물어봅니다.
기본값이 2로 되어있는데, 이렇게 하면 두개의 노드에 균일하게 색인을 나누게 됩니다. 엔터키를 입력 해 기본값인 2를 선택 하도록 합니다.
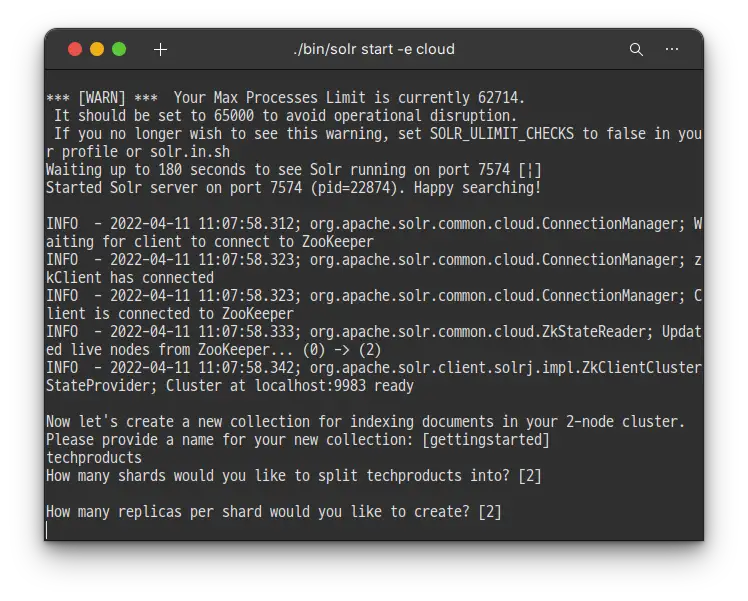
이번에는 replica를 몇개 만들지 물어보는데요, 레플리카는 Failover 기능을 위해 사용합니다. 이번에도 엔터키를 입력 해 기본값인 2를 선택하도록 합니다.
Failover: 장애 극복 기능을 말 합니다. 시스템이나 네트워크에 장애가 생겼을 때 미리 준비한 다른 시스템으로 자동 전환 되어 문제를 해결합니다.
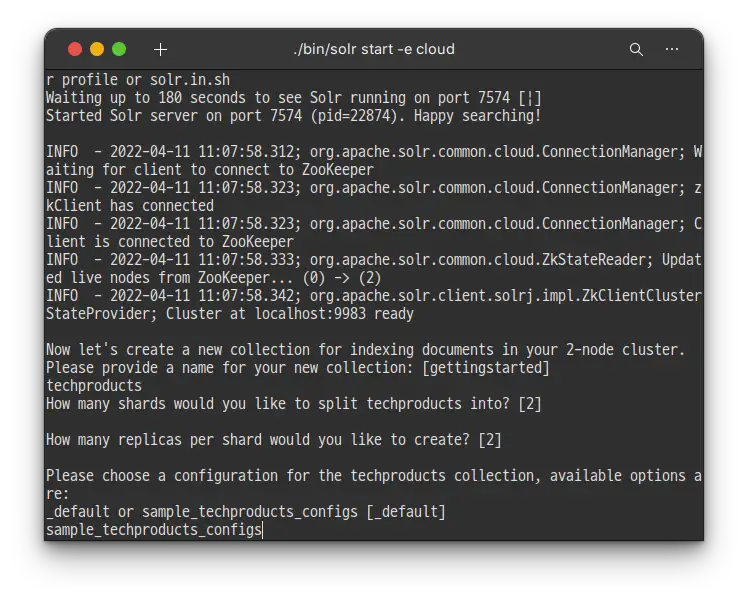
이번에는 컬렉션에 적용 할 설정 파일을 선택합니다. Solr는 기본적으로 configset 이라고 불리는 두개의 샘플 설정 파일이 있습니다.
모든 컬렉션은 반드시 두개의 메인 설정 파일을 포함한 하나의 configset을 갖는데요,두 개의 메인 설정 파일 목록은 아래와 같습니다.
- Schema File (
managed-schemaorschema.xml) solrconfig.xml
지금의 질문은 _default와 sample_techproducts_configs 둘 중 어떤 configset으로 시작할 지 선택하라는 옵션 입니다. _default는 베어본 옵션이고, 또 다른 하나는 샘플 데이터를 위한 옵션 입니다.
우리가 위에서 컬렉션 이름을 techproduct 로 지은 것 에서 예상하셨겠지만 sample_techproducts_config를 입력 해 줍니다.
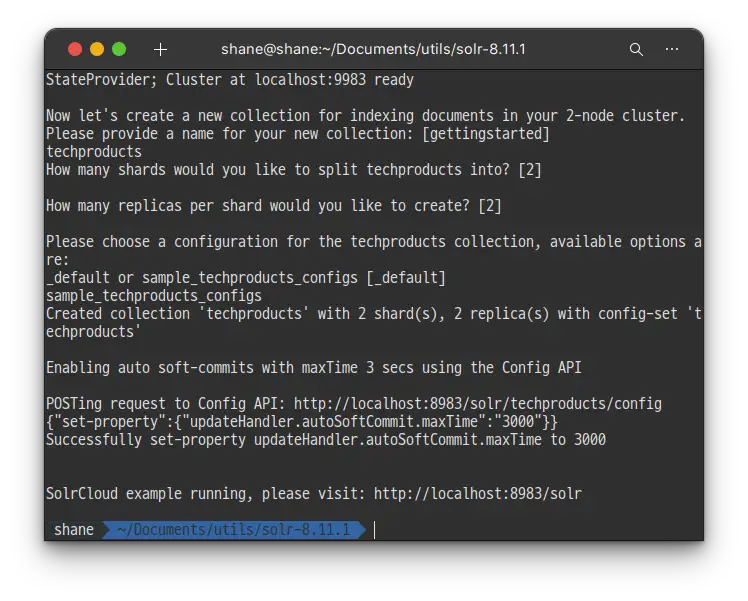
축하합니다! 이로서 Solr가 준비 되었습니다.
혹시 학습을 하다가 Solr를 종료 하고 싶다면 아래의 명령어로 종료 하실 수 있습니다.
bash
bin/solr stop -all
종료했던 Solr를 다시 켜서 학습을 이어가고 싶다면 아래의 명령어를 연속으로 입력 해 주시면 됩니다.
첫번째 노드 실행
bash
./bin/solr start -c -p 8983 -s example/cloud/node1/solr
두번째 노드 실행
bash
./bin/solr start -c -p 7574 -s example/cloud/node2/solr -z localhost:9983
이제 Solr 가 준비 되었으니 잘 작동 하는지 확인을 해 보도록 하겠습니다.
Solr Admin UI
웹 브라우저를 통해 http://localhost:8983/solr/ 페이지에 방문 하면, Solr 관리자 모드에 진입 할 수 있습니다.
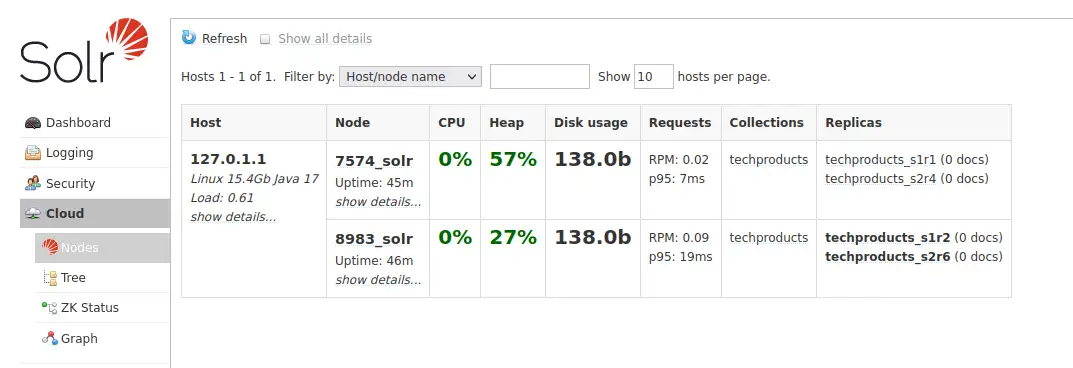
Solr는 현재 각각 8983과 7574 포트에서 두개의 노드로 실행 되고 있는데요, techproducts라는 이름으로 자동으로 생성된 하나의 컬렉션이 각각 2개의 레플리카를 가진 두개의 샤드로 나누어져 있습니다.
그림으로 표현하면 아래와 같습니다.

관리자 화면에서도 http://localhost:8983/solr/#/~cloud 페이지에서 보기 좋게 표로 나타내어 줍니다.
Techproducts 데이터 색인
Solr 서버를 띄우고 실행까지 했지만 정작 어떤 데이터도 포함하고 있지 않기 때문에 쿼리를 실행 해 볼 수 없습니다. 고맙게도 Solr는 다양한 타입의 문서들을 손쉽게 색인 할 수 있도록 /bin/post경로에 툴을 포함하고 있기 때문에 예제들을 색인 하기 위해 해당 툴을 사용 해 보도록 하겠습니다.
bin/post의 툴은 아직까지 윈도우에서는 호환이 되지 않기 때문에 대신 동봉된 자바 프로그램을 사용해야 합니다. Linux나 MacOS에서는 /bin/post에 있는 Tool을 바로 사용 하면 됩니다.
Linux/Mac
solr-8.11.0:$ bin/post -c techproducts example/exampledocs/*
Windows
C:\solr-8.11.0> java -jar -Dc=techproducts -Dauto example\exampledocs\post.jar example\exampledocs\*
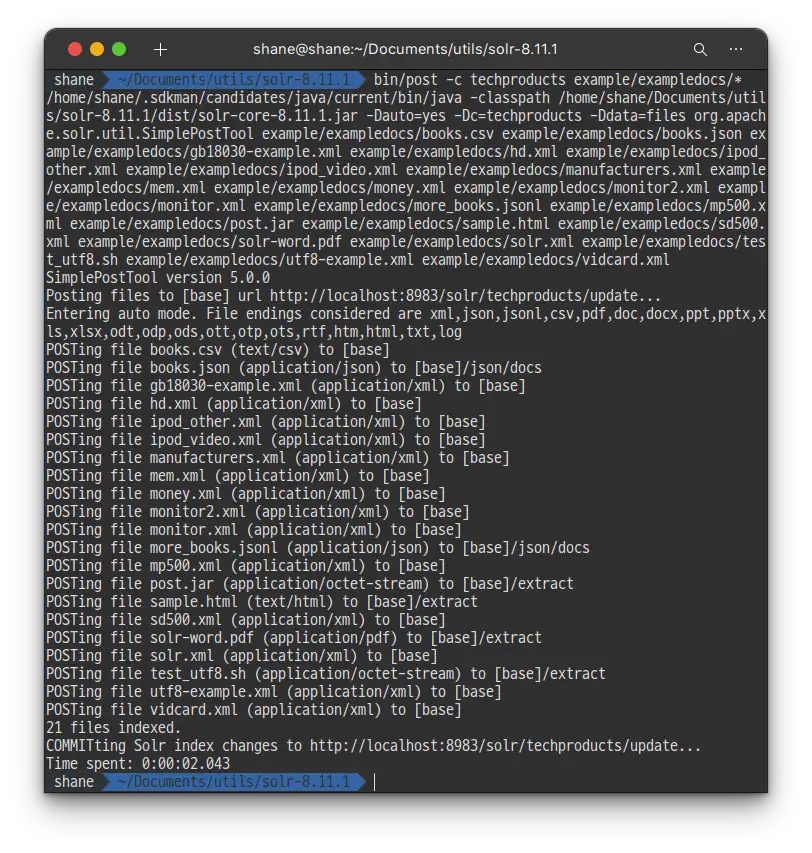
2.043초 만에 21개의 파일을 색인 해 주었습니다.
드디어 Solr에 데이터가 포함 되어 검색을 할 준비가 되었습니다!
기본 검색
Solr는 REST 클라이언트, curl, 포스트맨 등등 다양한 언어로 작성된 클라이언트를 통해 쿼리 할 수 있습니다.
고맙게도 Solr Admin UI는 쿼리탭을 통한 쿼리 빌더 인터페이스를 포함 하고 있기 때문에 Execute Query 버튼을 클릭해 JSON 포맷의 쿼리 결과를 확인 할 수 있습니다.
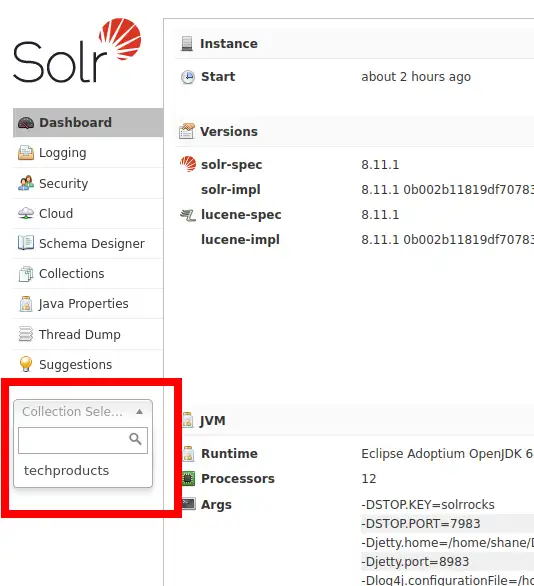
좌측의 Collection Select를 누르고 techproducts 컬렉션을 선택 해 줍니다.
이후 좌측 하단의 Query 버튼을 누르면 쿼리를 보낼 수 있는 인터페이스가 등장 합니다.
아무 수정 없이 바로 Execute Query를 수행 해 보겠습니다.
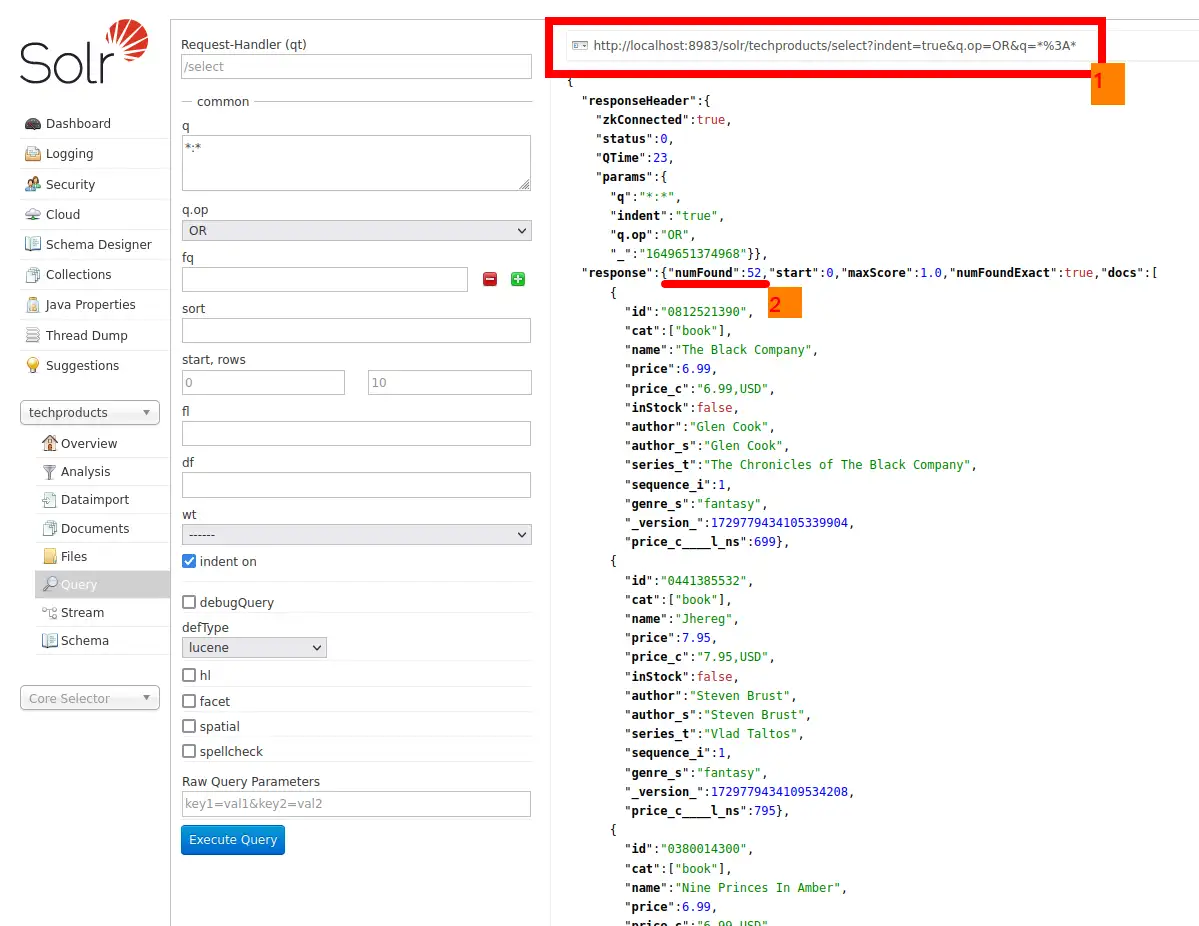
1번으로 표시 해 둔 http://localhost:8983/solr/techproducts/select?indent=true&q.op=OR&q=*%3A*가 요청된 url 입니다.
또한 2번에서 response에 있는 numFound의 값이 52로 나오는데, 그건 쿼리 결과가 총 52개 있다는 것 입니다.
파라미터 q의 값인 *:* 은 인덱스의 모든 document 들을 검색하라는 뜻 인데 실제 52개가 아닌 10개의 document만 확인 되는데요, 그 이유는 rows 파라미터를 따로 주지 않았기 때문에 default 값인 10이 설정 되었기 때문입니다. 좌측의 start, rows 텍스트 박스에 값을 넣어 변경 할 수 있습니다.
Solr는 정말 강력한 검색 옵션을 가지고 있고 그 양이 워낙 방대하기 때문에 튜토리얼을 통해 모든 옵션을 다루어 볼 순 없습니다. 대신 많이 가장 많이 사용되는 쿼리들 위주로 실습을 진행해 보도록 하겠습니다.
단어 검색
단순 단어로 검색 하기 위해 Solr Admin UI 화면에서 q 파라미터 텍스트 박스에 *:*으로 되어 있는걸 찾고자 하는 단어로 변경 해 줍니다.
q (Query String)
Foundation이라고 입력 해서 한번 검색 해 보도록 하겠습니다. curl을 통해 검색도 똑같이 해보겠습니다.
bashcurl "http://localhost:8983/solr/techproducts/select?q=foundation"
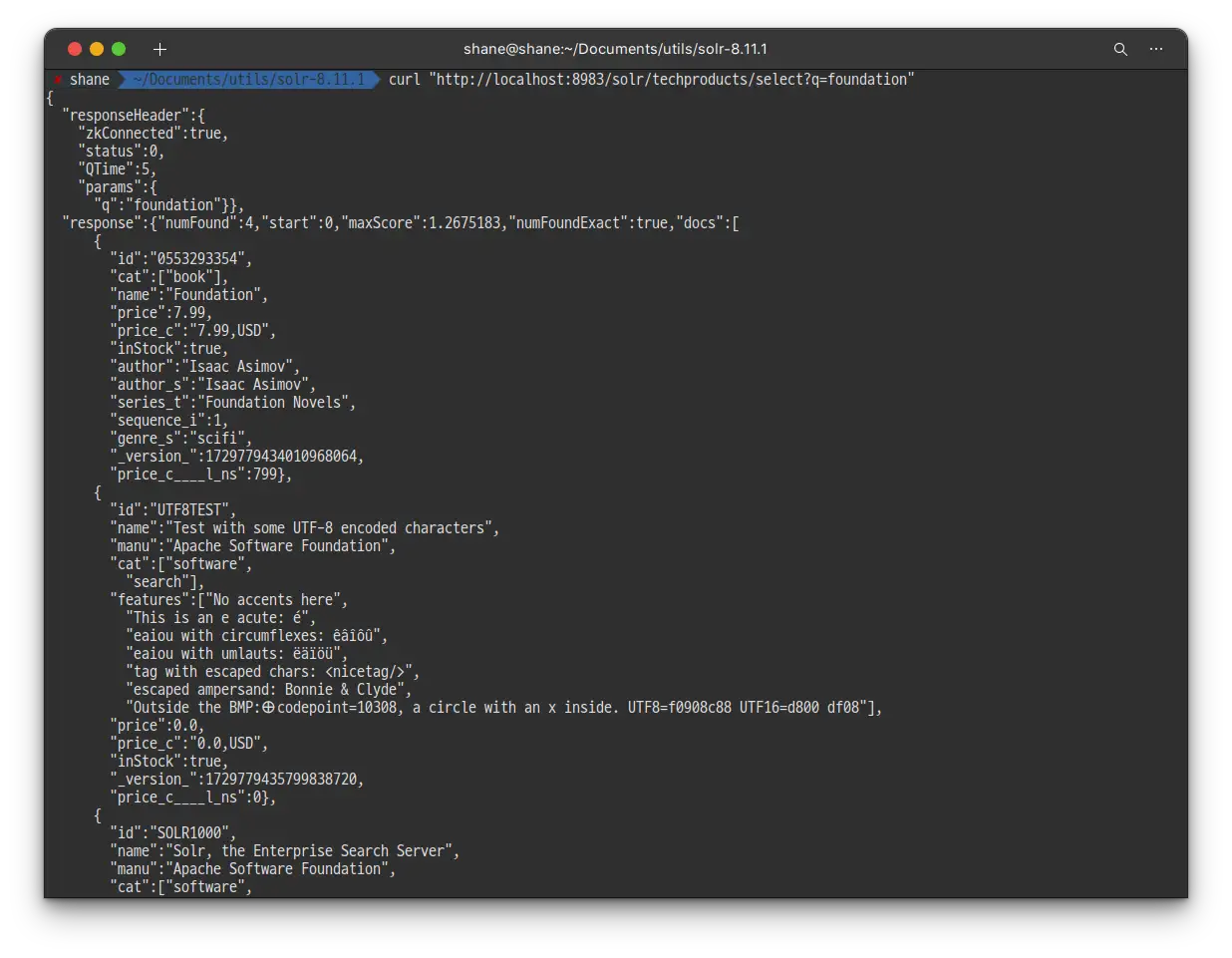
검색 결과 4개의 문서가 발견 되었습니다. 쿼리 결과는 JSON 형태로 반환 됩니다.
검색 결과가 기본 row 값인 10보다 적기 때문에 아까와는 다르게 4개의 모든 검색 결과를 확인 할 수 있습니다.
응답의 가장 위에 있는 responseHeader 를 자세히 살펴보겠습니다.
- 이 헤더는 검색쿼리에 사용한 모든 파라미터들을 포함합니다.
- 기본적으로 해당 쿼리에 적용시킨 파라미터들만 보여주며 지금의 경우에는 q만 작성 했기 때문에,
"params":{"q":"foundation"}만 표시가 되었습니다.
fl (Field List)
검색 결과로 받은 documents 들은 각각 모든 필드들을 포함 하고 있는데요, 기본적인 동작은 이렇지만 응답에서 보여줄 필드들을 제한하고 싶다면 fl파라미터를 등록 해서 요청 하면 됩니다. 각각의 필드명은 ,(콤마) 를 통해 구분되며 이 또한 Admin UI 에서 설정 할 수 있습니다.
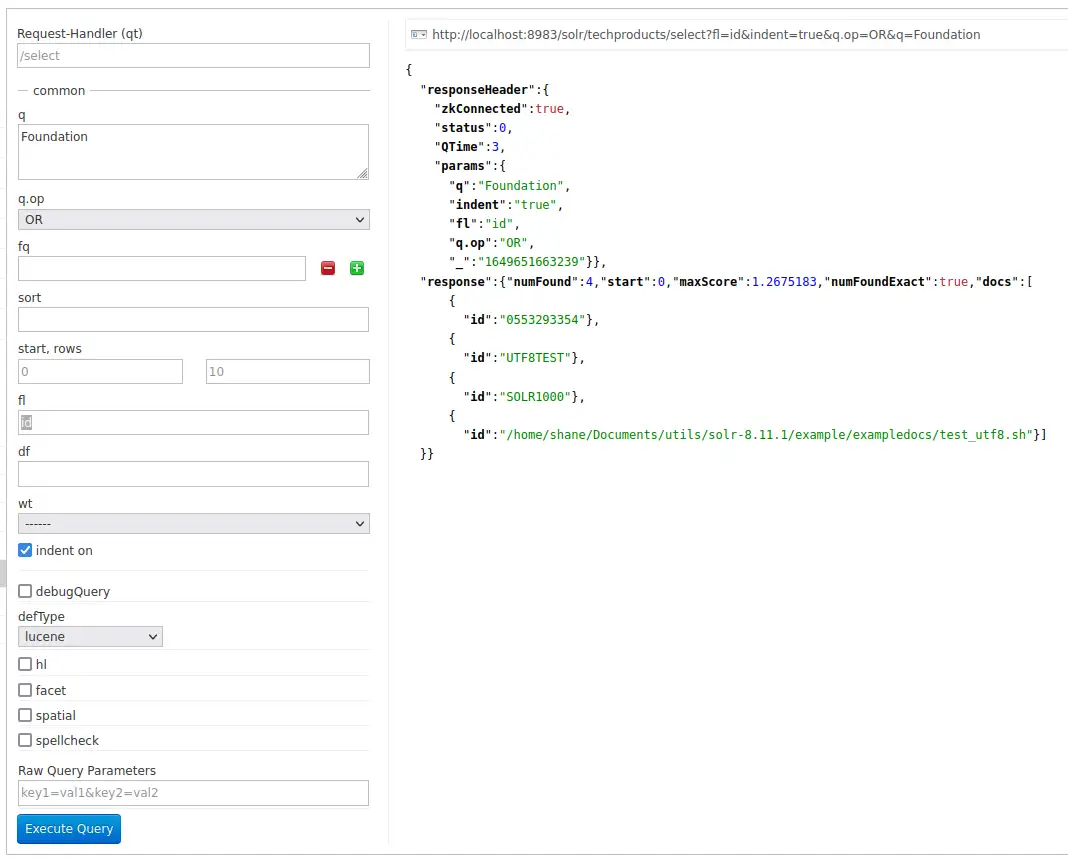
fl을
id로 제한 하니 4개의 검색 결과의 필드가 모두 id 만으로 제한 되었습니다.
필드 검색
모든 Solr에서의 쿼리는 일부 필드들을 사용해 검색을 수행합니다. 보통의 경우에는 여러가지 필드를 동시에 이용해서 검색 하는게 필요하고 지금까지 foundation 을 검색하는 쿼리를 작성하며 그렇게 해 왔는데요.
하지만 쿼리를 하나의 필드로 제한하여 검색 할 필요가 있을 때도 존재합니다.
흔히 우리가 게시판이나 도서 검색 등 에서 사용했던 것처럼 제목으로 검색, 작성자로 검색 등이 그 예가 될 수 있겠네요. 이 경우에는 쿼리가 훨씬 효율적이고 검색 결과 또한 사용자의 의도에 조금 더 가깝습니다.
저희가 사용중인 샘플 데이터 셋은 대부분 상품과 관련이 있습니다. 그럼 이번에는 색인에서 모든 전자제품을 한번 검색 해 보도록 하겠습니다. 처음에는 단순하게 q=electronics로 시작하겠습니다.
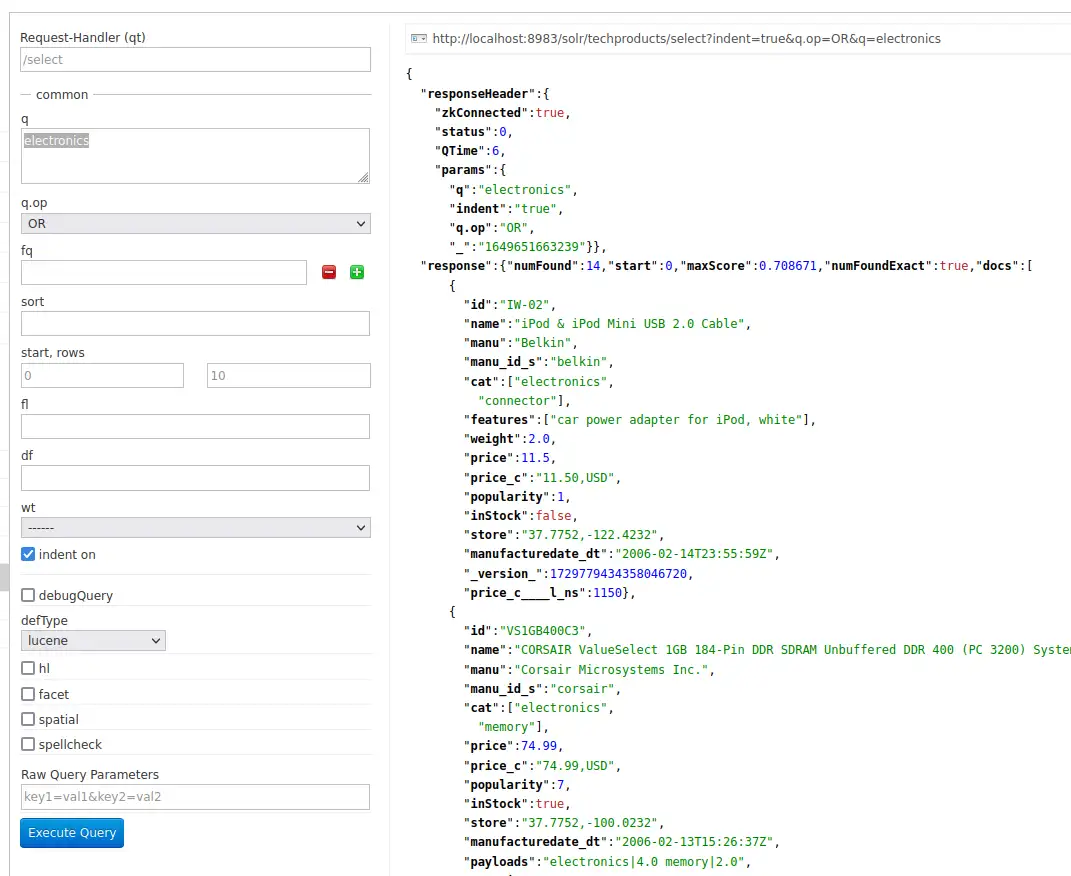
http://localhost:8983/solr/techproducts/select?indent=true&q.op=OR&q=electronics
총 14개의 검색 결과가 나왔습니다. 지금은 색인 된 모든 필드에서 electronics 라는 단어를 검색 했습니다.
그런데 필드를 자세히 살펴보면 cat이 보이는데요. electronics, connector, memory 등이 써 있는 걸 보아 카테고리를 분류 해 둔 필드라는걸 쉽게 알 수 있습니다. 이번에는 쿼리스트링을 cat:electronics로 변경 하면
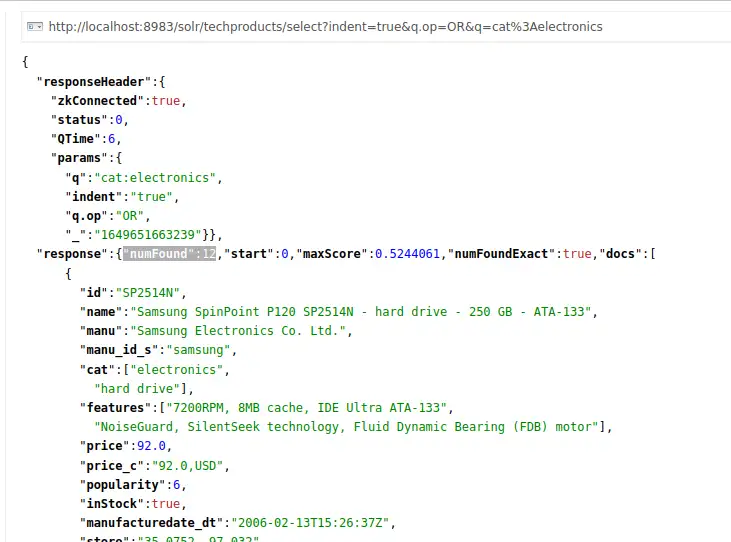
http://localhost:8983/solr/techproducts/select?indent=true&q.op=OR&q=cat:electronics
이번에는 12개의 검색 결과가 표시 됩니다.
문장 검색
여러개의 단어로 이루어진 문장을 검색하려면 쌍따옴표로 양쪽을 감싸서 쿼리를 작성하면 됩니다. 예를 들어 CAS latency를 검색 하려면 Solr Admin UI의 q 박스에 "CAS latency"라고 작성 해 주거나 curl을 사용한다면 띄어쓰기가 URL 인코딩 되며 +로 변환되어야 하는걸 명심해서 작성 해 주면 됩니다.
bashcurl "http://localhost:8983/solr/techproducts/select?q=\"CAS+latency\""
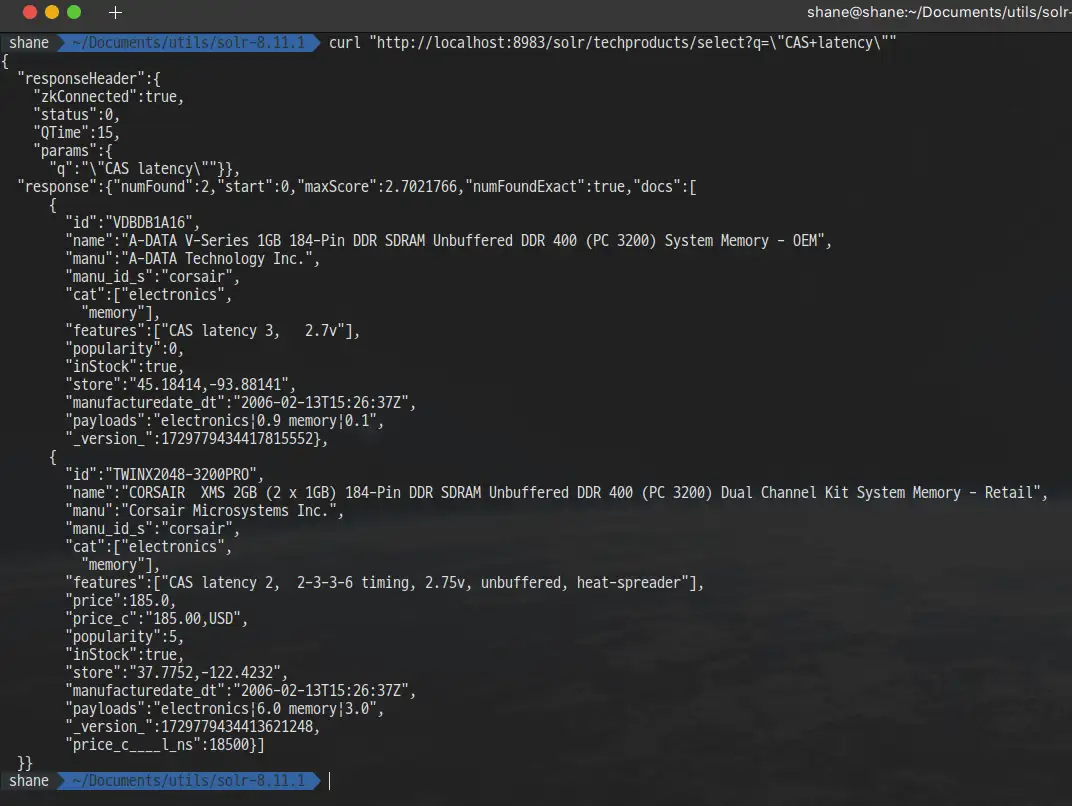
2개의 검색 결과가 나옵니다.
복합 검색
기본적으로 단일 쿼리에서 여러개의 단어나 문장들을 검색하면 Solr는 그중 하나만 존재하더라도 검색 결과에 해당하는 document로 인식합니다. 쿼리에서 요청한 단어를 여러개 포함하면 할 수록 결과 목록에서는 더 높은 순위가 되어 상위에 노출됩니다.
이 때, + prefix를 활용하면 반드시 포함 하도록 검색 옵션을 줄 수 있고 그 반대로 - prefix를 붙여 포함하지 않는 조건을 거는 것 또한 가능 합니다.
예를 들어 electronics와 music을 모두 포함하는 검색 결과를 위해 q박스에 + electronics +music 을 입력 하면 되는데요, curl을 사용한다면 +를 %2B로 인코딩 해야만 합니다.
bashcurl "http://localhost:8983/solr/techproducts/select?q=%2Belectronics%20%2Bmusic"
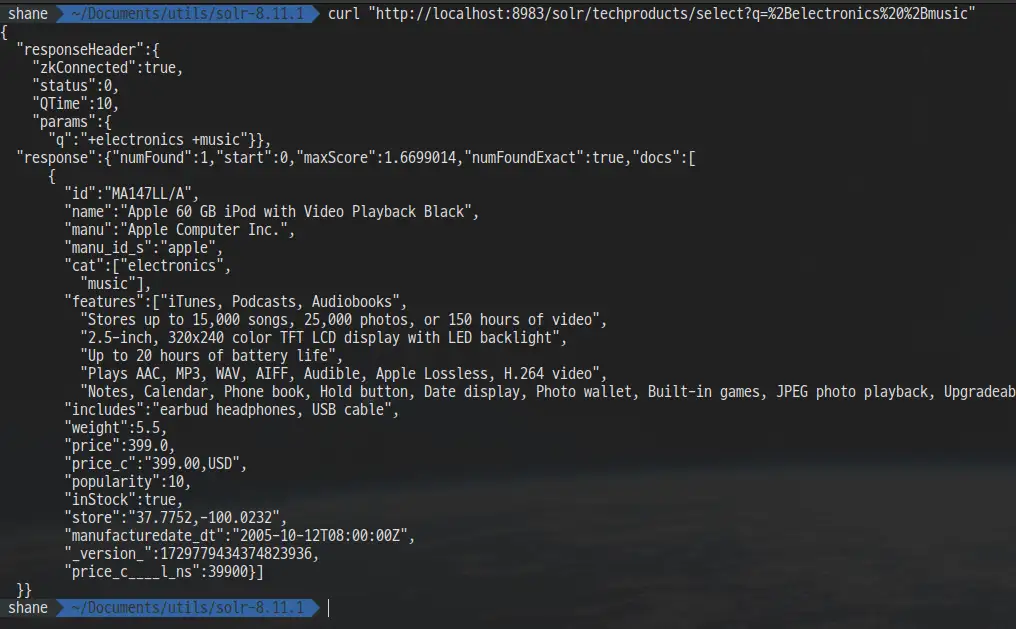
검색 결과가 딱 1개 나옵니다.
이번에는 electronics를 포함 하지만 music을 포함 하지 않는 검색 결과를 위해 +electonics -music을 쿼리 스트링에 작성 해 보겠습니다. 인코딩이 필요한 +와 다르게 -는 인코딩할 필요가 없습니다.
bashcurl "http://localhost:8983/solr/techproducts/select?q=%2Belectronics+-music"
13개의 검색 결과가 표시됩니다.
가장 많이 사용하는 검색 옵션들에 대해 간단하게만 알아 보았는데, 그 외 더 많은 검색 옵션들은 https://solr.apache.org/guide/8_11/searching.html 에서 확인 해 주세요.
지금까지 Solr가 어떻게 데이터를 색인하는지 그리고 기본적인 검색 쿼리를 작성하는 방법을 알아 보았습니다.
실습을 위해 만든 techproducts 컬렉션은 더이상 필요 하지 않기 때문에 삭제를 원한다면 아래의 명령어를 입력 해서 삭제 하실 수 있습니다.
bash
bin/solr delete -c techproducts
또한 Solr 를 종료하려면 아래의 명령어를 입력 하면 됩니다.
bash
bin/solr stop -all
Solr 시작 및 종료에 대한 더 자세한 문서는 https://solr.apache.org/guide/8_11/solr-control-script-reference.html 를 참고 해 주세요.
실습2. Schema 수정 및 Films 예제 색인
이번 실습에서는 이전에서 학습 한 내용에서 한발짝 더 나아가 Index Schema와 Solr의 강력한 Faceting(패싯) 기능을 활용 해 봅니다.
Solr 재시작
실습 1 까지 진행을 한 후에 컴퓨터를 종료했거나 solr를 종료 했다면 당황하지 않고 다시 실행을 해 줍니다.
첫번째 노드 실행
bash
./bin/solr start -c -p 8983 -s example/cloud/node1/solr
두번째 노드 실행
bash
./bin/solr start -c -p 7574 -s example/cloud/node2/solr -z localhost:9983
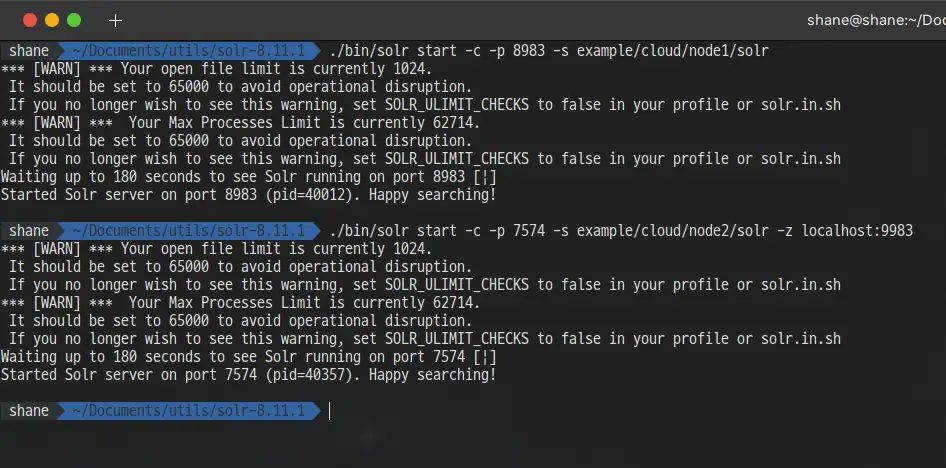
정상적으로 실행 되었습니다.
만약
solr.in.sh혹은solr.in.cmd에ZK_HOST를 정의 해 두면-z <zk 호스트>옵션을 생략 할 수도 있습니다.
새로운 컬렉션 생성
이번 실습에서는 완전히 새로운 데이터셋을 사용할 예정이기 때문에 이전에서 사용한 컬렉션을 재사용 하는 것 보다는 새로운 컬렉션을 생성하는게 좋습니다.
특히 Solr가 색인하는 과정에서 필드에 어떤 데이터 타입이 있을지 추측하는 field guessing 기능을 사용 할 것이기 때문에 새로운 컬렉션을 생성하도록 하겠습니다.
또한 field guessing 은 새로 들어오는 documents 의 새로운 필드들을 스키마에 새로운 필드로 자동 추가 하는데요, 이걸 Schemaless 라고 합니다.
해당 접근법의 장점과 한계에 대해서도 이번 실습을 통해 알아보아서 실제 어플리케이션에 적용시에 어떤걸 선택해야 할 지 판단 할 수 있도록 하겠습니다.
Solr에서의 스키마는 Field와 Field Type에 대해 Solr가 예측 하고 이해할 수 있도록 하는 XML 파일 입니다. Schema는 필드나 필드 타입명 뿐만 아니라 색인 되기 전 필드에 수행되어야 할 수정사항도 정의할 수 있습니다.
예를 들어
abc라고 입력 한 유저나ABC라고 입력 한 유저 둘 다ABC가 포함된 문서를 검색 결과로 받게 하기 위해서는 색인시 와 쿼리 수행시 모두지금 상황에서는 모두 소문자로 변경하는정규화 과정이 필요한데요 이런 규칙을 schema에 정의 합니다.이전에 언급 한 Copy Fields 뿐만 아니라, 와일드카드를 사용 해 (*_t 혹은 *_s 같은) 특정 필드 유형의 필드를 동적으로 생성하는 다이나믹 필드를 정의 할 수도 있습니다.
이러한 유형의 규칙 또한 스키마에 정의됩니다.
처음의 실습에서는 Solr를 실행 할 때에 미리 만들어져 있는 techproducts라는 이름의 configset을 사용 했었는데요, 이번에는 최소한의 스키마를 가지고 있는 configset을 사용해서 Solr가 데이터로 부터 어떤 필드들을 추가 해야 할지 알아내도록 해 보겠습니다.
이번에 색인 할 데이터는 영화에 관련되었습니다. films 라는 이름의 컬렉션을 _default configset을 사용해 생성 하도록 하겠습니다.
bash
bin/solr create -c films -s 2 -rf 2

configset을 따로 설정 하지 않으니 자동으로
_defaultconfigset이 선택되었습니다.
-s와 -rf 옵션은 각각 생성할 Shard와 Replica의 수를 의미합니다. 처음 실습 했던 것과 똑같이 각각 2개씩 생성 하였습니다.
_default configset을 프로덕션(상업) 목적에서 사용하기에는 추천하지 않는다고 경고문이 나오지만 우리는 튜토리얼을 진행 중이기 때문에 괜찮습니다. 해당 경고는 앞으로 설명할 한계 때문입니다.
아무튼 컬렉션이 생성 되었습니다. Admin UI에 가서 확인 해 보면
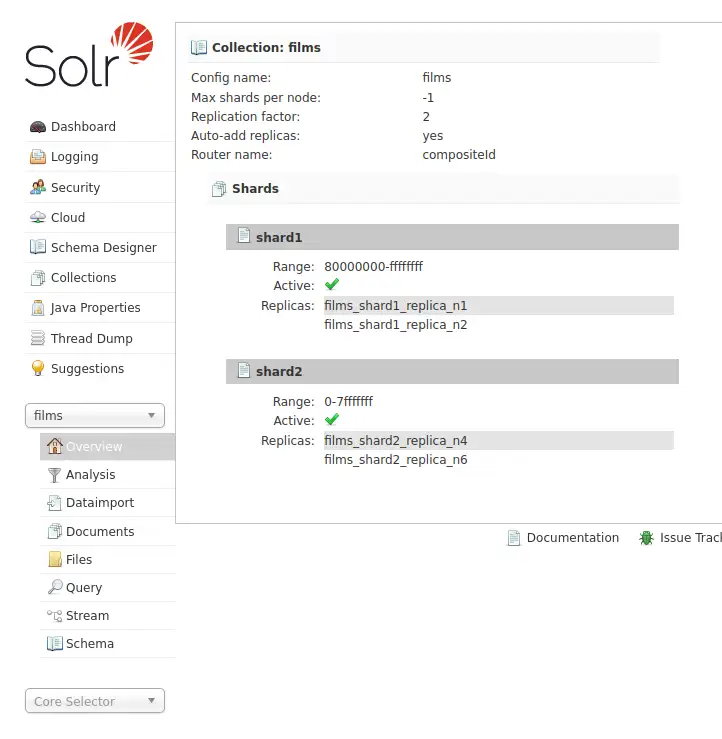
films 컬렉션이 준비 되었습니다.
Flims 데이터를 위한 Schemaless
_default configset 설정시 두가지 일이 일어나는데요
- 첫번째로 저희는 Solr Schema API를 통해서만 변경되도록 설정된
managed schema를 사용 하게 됩니다. 즉, 직접 수정 할 수 없기 때문에 어떤 소스로부터 어떤 수정이 왔는지 혼동할 필요가 없습니다. Solr Schema API가 필드나 필드타입 혹은 다른 스키마 룰을 수정 할 수 있게 해줍니다. - 두번째로
solrconfig.xml파일에 설정된field guessing을 사용하게 됩니다.
필드 추측은 Document를 색인 하기 전에 document에 있을 것으로 생각되는 모든 필드를 직접 정의하지 않고도 Solr를 바로 시작 할 수 있도록 해줍니다. 색인할 문서가 있을때 곧바로 Solr를 실행만 하면 필드들을 만들어 내기 때문에Schemaless라고 합니다.
설명만 보면 굉장히 보이지만, 분명한 한계가 있습니다. 그저 무작위 대입이라고 볼 수 있으며 만약 추측이 잘못되었다면 문서가 일단 색인 된 후에는 재색인을 하지 않는 이상은 수정이 꽤나 제한적입니다.
문서가 몇천건 정도만 있다면 사용 할 만 하지만 수백만건이 넘어간다거나 심지어는 더이상 원래의 데이터에 접근 할 수 없는 상황이라면 상황이 굉장히 심각해 질 수 있습니다.
이러한 이유로 Solr 커뮤니티에서는 schema를 직접 정의하지 않고 사용하는걸 권장하지 않습니다. Schemaless 기능을 학습을 위한 용도로 사용하는건 괜찮지만, 자동으로 생성된 스키마가 기대한 것과 일치하는지 그리고 쿼리가 원하는 대로 작동하는지를 항상 확인 해야 합니다.
좋은 소식은, Schemaless 기능을 미리 정의해둔 Schema와 섞어서 사용 할 수 있다는 것 입니다. Schema API를 사용해서 직접 컨트롤 하고 싶은 필드를 정의하고, 덜 중요하거나 테스트를 통해 잘 작동한다는 확신이 있는 필드들에 대해서는 Solr에 맡길 수 있습니다. 이번 실습에서도 이 방법을 사용 할 예정 입니다.
names 필드 생성
지금부터 색인 할 films 데이터는 각각의 영화가 몇개 안되는 필드만을 포함 하고 있습니다.
- ID
- director name(s)
- film name
- release date
- genre(s)
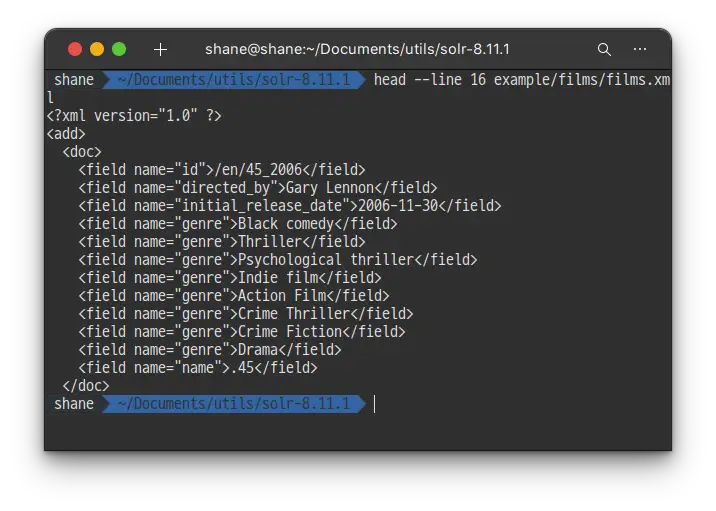
head --line 16 example/films/films.xml
exaple/films 폴더에 있는 예제 파일을 확인 해 보면 첫번째 필름의 이름이 .45 이며 2006년에 개봉했다는 사실을 확인 할 수 있습니다.
Solr는 record 상의 데이터를 토대로 field type을 추측하게 되는데 만약 이 데이터를 그냥 색인 한다면 Solr는 첫번째 영화 제목을 보고 필드 타입을 float 으로 결정 해 버립니다. 그래서 name이라는 필드가 FloatPointField라는 타입으로 자동 생성 되는데 이후로 들어오는 모든 데이터들은 이로인해 name에 float 값이 들어올 것을 기대하게 됩니다.
이건 저희가 원하는 동작이 아닙니다. 후에 뒤로가면 A mighty Wind 나 Chicken Run 같은 문자열로 된 제목들이 등장 하기 때문에 Solr가 name 필드를 float로 추측하게 가만 내버려둔다면 후에 제목을 색인 하는 과정에서 인덱싱 실패 에러를 맞이 하게 됩니다.
여기에서 우리가 할 수 있는건 Solr가 항상 제목을 문자열로 해석 할 수 있도록 name 필드를 색인 전에 미리 설정 해 주는 것 입니다. Schema API를 활용해 본 설정을 하면 아래와 같습니다.
bashcurl -X POST -H 'Content-type:application/json' --data-binary '{"add-field": {"name":"name", "type":"text_general", "multiValued":false, "stored":true}}' http://localhost:8983/solr/films/schema
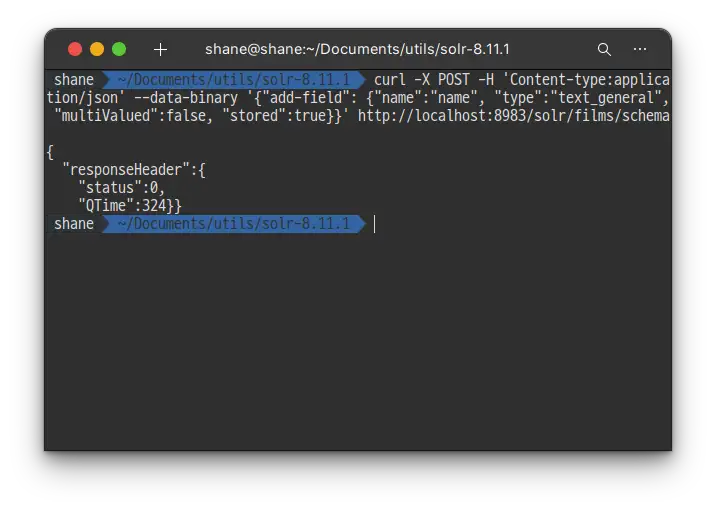
실행 결과
위의 명령은 Schema API를 활용해 name이라는 필드 명이 text_general 필드 타입을 갖도록 명시합니다. 필드 타입은 여러개의 값을 가질 수는 없지만, 저장해 둘 수 있기 때문에 쿼리를 통해 조회 할 수도 있습니다.
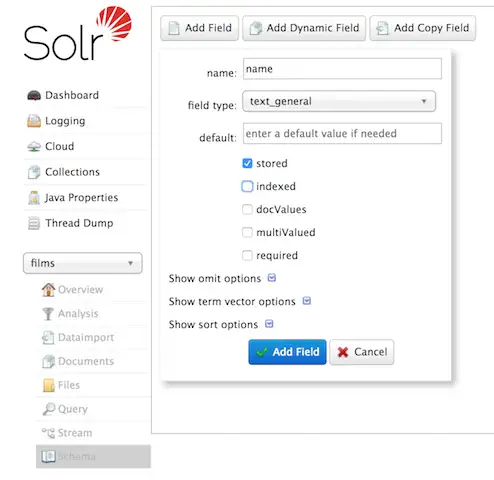
Admin UI를 통해 필드를 생성 할 수도 있지만, 필드에 설정 할 수 있는 범위에 제한이 있습니다. 물론 지금 필요한 필드명과 필드 타입 설정 정도는 가능합니다.
https://solr.apache.org/guide/8_11/solr-tutorial.html#exercise-2
catchall Copy Field 생성
색인을 시작 하기 전에 해야 할 일이 하나 남았습니다.
첫번째 실습에서는 저희가 사용한 설정 파일이 필드들을 text 필드에 복사하도록 되어있었고 해당 필드가 기본 필드로 설정 되어 있기 때문에, 검색 쿼리를 할 때 검색 할 필드를 굳이 특정하지 않아도 검색이 문제 없이 잘 수행 되었었습니다. 하지만 지금 저희가 사용할 설정에는 그런 룰이 아직 없기 때문에 모든 쿼리를 대상으로 검색 할 필드를 선언 해 주어야 합니다.
그 대신에 모든 필드의 모든 데이터를 가져와 _text라는 필드에 인덱싱 하는 copy field를 정의해 catchall field를 설정 할 수도 있습니다.
이때도 Admin UI 혹은 Schema API 둘 중 아무거나 사용 해 설정 할 수 있습니다.
Command Line
bashcurl -X POST -H 'Content-type:application/json' --data-binary '{"add-copy-field" : {"source":"*","dest":"_text_"}}' http://localhost:8983/solr/films/schema
Admin UI
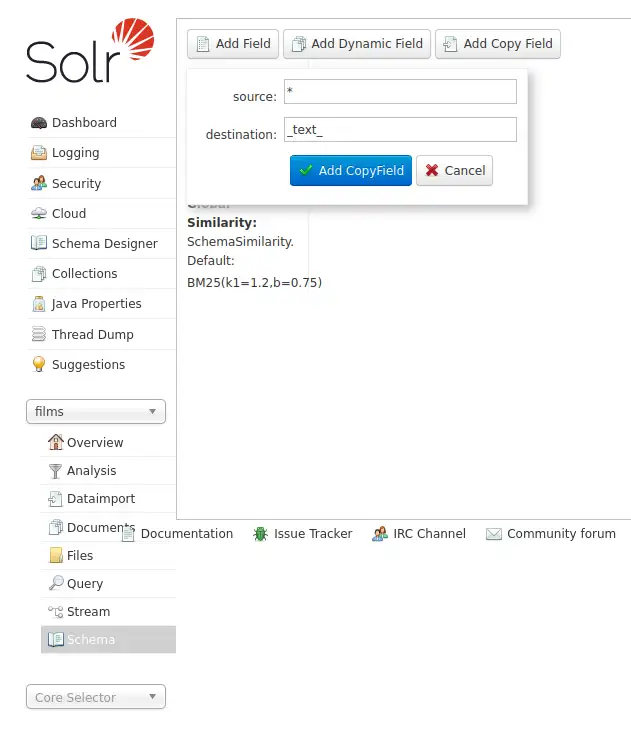
Schema > Add Copy Field 를 클릭 후 source 에는
*을, destination 에는_text_를 입력 합니다.
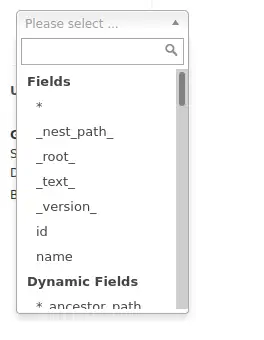
설정 후에 field 목록에
_text_가 추가 된 게 확인 됩니다.
이 설정을 통해 모든 필드의 데이터가 _text 필드에 복사됩니다. 이 경우에는 Solr가 모든 색인을 두번씩 하기 때문에 색인이 느려지고 색인 크기가 커지게 됩니다. 그래서 프로덕션에서 이렇게 설정하는 건 무리가 있으므로 그때는 복사가 꼭 필요하다고 여겨지는 필드만을 카피하도록 해 주어야 합니다.
이제 데이터를 색인 할 준비가 모두 끝났습니다.
Sample Film 데이터 색인
저희가 색인 할 films 데이터는 solr 폴더의 example/films 경로에 있습니다. JSON, XML, CSV 세가지 포맷으로 제공되며 셋중 하나의 포맷을 선택 해 films 컬렉션에 색인 해 주면 됩니다.
JSON 파일을 색인 해 보도록 하겠습니다.
Linux/Mac
bash
bin/post -c films example/films/films.json
-c 옵션은 컬렉션을 지정해주는 옵션 입니다. 파일이 있는 폴더명만 입력 해도 되지만, 색인 하고자 하는 파일의 포맷을 정확히 알고 있기 때문에 정확한 파일명과 포맷을 지정해주는게 효율적입니다.
Windows
bash
C:\solr-8.11.0> java -jar -Dc=films -Dauto example\exampledocs\post.jar example\films\*.json
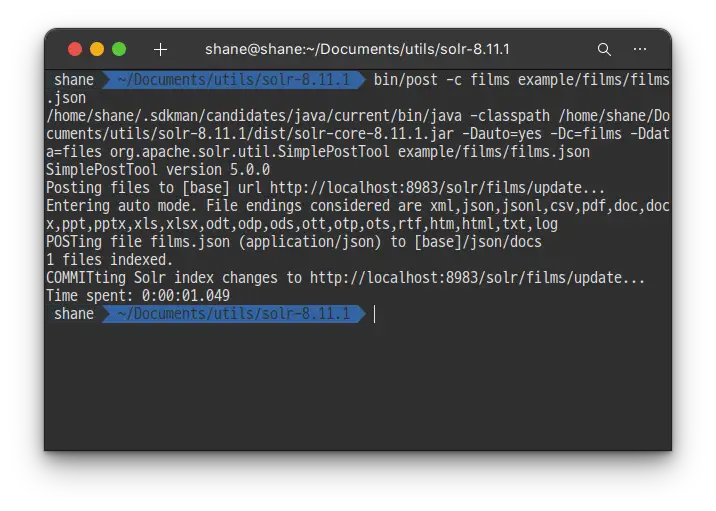
1초 만에 색인이 완료 되었습니다.
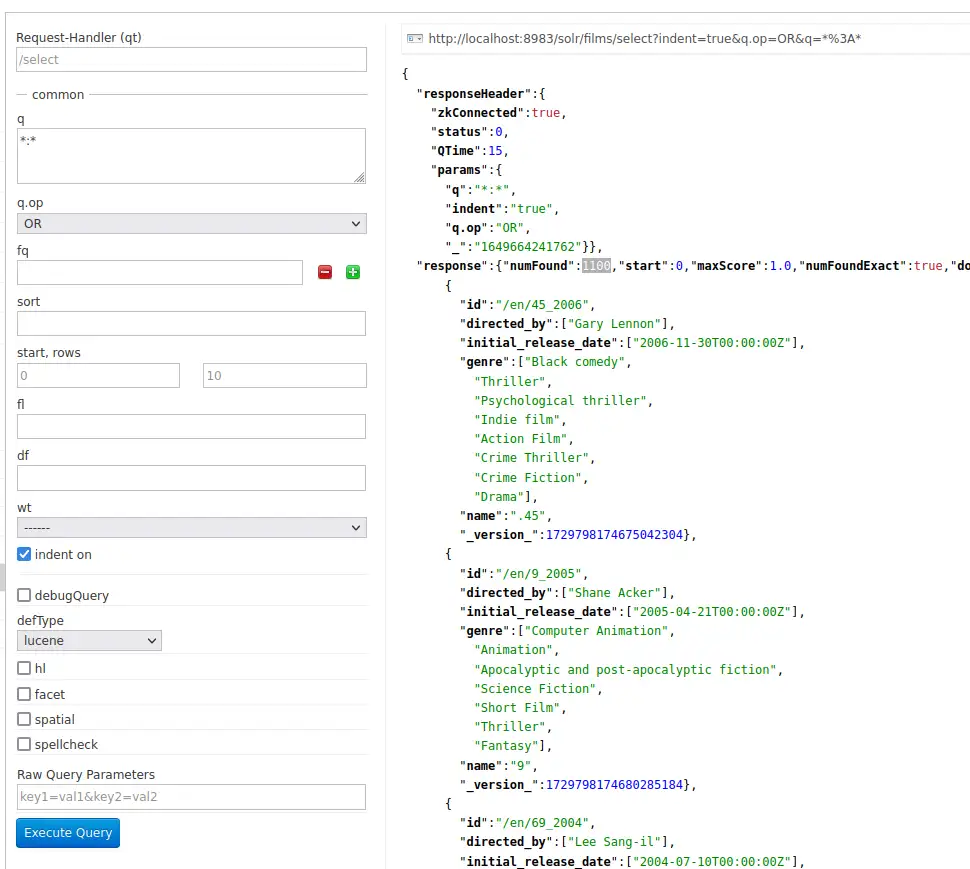
이제 Admin UI의 flims 컬렉션으로 와서 *:* 쿼리를 실행 해 보면 총 1100개의 쿼리 결과가 있다고 나옵니다.
이제는 아까 설정한 catchall 필드가 잘 동작하는지를 확인 하기 위해 q에 comedy를 입력 해 검색 해 보겠습니다.
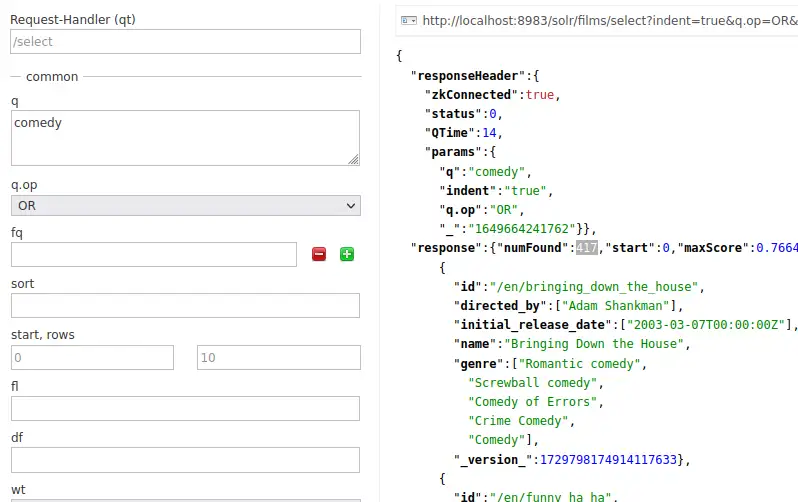
검색 결과가 417개 있다고 나옵니다. 물론 rows가 기본 10으로 되어 있기 때문에 10개까지만 표시됩니다.
Faceting
Solr의 가장 유명한 기능 중 하나를 꼽으라면 단연 faceting 인데요. Faceting을 사용하면 검색 결과를 몇개의 subsets(혹은 buckets or categories)로 분류하거나 각각 subset별 카운트 제공 등이 가능합니다.
faceting의 타입들의 예는 다음과 같습니다.
- 필드 값
- 숫자 혹은 날짜 범위
- 피봇(결정 트리)
- 임의 쿼리 패싯
Field Facets
검색 결과를 제공 할 뿐 아니라 Solr 쿼리는 모든 결과에서 특정 value를 포함하는 document들의 수를 반환할 수도 있습니다. admin UI 쿼리탭에서 facet 체크박스를 클릭 하면 facet과 관련된 옵션들이 보입니다.
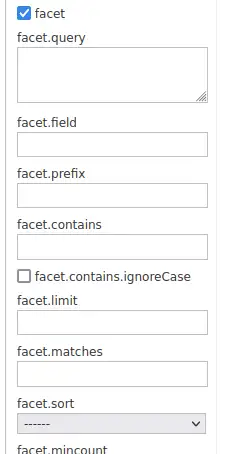
체크를 해야 등장하는 facet 으로 시작하는 옵션들
모든 documentsq=*:* 에서 facet 카운트를 확인 해 보기 위해 facet=true로 설정 후 facet 하고 싶은 필드를 facet.field 파라미터를 통해 설정 해 줍니다. 만약 도큐먼트 컨텐츠가 필요 없고 facets 만을 원한다면 rows=0 으로 설정 해 줄 수도 있습니다.
이제 장르별 facet 을 확인 해 보겠습니다.
bashcurl "http://localhost:8983/solr/films/select?q=*:*&rows=0&facet=true&facet.field=genre_str"
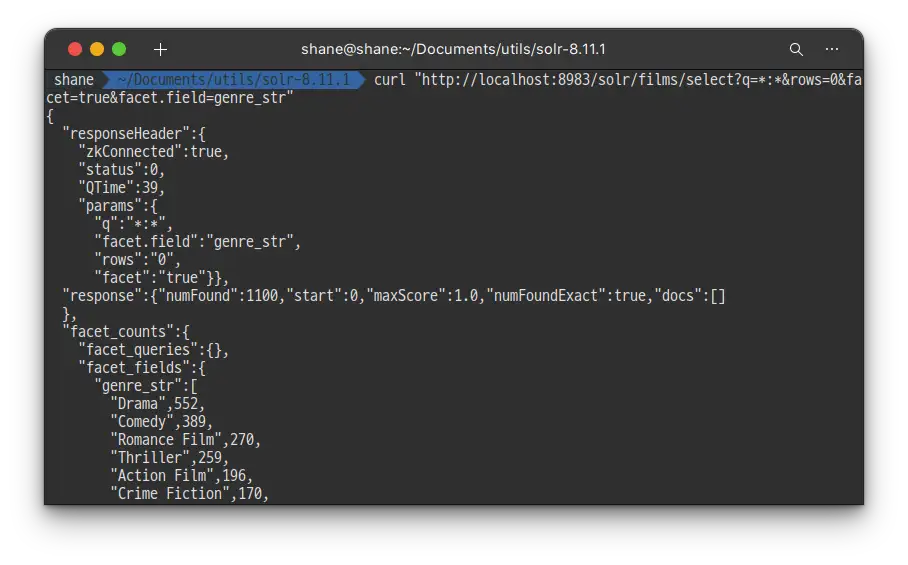
실행 결과
드라마 552개, 코미디 389개 등등 영화 장르별로 카운트 되었습니다.
facet.mincount 파라미터를 설정 하면 특정 갯수 이상이 포함된 facet만을 조회 할 수도 있습니다.
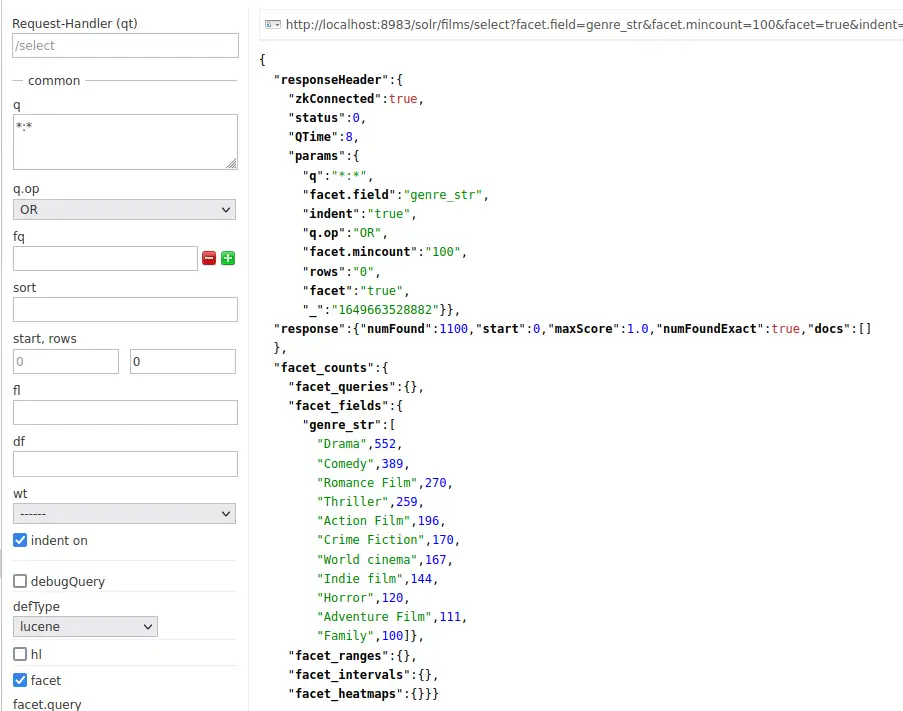
http://localhost:8983/solr/films/select?facet.field=genre_str&facet.mincount=100&facet=true&indent=true&q.op=OR&q=*:*&rows=0결과가 100개 이상인 경우만 조회되고 있습니다.
Range Facets
날짜나 숫자는 각각 하나씩 값을 나누는 것 보다는 특정 범위별로 파티션을 나누는게 도움이 되는데요. 처음 실습했던 techproducts 데이터에서 price를 범위별로 나누면 아래와 같은 결과가 나옵니다.

range facet의 흔한 예
Films 데이터에는 영화의 개봉일이 있기 때문에 날짜 범위별로 facet 할 수 있습니다. 또다른 range facet의 흔한 예 인데요, 아쉽게도 Solr Admin UI 자체적으로는 range facet 옵션을 제공하지 않습니다.
bashcurl 'http://localhost:8983/solr/films/select?q=*:*&rows=0'\ '&facet=true'\ '&facet.range=initial_release_date'\ '&facet.range.start=NOW-20YEAR'\ '&facet.range.end=NOW'\ '&facet.range.gap=%2B1YEAR'
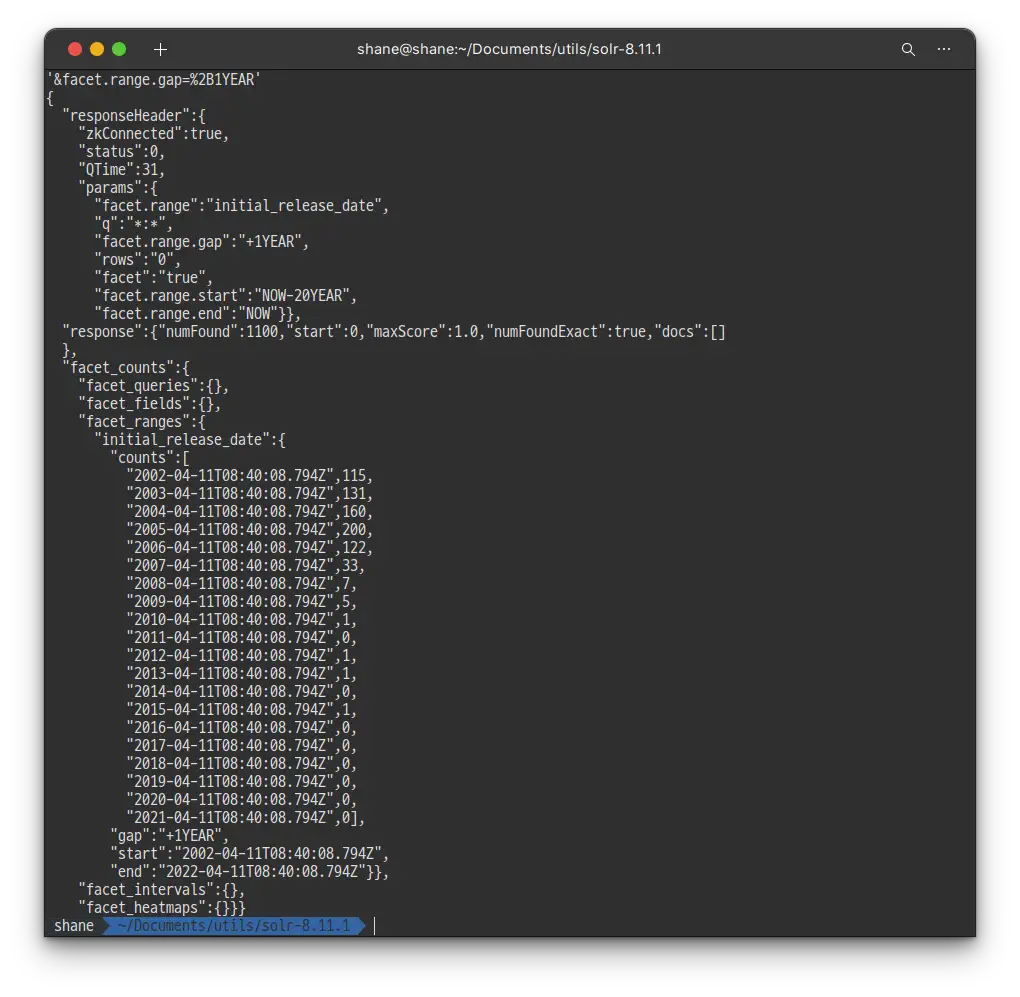
쿼리실행 결과, 20년 전 부터 시작해서 오늘까지를 1년 단위로 나누어 각 기간별 갯수를 카운트 해 주었습니다.
Pivot Facets
또 다른 faceting 타입으로는 결정 트리(Decision trees)라고 알려진 Pivot facets 입니다.
Pivot facets은 2개 혹은 그 이상의 필드들을 가능한 모든 조합에 대해 중첩 하는데요, Pivot facets은 Films 데이터를 활용해서 Drama 카테고리에 있는 영화 중 특정 감독에 의해 촬영된 영화가 몇개인지를 알아낼 수 있습니다.
bashcurl "http://localhost:8983/solr/films/select?q=*:*&rows=0&facet=on&facet.pivot=genre_str,directed_by_str"
실행 했다가 쿼리 결과가 너무 길어 파일로 빼 보았습니다.
bashcurl "http://localhost:8983/solr/films/select?q=*:*&rows=0&facet=on&facet.pivot=genre_str,directed_by_str" > queryresult.txt
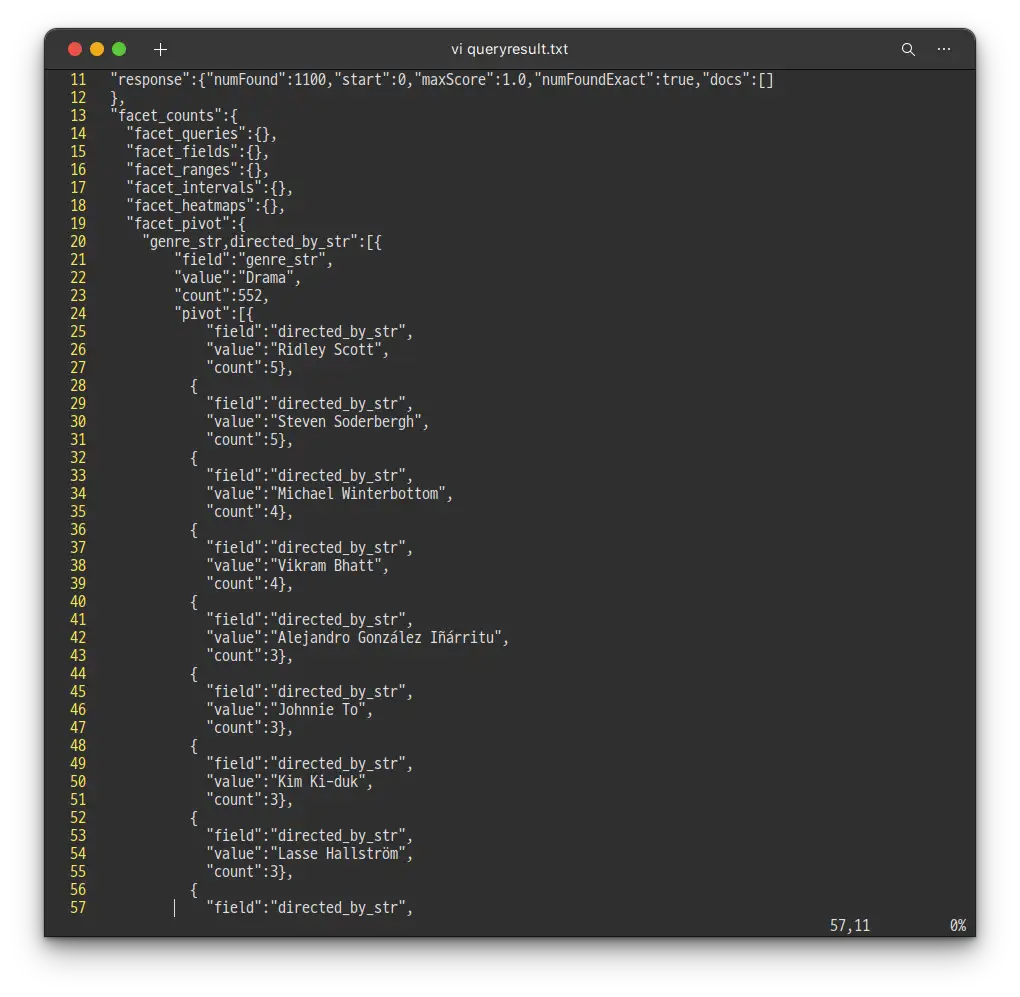
Drama 장르에 522개의 영화가 있고, 각각의 감독 별로 몇개의 영화가 있는지 카운트 되었습니다.
두번째 실습을 통해 Solr가 어떻게 데이터들을 정돈 하고 색인 하는지 알아 보았습니다. 또한, Schema API를 활용해 schema file을 조작 해 보기도 했습니다.
마지막에는 rance facets 이나 pivot facets과 같은 Solr의 훌륭한 Facets 기능을 실습 해 보았는데요, 저희는 단지 Solr에서 사용 할 수 있는 옵션들중 극히 일부만 사용해 보았지만 어느정도 감을 익힐 수 있었습니다.
위에서 했던 것처럼 지금 사용한 컬렉션도 지우며 두번쨰 실습을 마치겠습니다.
bash
bin/solr delete -c films
위에서 techproducts를 안지웠다면 같이 지우도록 하겠습니다.
bash
bin/solr delete -c techproducts
실습3. 나만의 데이터 색인
마지막 실습에서는 각자 원하는 데이터셋을 색인 해 보도록 하겠습니다. 하드디스크에 있는 파일이 될 수도 있고, 이전에 작업했던 데이터들일 수도 있고 혹은 프로덕션에서 사용 하고 싶은 데이터들 일 수도 있겠네요.
이번 실습을 통해 이런 고민들을 하게 되는데요
- 어떤 종류의 데이터들을 색인할까?
- 데이터 색인을 위해 Solr에서 어떤 준비를 해야 할까? - 위에서 names 필드를 미리 만든 것 같은
- 사용자들에게 어떤 검색 옵션을 제공할까?
- 기대한대로 작동한다는 확신을 위해 어느정도의 테스트를 진행해야 할까?
나만의 컬렉션 생성
시작하기 전에, 새로운 컬렉션을 생성하겠습니다. 하고 싶은 이름을 지으시면 되는데 localDocs라는 이름으로 이름을 짓는다면 아래와 같겠습니다. 아래 예제의 이름을 지우고 원하는 이름으로 작성해주세요.
bash
./bin/solr create -c localDocs -s 2 -rf 2
위의 실습 2 에서 이미 학습 했던 것처럼, 위의 명령으로 컬렉션을 생성하면 _default configset을 사용하게 되며 모든 schemaless 기능들이 제공됩니다. 이전에서 이미 경험 했던 것처럼 이 경우에는 데이터를 색인 할 때에 많은 문제를 발생 하기 때문에 적절한 schema를 만들어 내기 위해서는 인덱싱 작업을 여러번 반복 하셔야 합니다.
색인하는 다양한 방법
Solr는 데이터 인덱싱을 위해 다양한 방법들을 제공하고 있는데요, 각각 본인의 시스템에서 적절한 방법이라고 판단되는걸 골라 접근 하시면 됩니다.
로컬 파일을 bin/post 를 활용해 색인
파일데이터들을 가지고 있다면, /bin/post에 있는 Post Tool 을 사용해서 특정 폴더의 파일들을 색인 할 수 있습니다. 첫번째 두번째 실습에서 해봤던 것처럼요.
실습에서는 JSON, XML, CSV 파일만을 다루어 봤지만 사실 Post Tool은 그 외에도 HTML, PDF 뿐만 아니라 MS Office 포맷, Plain text 등 다양한 파일들을 다룰 수 있습니다.
Documents 폴더에 색인할 파일들이 있다고 가정하고, 방금 위에서 만든 localDocs 컬렉션에 색인 한다면
bash
./bin/post -c localDocs ~/Documents
명령어를 통해 진행 할 수 있습니다.
아마 로컬 파일들의 색인을 시도 할 때 오류가 제법 발생 할 텐데요. field guessing 기능이나 혹은 지원되지 않는 파일 타입을 사용하기 때문일 가능성이 높습니다.
예제에서 몇번 강조한 것처럼 컨텐츠를 색인 하기 위해서는 데이터를 충분히 이해 하고 시행착오와 에러들을 경험 하며 Solr 색인에 대한 계획을 세울 수 있게 되어야 합니다.
DataImportHandler
Solr는 DataImportHandler(DIH) 라고 불리는 툴을 내장하고 있는데요, 이를 활용하면 데이터베이스나(jdbc driver 필요) 메일 서버, 혹은 다른 데이터 소스들에 접근 할 수 있습니다.
피드나 Gmail, 혹은 작은 HSQL 데이터베이스를 이용하는 예제가 있는데요
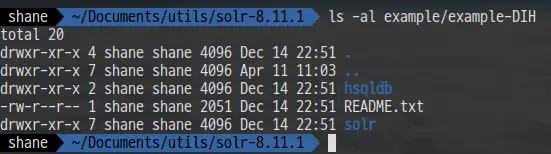
example/example-DIH 폴더의 README.txt 파일에 이 도구를 사용 하는 방법이 자세히 작성 되어 있습니다.
Solrj
Solrj는 자바 기반의 Solr와의 통신을 지원하는 클라이언트 입니다. JVM 기반의 언어를 사용한다면 Solr를 활용 하면 되고 다른 프로그래밍 언어를 이용해 Solr를 사용하고 싶다면 링크를 확인 해 주세요.

Documents Screen
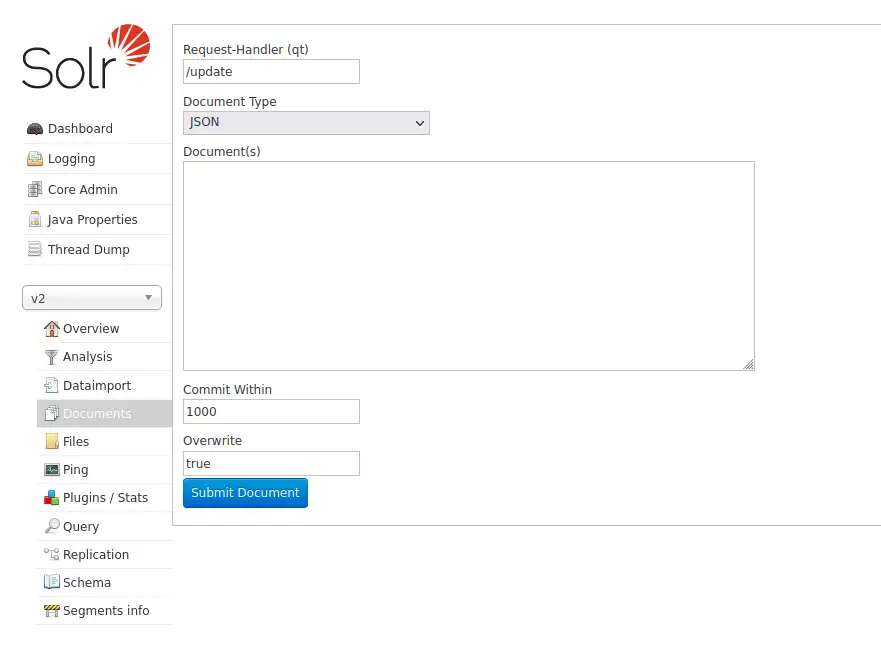
Admin UI의 Document 탭에 색인하고자 하는 문서를 복사해 붙여 넣거나 혹은 Document Type에서 Document Builder 를 선택하면 한번에 하나씩의 필드를 직접 색인 할 수도 있습니다.
데이터 업데이트
이번 튜토리얼에서 컨텐츠를 한번 이상 색인 했다고 하더라도 어떠한 중복 데이터도 생기지 않았다는걸 눈치 채셨을텐데요. 예제에서 사용된 Solr schema (managed-schema 혹은 schema.xml파일) 가 id라는 특정한 유니크키를 가지고 있기 때문입니다. 이미 존재하는 문서와 같은 유니크키로 여러번 POST 추가 요청을 보낸다면 매번 추가 대신 기존 문서를 업데이트 해 줍니다.
이런 사실은 Solr Admin UI의 Core Admin 탭에 작성된 numDocs와 maxDocs를 통해 쉽게 확인 가능합니다.
numDocs는 색인 된 검색 가능한 document의 수를 나타냅니다. (몇몇 파일은 하나 이상의 document를 포함 할 수 있기 때문에 파일의 수보다는 보통 많습니다)
maxDoc 값은 더 큰데요 논리적으로는 이미 삭제 되었지만 아직 물리적으로 삭제되지 않은 색인들이 몇몇 남아있기 때문입니다. 같은 파일을 계속 해서 추가 하다고 해도 numDocs는 늘어나지 않는데요 새로운 document가 계속 기존의 document를 대신하기 때문입니다.
몇몇 샘플 데이터 파일을 열고, 그중 몇 데이터를 편집 하고 PostTool을 다시 실행 시켜 본다면 모든 변경 사항이 이후의 검색에서는 반영되어 있는 것을 확인 하실 수 있습니다.
데이터 삭제
적절한 schema 를 얻어내기 위해 색인 과정을 매번 반복하며 컬렉션의 데이터를 깨끗하게 비우고 싶을텐데요..
하지만 document를 삭제하는건 필드 선언에 어떠한 변경도 주지 않습니다. 그렇기 때문에 필요에 의해 몇몇 필드를 변경 했다면 데이터도 재 색인 할 필요가 있습니다.
특정 문서의 유니크 키 필드 값을 특정 하거나 혹은 여러개의 document 를 선택하는 쿼리로 삭제 할 문서를 정하고, update URL에 삭제 커맨드를 POST 요청해 삭제 할 수 있습니다.
혹은 요청을 적절하게 잘 구성한다면 bin/post를 사용해서도 문서를 삭제 할 수 있습니다.
특정 document를 삭제 한다면 아래의 커맨드를 입력 합니다.
bashbin/post -c localDocs -d "<delete><id>SP2514N</id></delete>"
모든 document를 삭제하려면 delete-by-query 커맨드를 사용 할 수 있습니다.
bashbin/post -c localDocs -d "<delete><query>*:*</query></delete>"
위의 쿼리를 살짝 수정해서, 조건에 맞는 문서들만 삭제 할 수도 있습니다.
공간 쿼리
Solr는 정교한 지형 검색도 제공합니다. 특정 위치로 부터 특정 거리 내의 지역을 검색하거나, 거리 순으로 정렬하거나 혹은 심지어 거리에 따른 검색 결과 Boosting(상위 노출) 옵션도 제공합니다.
실습 1에서 연습했던 techproducts 문서에 위치 정보가 포함 되어 있기 때문에 샌프란시스코에서 10킬로 이내에 있는 아이팟을 검색하는게 가능합니다.
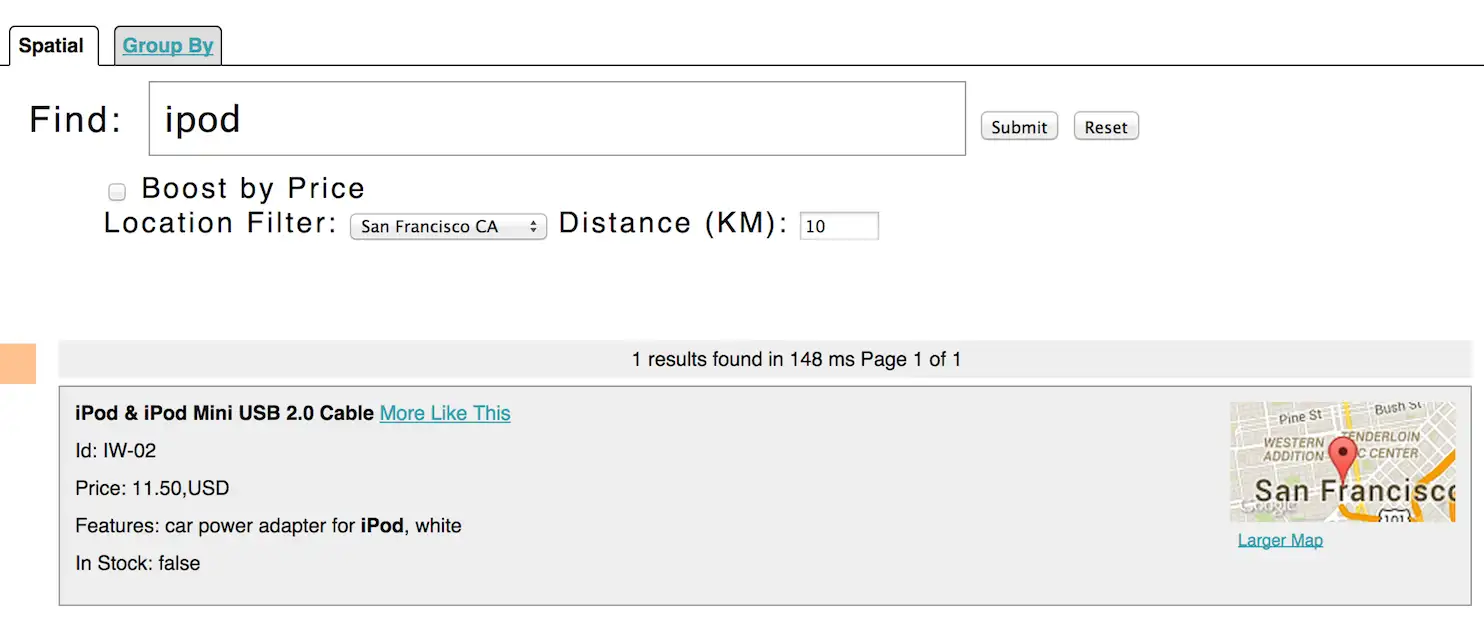
https://solr.apache.org/guide/8_11/solr-tutorial.html#exercise-3
공간 쿼리에 대한 더 자세한 내용은 링크 를 참고해주세요.
마치며
- Solr를 클라우드 모드에서 2개의 노드와 2개의 컬렉션, 그리고 샤드와 레플리카를 포함해 실행
- 몇몇 파일 타입들을 색인
- Schema API를 활용해 schema 편집
- Admin 콘솔에서 쿼리 인터페이스를 사용 해 보고 쿼리 결과 확인
이번 튜토리얼을 진행하며 위에 나열한 일들을 해 보았습니다.
정말 간단하고 필수적인 내용만 진행해 보았는데도 양이 어마어마 했는데요, Solr에 대해 큰틀에서의 이해가 되기 때문에 충분히 가치 있는 시간이었다고 생각합니다.
튜토리얼에서 학습한 내용이 실무에서 각자의 검색엔진 구축에 도움이 되었으면 좋겠습니다.
마지막으로 지금까지 실습한 내용을 모두 초기화 시키는 명령어를 남기겠습니다. 수고하셨습니다.
bashbin/solr stop -all ; rm -Rf example/cloud/
'Data > Search Engine' 카테고리의 다른 글
| docker로 elastic search 띄우기 (0) | 2021.11.25 |
|---|---|
| docker-compose 이용해 ELK Stack 구축하기 (0) | 2021.09.20 |
| Java 에서 Elastic Search 사용하기3. - 간단 검색하기 (1) | 2021.06.08 |
| Java 에서 Elastic Search 사용하기 - 2. Post Request (Create) (0) | 2021.06.08 |
| Java 에서 Elastic Search 사용하기 - 1. Get Request (0) | 2021.06.07 |