Intro
Heritrix는 웹 아카이빙을 위해 만들어진 웹 크롤러입니다. 2004년 미국의 Internet Archive 의해 최초 공개되었으며, 자바로 작성된 오픈소스입니다. 주요 인터페이스는 웹 브라우저를 사용하여 접근할 수 있으며, 크롤링을 시작하는 데 커맨드 라인으로도 조작할 수 있습니다. 또한, robots.txt 규칙을 존중합니다.
전체 소스코드는 https://github.com/internetarchive/heritrix3 에서 확인할 수 있습니다.
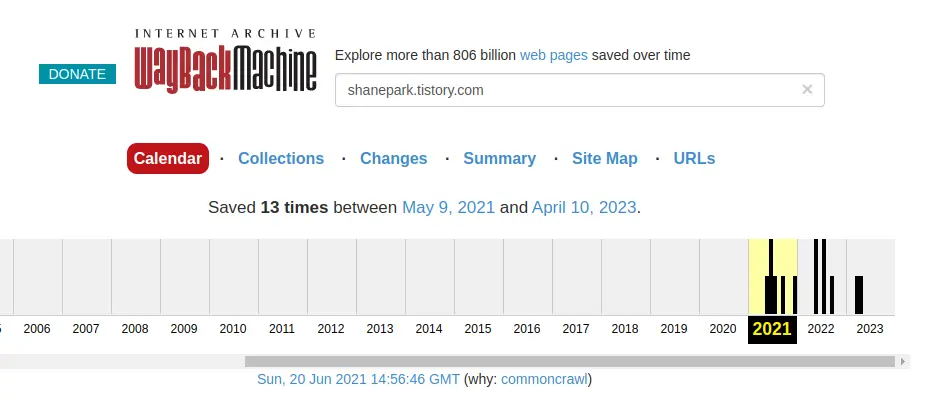
Internet Archive에서 아카이브 하는 사이트가 얼마나 많은지, 무려 8,060억개 이상의 웹 페이지를 조회할 수 있다고 합니다.
궁금해서 제 블로그 주소를 입력 해서 확인을 해 보았더니 아래 보이는 것 처럼 처음 작성하기 시작한 2021년 부터의 아카이브 기록이 조회되었습니다.
설치
환경에 따라 생기는 변수를 최소화 하기 위해 Docker 환경 위에 설치하도록 하겠습니다.
8443 포트를 바인딩하고, 컨테이너 이름은 heritrix로, 그리고 유저명과 비밀번호를 admin으로 생성합니다. /opt/heritrix/jobs 폴더는 새로 jobs 폴더를 생성해서 볼륨설정을 통해 쉽게 관리할 수 있습니다.
mkdir jobs
docker run --init -d -p 8443:8443 \
--name heritrix \
-e "USERNAME=admin" \
-e "PASSWORD=admin" \
-v $(pwd)/jobs:/opt/heritrix/jobs iipc/heritrix명령어를 실행 하고 컨테이너가 잘 작동하는 것을 확인 합니다.
기본 메모리 limit은 256MB 인데, 더 늘리고 싶다면 -e "JAVA_OPTS=-Xmx1024m" 처럼 메모리 옵션을 줄 수도 있습니다.
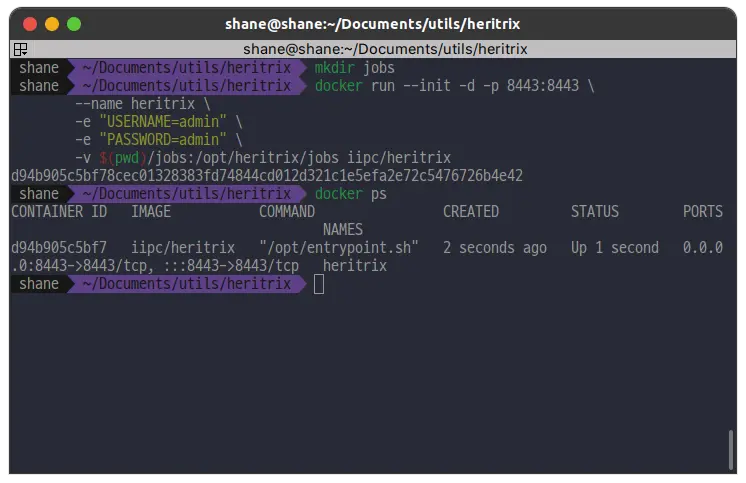
컨테이너가 동작중
이제 브라우저를 켜고 접속해봅니다. https://localhost:8443에 접속합니다.
그러면 아래 보이는 것 처럼
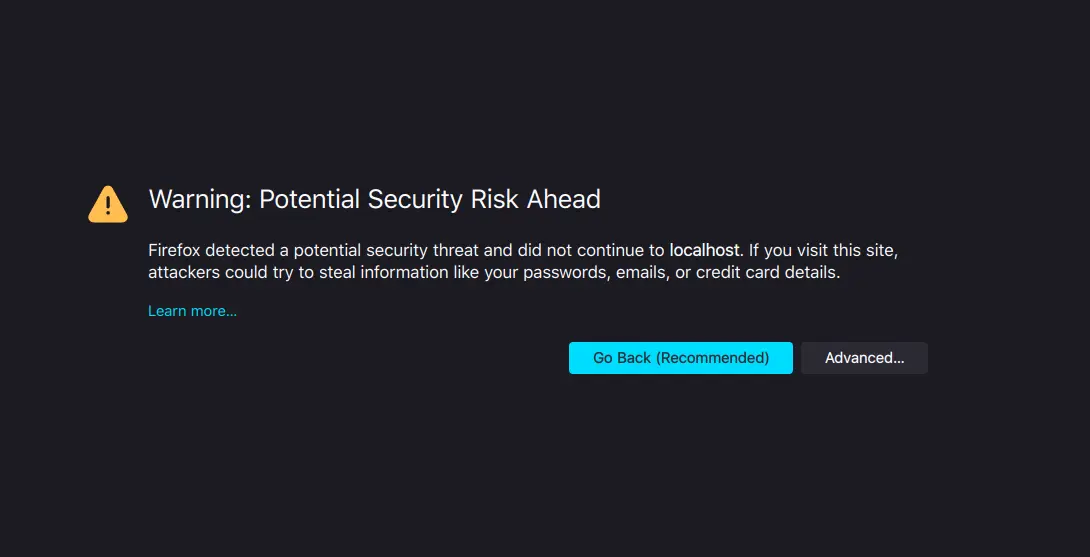
Firefox
경고가 나오는데요, localhost를 https 로 연결을 시도했기 때문입니다. Advanced 를 누르고, Accept the Risk and Continue를 클릭 해서 무시하고 진행 하면 됩니다.
크롬에서는 아래 보이는 것 처럼 Proceed to localhost(unsafe) 를 클릭 하면 됩니다.
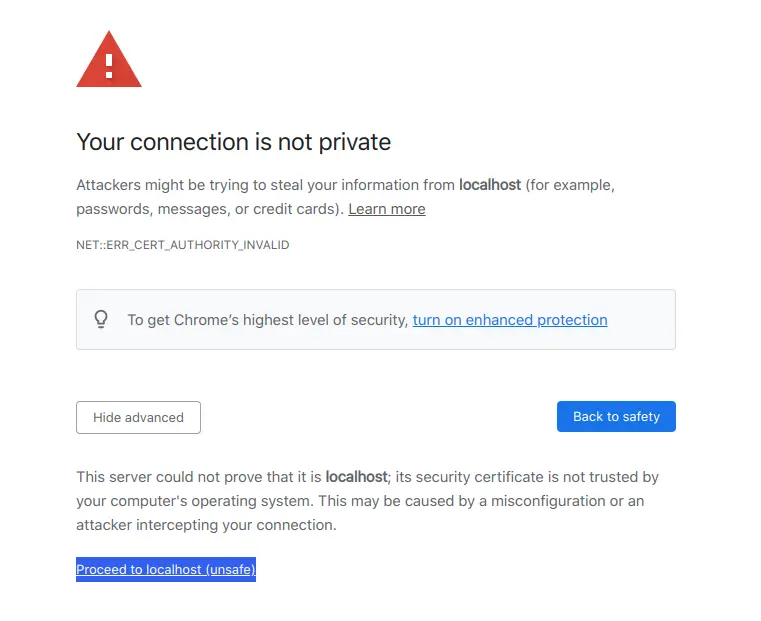
Chrome
그러면 이번에는 로그인을 하라고 나오는데요, 컨테이너를 띄울 때 작성한 admin/admin 을 입력 합니다.
Username 과 Password를 입력하고
Sign in을 합니다.
그러면 아래 보이는 것 처럼 메인 화면이 등장합니다. 이렇게 하면 설치는 손쉽게 끝이 납니다.
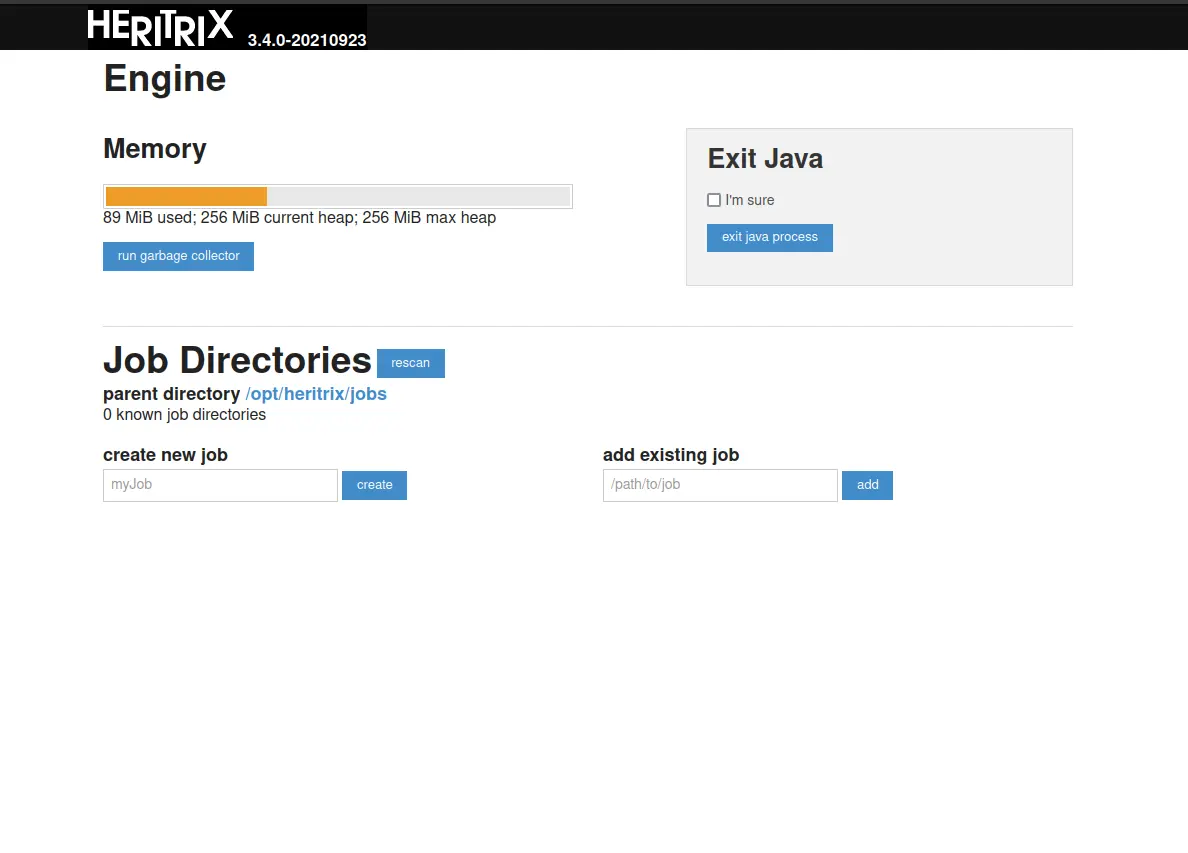
크롤링
Job 등록
크롤링을 위해서는 job 등록이 필요합니다. 하단의 create new job에 있는 인풋 태그에 원하는 job 이름을 입력 하고, create 버튼을 눌러줍니다.
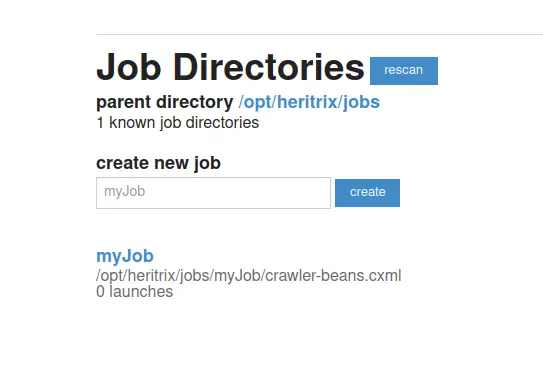
그러면 위에 보이는 것 처럼, myJob이 /opt/heritrix/jobs/myJob/crawler-beans.cxml 에 생깁니다.
제목을 클릭해서 들어가줍니다.
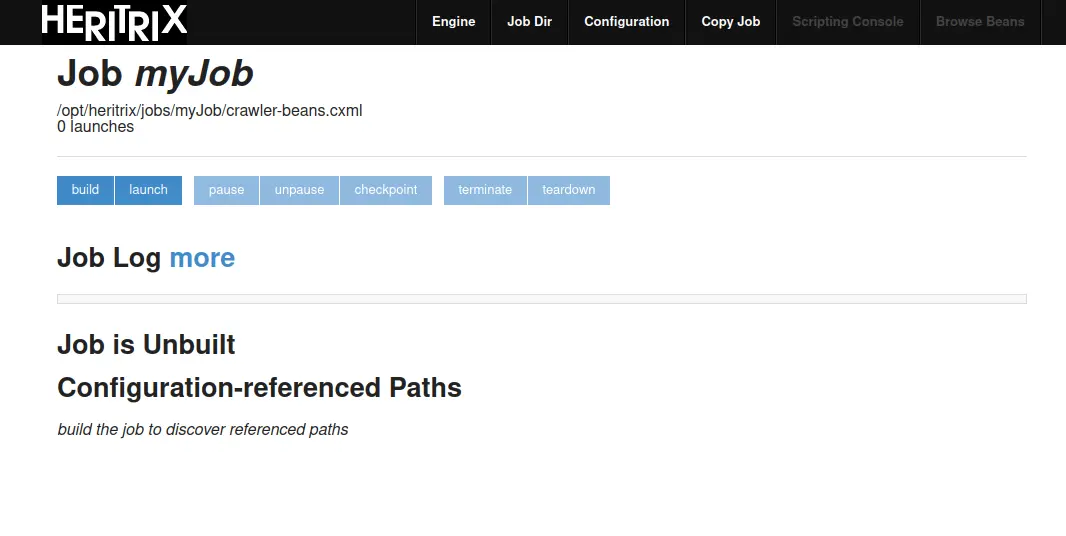
이제 우측 상단 세번째에 있는 Configuration을 클릭 해서 설정을 변경해 주어야합니다.
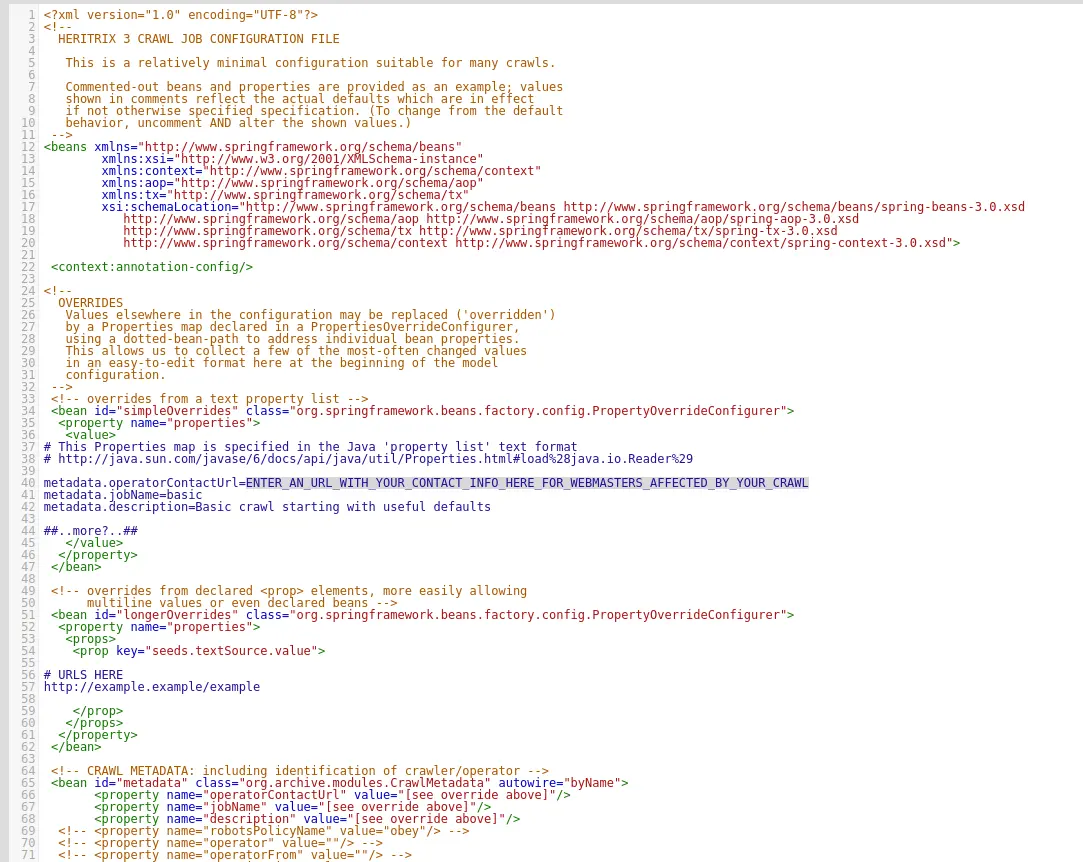
첫번째로는, 40번 라인에 있는 metadata.operatorContactUrl 속성을 변경해주어야 합니다.
크롤링을 할때 기록을 남겨서 혹시 해당 사이트의 주인이 연락할 일이 있을 경우에 쓰인다고 합니다.
그리고 두번째로는, 51번 라인에서 77번 라인 사이에 있는 빈 설정을 변경해줍니다. URLS HERE라고 주석되있는 곳 아래에 있는 예제 URL을 크롤링 할 URL로 변경 해 주면 됩니다.
모두 입력한 후에는 좌측 하단의 Save changes 버튼을 눌러 저장하고 뒤로가기를 눌러 나와줍니다.
이제는 Build 버튼을 눌러주면 job 설정을 검증 하고 메모리에 올립니다. 설정 파일에 문제가 있다면 빌드에 실패 하고, Job Log에 관련 에러 메시지가 표시됩니다.
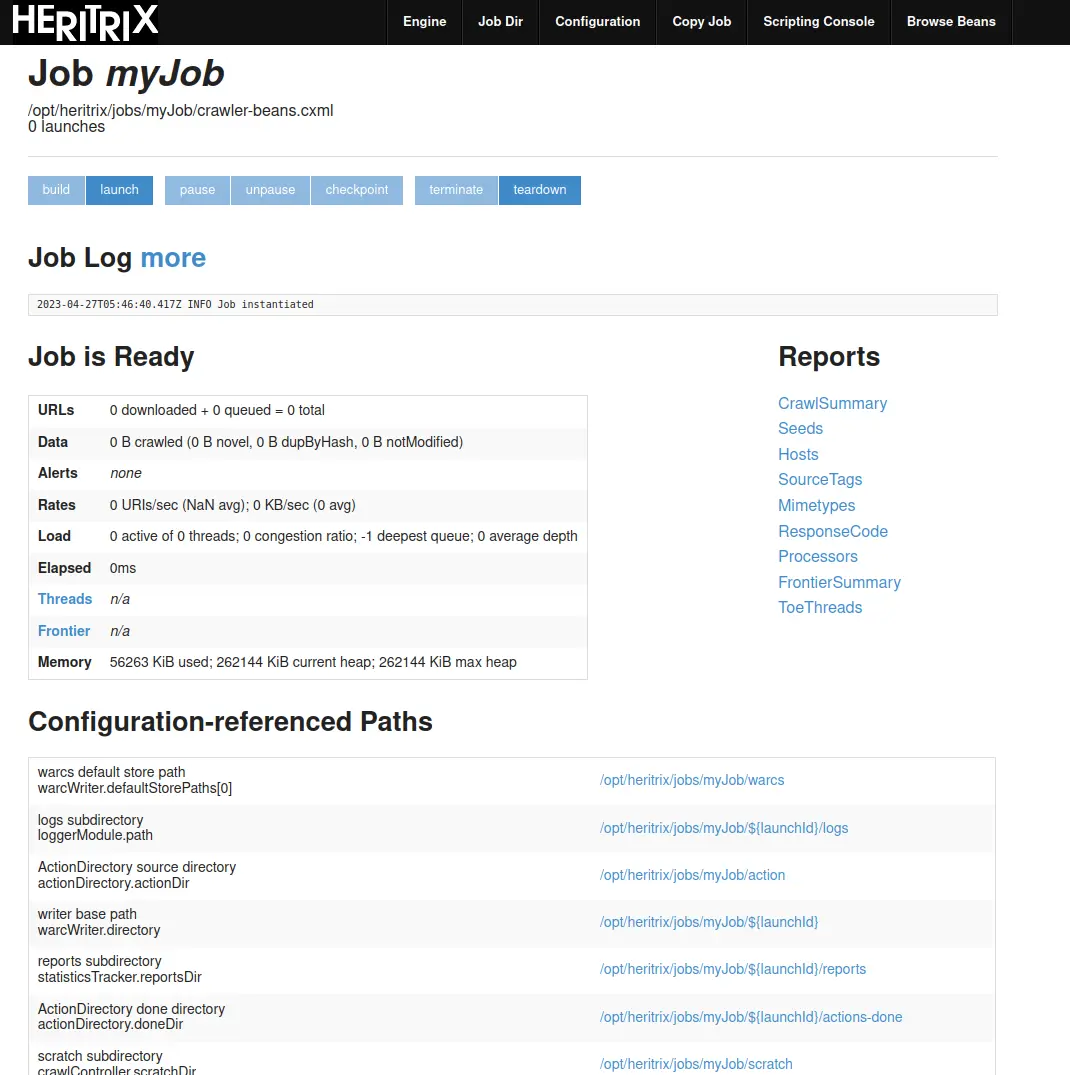
Job Log 를 확인 해 보면 Job instantiated 라고 확인 됩니다.
준비되었다면 이제 launch 버튼을 눌러줍니다. 그러면 작업이 paused 된 상태로 작업이 준비되는데요, 이어서 unpause 버튼을 클릭 하면 크롤링 job이 시작됩니다.
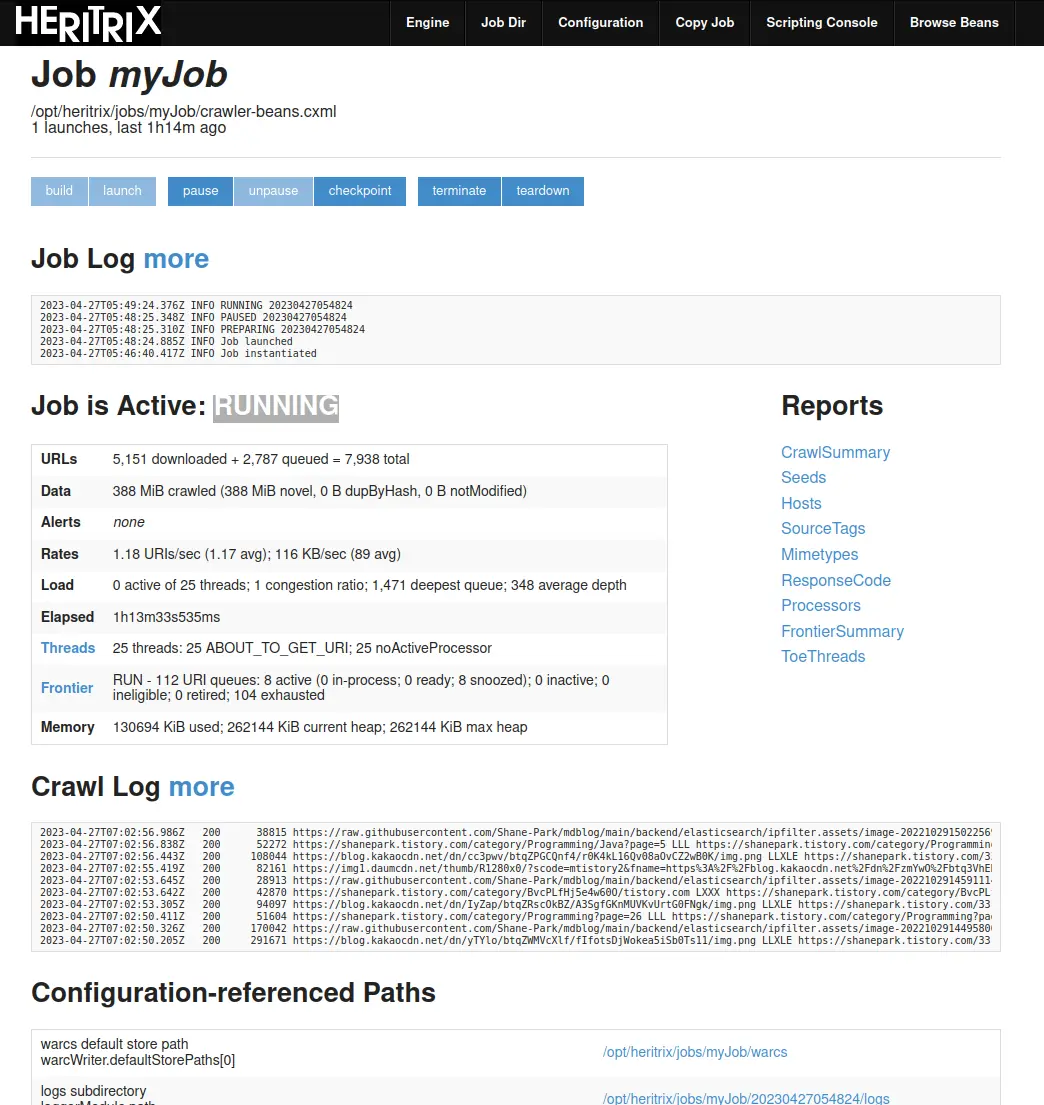
동작중
네 잘 동작중입니다. 하지만 문제가 있습니다.
위에 나오는 통계를 보면, 이미 수집한 URL이 5000개를 넘어가고 있고, 수집 시간은 1시간 13분을 넘어가고 있습니다. 자세한 수집이 요구되지 않은 상황에서 Crawl Job 설정을 필요에 맞게 잘 해주지 않으면 이런 곤란한 상황이 발생합니다.
아래와 같이 새로운 설정을 했을 때에는 1분 안에 크롤링이 끝났습니다. 설정에 대한 자세한 내용은 아래 바로 이어서 다루겠습니다.
<bean id="crawlLimitEnforcer" class="org.archive.crawler.framework.CrawlLimitEnforcer">
<property name="maxBytesDownload" value="100000000" />
<property name="maxDocumentsDownload" value="1000" />
<property name="maxTimeSeconds" value="300" />
</bean>
<bean id="maxLinkHops" class="org.archive.modules.deciderules.TooManyHopsDecideRule">
<property name="maxHops" value="2" />
</bean>
...
<property name="rules">
<list>
<ref bean="maxLinkHops" />
변경한 설정
Job 설정
똑같은 실수를 하지 않기 위해 이번에는 my_second_job을 생성 하였습니다.
이번에도 똑같이 Configurations 에 들어가지만, 이번에는 crawler-bean.cxml 파일을 좀 더 유심히 살펴보려고 합니다. 설정은 새로운 빈 등록을 통해 변경할 수 있습니다.
Crawl Limits
이렇게 무작정 끝도없이 크롤링 하는 걸 막기 위해서 리밋 설정이 필요합니다.
<bean id="crawlLimitEnforcer" class="org.archive.crawler.framework.CrawlLimitEnforcer">
<property name="maxBytesDownload" value="100000000" />
<property name="maxDocumentsDownload" value="100" />
<property name="maxTimeSeconds" value="10000" />
</bean>위와 같이 최대 다운로드 바이트, 최대 문서 수, 최대 크롤링 시간 등을 제한 할 수 있습니다.
Robots.txt Honoring Policy
Robot.txt 파일 규칙을 따를건지 설정합니다. obey 혹은 classic의 경우 robot.txt 파일과 메타태그를 따르지만, robotsTxtOnly는 robot.txt파일만을 따르고, ignore는 둘 다 무시합니다.
3 버전 기준으로 아직까지는 robot.txt의 wildcard(*)를 경로의 맨 마지막에 붙는것만 지원한다고 합니다.
<bean id="metadata" class="org.archive.modules.CrawlMetadata" autowire="byName">
...
<property name="robotsPolicyName" value="obey"/>
...
</bean>Crawl Scope
크롤링 될 수 있는 URI 범위를 정의합니다. 해당 URI들은 결정 규칙에 따라 정해지는데, 각각의 DecideRule은 객체(보통 URI)에 대해 ACCEPT(포함), REJECT(배제), PASS(패스) 중 한가지 결정을 내립니다. 처음에는 아무런 상태 없이 시작해서 각 규칙이 차례대로 적용되어, 해당 URI는 최종 상태가 ACCEPT 인 경우에는 scope 내부로 결정되며, REJECT인 경우 폐기 됩니다.
그 중 TooManyHopsDecideRule가 있는데, 해당 설정을 변경하여 최대 크롤링 깊이를 제한 할 수 있습니다.
<bean id="maxLinkHops" class="org.archive.modules.deciderules.TooManyHopsDecideRule">
<property name="maxHops" value="3" />
</bean>maxLinkHops 규칙을 추가 한 뒤에는, DecideRules에 추가해줍니다.
<bean id="scope" class="org.archive.modules.deciderules.DecideRuleSequence">
<property name="rules">
<list>
<!-- 기존 규칙들 -->
<ref bean="maxLinkHops" />
</list>
</property>
</bean>Retry Policy
Frontier 는 초기의 fetch 요청 에러가 일시적일 때를 대비해, 재 시도에 관한 설정을 할 수 있습니다.
<bean id="frontier" class="org.archive.crawler.frontier.BdbFrontier">
<property name="retryDelaySeconds" value="900" />
<property name="maxRetries" value="30" />
</bean>그 외 Rule이 너무 많기 때문에 하나하나 작성하지는 않고 링크를 남겨두겠습니다.
https://heritrix.readthedocs.io/en/latest/configuring-jobs.html#decide-rules
REST API
Heritrix는 REST API를 통한 조작도 제공합니다. 몇몇 API를 간단히 살펴보겠습니다.
GET:/engine
Heritrix 인스턴스의 버전 정보, 메모리 사용량, 크롤잡 목록 등을 반환합니다.
curl -v -k -u admin:admin --anyauth --location -H "Accept: application/xml" https://localhost:8443/engine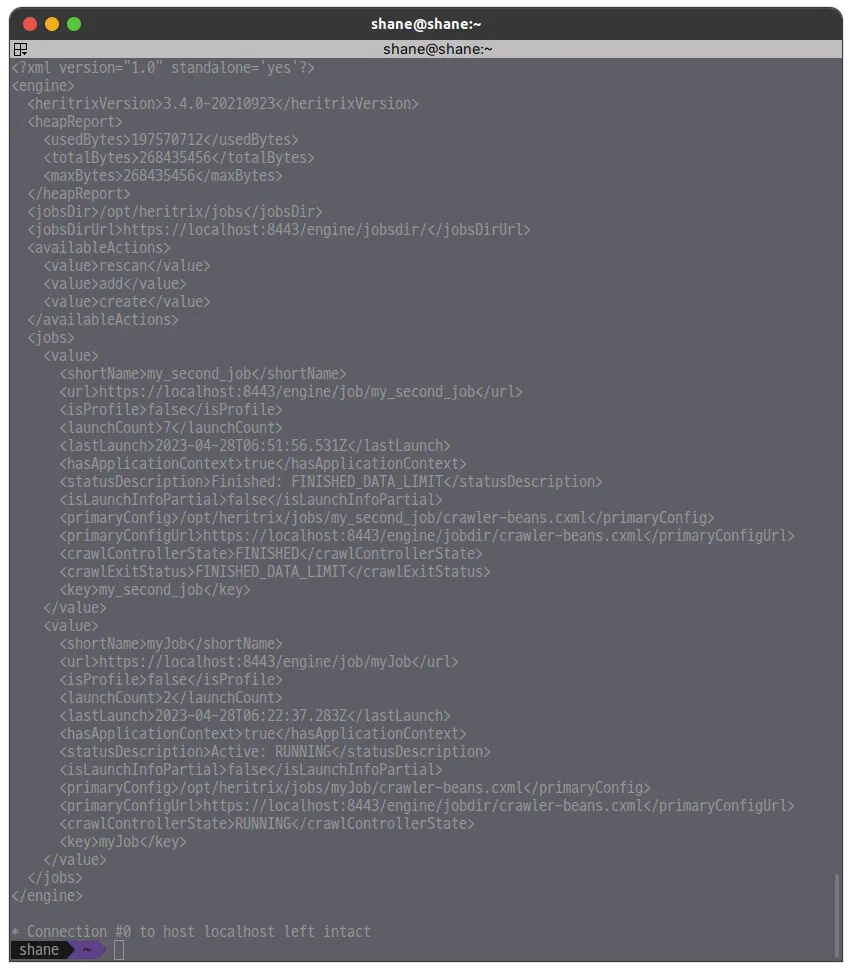
POST:/engine [action=create]
profile-defaults 에 있는 기본 설정으로 새로운 crawl job을 생성 합니다.
curl -v -d "createpath=api_job&action=create" -k -u admin:admin --anyauth --location \
https://localhost:8443/enginePOST:/engine [action=add]
Heritrix 설정에 새로운 job 폴더를 생성 합니다. 해당 경로는 반드시 cxml 설정 파일을 포함하고 있어야 합니다.
curl -v -d "action=add&addpath=/Users/hstern/job" -k -u admin:admin --anyauth --location https://localhost:8443/engineGET:/engine/job/(jobname)
선택된 job의 상태와 통계를 반환합니다.
curl -v -k -u admin:admin --anyauth --location -H "Accept: application/xml" https://localhost:8443/engine/job/myJobPUT:/engine/job/(jobname)/jobdir/crawler-beans.cxml
선택된 job에 CXML 파일을 제출 합니다.
그 외에도 웹페이지를 통해 조작했던 모든 기능들이 사용 가능합니다.
그 외의 모든 API는 아래의 링크에서 확인해주세요
그러면 RESTAPI 만을 이용해서 크롤링을 시도해보겠습니다.
# 1. api_job 이라는 이름의 job 생성
curl -v -d "createpath=api_job&action=create" -k -u admin:admin --anyauth --location \
https://localhost:8443/engine
# 2. cxml 파일 제출. 명령을 실행하는 경로에 my-crawler-beans.cxml 파일이 있어야 함.
curl -v -T my-crawler-beans.cxml -k -u admin:admin --anyauth --location https://localhost:8443/engine/job/api_job/jobdir/crawler-beans.cxml
# 3. Build Job Configuration
curl -v -d "action=build" -k -u admin:admin --anyauth --location https://localhost:8443/engine/job/api_job
# 4. Launch job
curl -v -d "action=launch" -k -u admin:admin --anyauth --location https://localhost:8443/engine/job/api_job
# 5. Unpause Job
curl -v -d "action=unpause" -k -u admin:admin --anyauth --location https://localhost:8443/engine/job/api_job
# 6. Job 상태 확인
curl -v -k -u admin:admin --anyauth --location -H "Accept: application/xml" https://localhost:8443/engine/job/api_job
# 7. Teardown
curl -v -d "action=teardown" -k -u admin:admin --anyauth --location https://localhost:8443/engine/job/api_job
RESTAPI 요청만으로도 필요한 모든 기능을 사용하고, 문제 없이 크롤링을 해낼 수 있었습니다.
결과물 확인
Finished
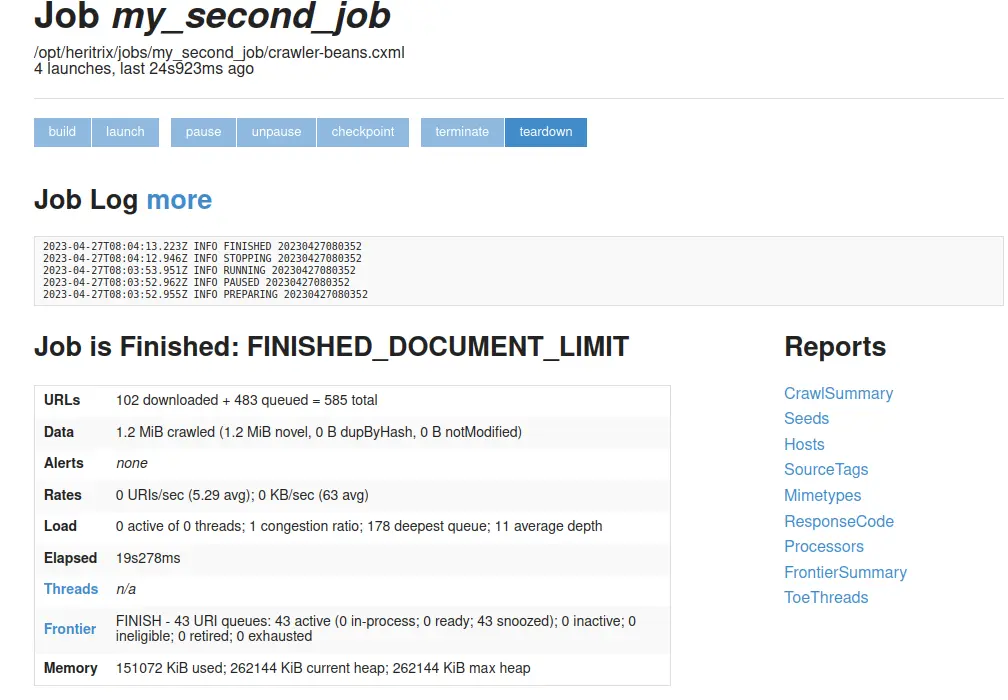
Crawl job이 종료되었으면 위와 결과를 확인할 수 있습니다.
Docker로 실행했고, /opt/heritrix/jobs 경로를 볼륨으로 바인딩 해 두었기 때문에, 결과물 파일을 손쉽게 확인 할 수 있습니다.
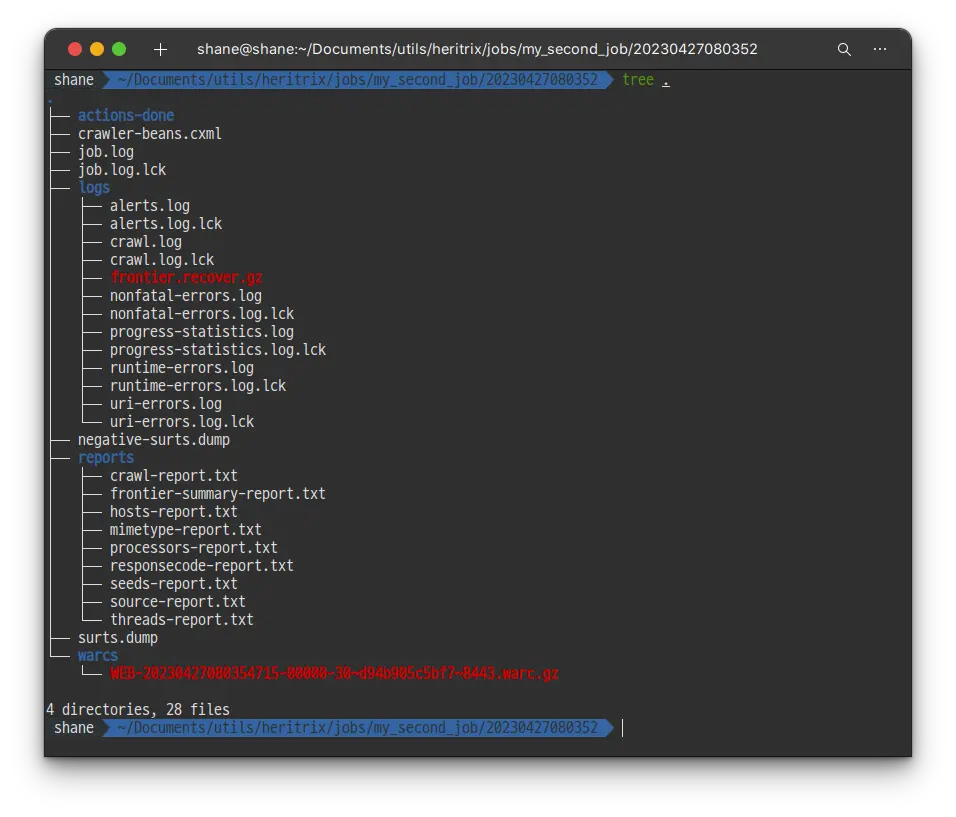
jobs 폴더에서 완료된 my_second_job에 들어가, 최종적으로 수집된 정보를 확인 해 보면 warcs 폴더 하위에 .warc.gz 파일이 보입니다. 해당 파일이 바로 웹 아카이브 파일 입니다.
Pywb
이제 warc 파일을 확인해보려고 하는데요. 이를 위해서 pywb를 사용해보겠습니다.
제일 먼저 webarchive 라는 폴더를 생성 하고 거기에 warc 파일을 압축 풀어서 넣어두었습니다. 그리고 나서
# 볼륨 설정할 폴더 생성
mkdir pywb-data
# my-web-archive 라는 이름의 컬렉션 생성하고, warc 파일 추가
docker run --rm -e INIT_COLLECTION=my-web-archive \
-v $(pwd)/pywb-data:/webarchive \
-v $(pwd)/webarchive:/source webrecorder/pywb wb-manager add my-web-archive /source/myfile.warc
# 8008 포트로 wayback 실행
docker run -d -p 8080:8080 \
--name pywb \
-v $(pwd)/pywb-data:/webarchive \
webrecorder/pywb wayback그러면 아래와 같이 컬렉션이 추가됩니다.
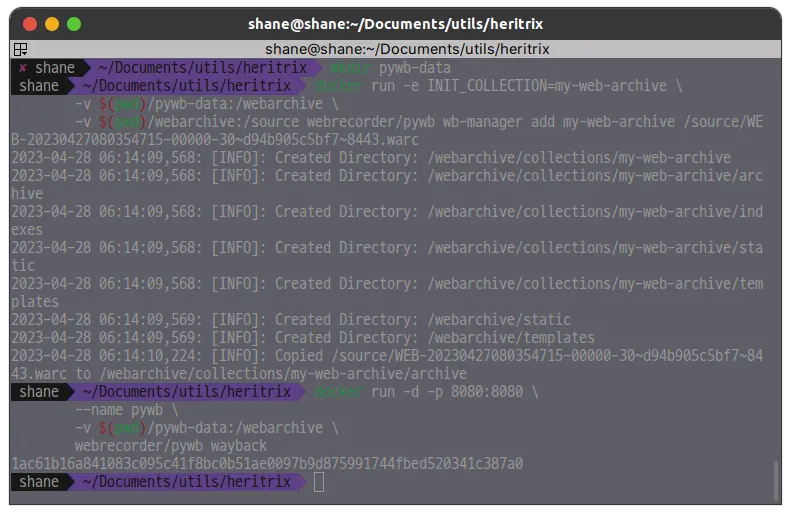
명령어 실행 완료
이제 localhost:8080 에 접속 해보면 아래와 같은 Wayback Machine 이라는 텍스트가 반겨줍니다.

메인 화면
여기에서 /my-web-archive를 클릭 하고 들어가면..
검색
해당 컬렉션에서 탐색할 url을 입력 하라고 합니다.
그려면 warc 파일에 크롤링 되어 있는 url을 입력 후 Search 버튼을 눌러 줍니다.
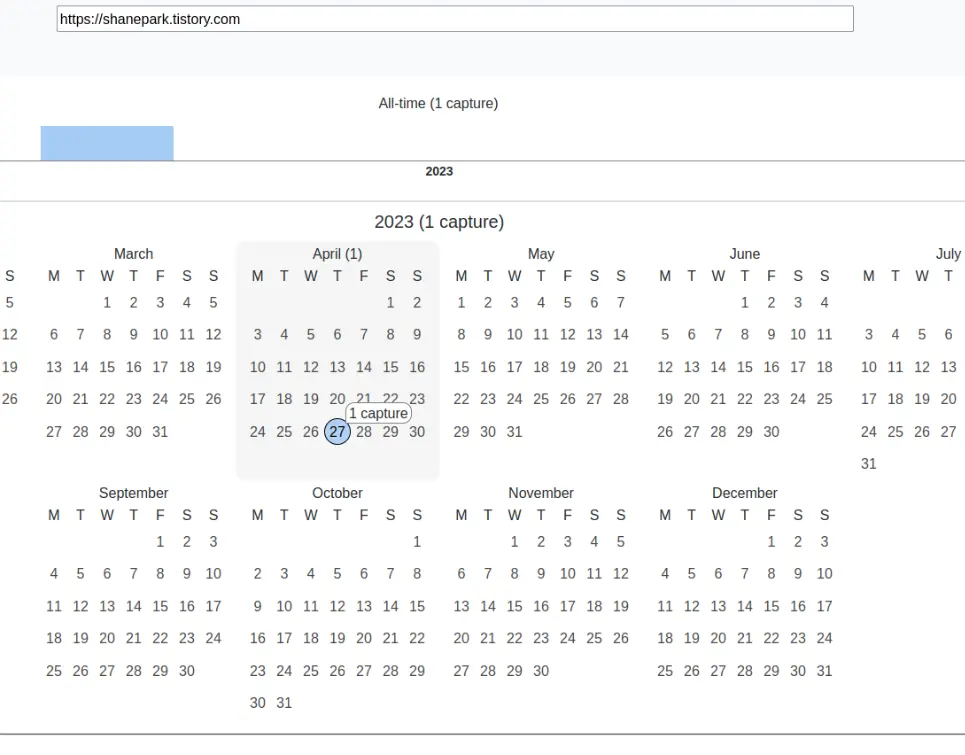
그러면 4월 27일에 한개의 capture가 확인 됩니다.
이제 클릭해서 확인 해 보면
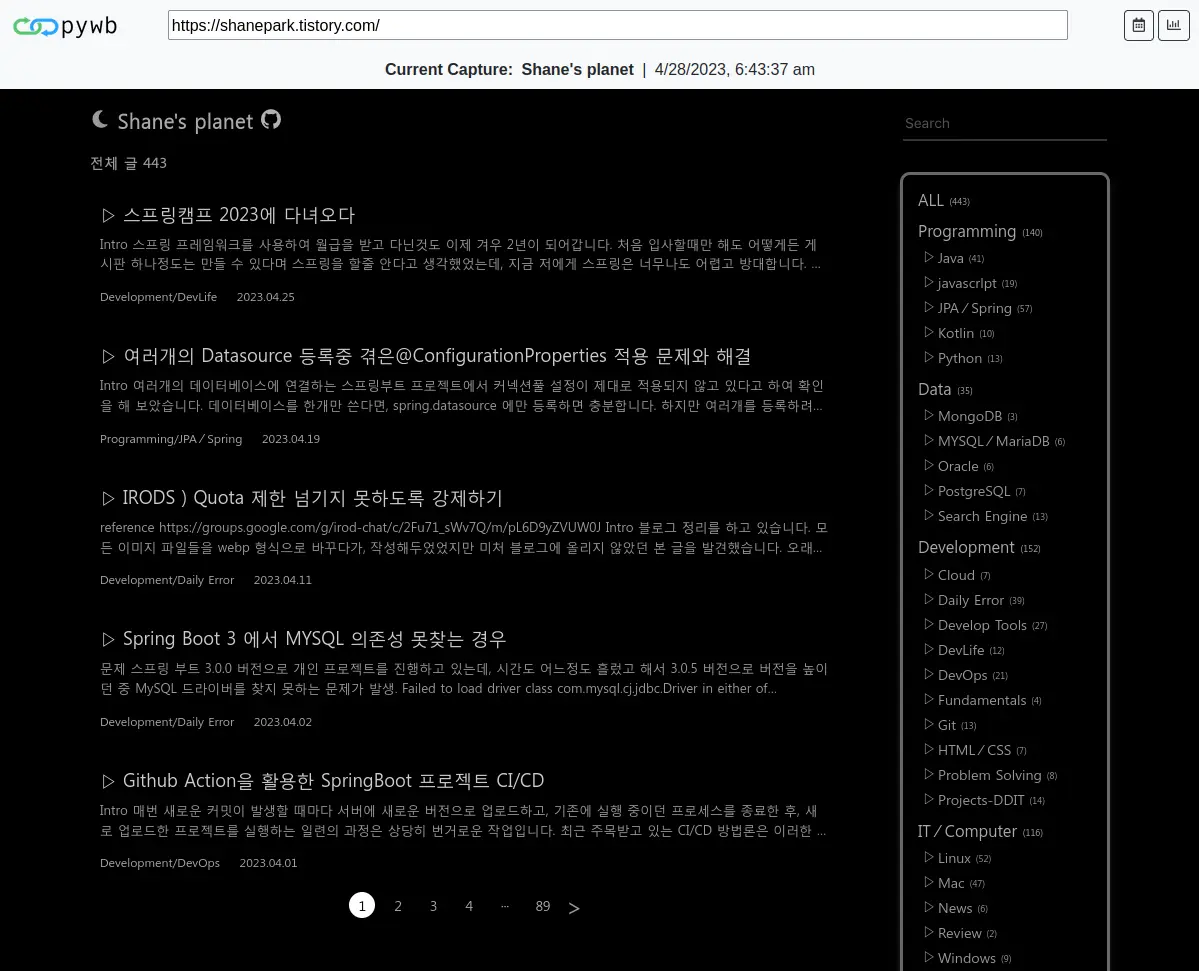
정상적으로 크롤링 된 결과물을 확인 할 수 있습니다. maxHops 및 maxDocumentsDownload 등을 넉넉히 설정 해 두었다면, 클릭해서 다른 페이지로 넘어가도 크롤링된 작업물 확인이 가능합니다.
이상입니다.
References
'Development > Develop Tools' 카테고리의 다른 글
| 매일 LeetCode 문제 풀이, 터미널 한 줄로 간편하게 (0) | 2024.11.16 |
|---|---|
| Github 저장소 언어 표기 설정 (0) | 2024.11.15 |
| Liquibase 변경사항을 sql 파일로 추출하기 (0) | 2023.03.25 |
| iPhone 사파리 페이지를 개발자모드 열기 (0) | 2023.01.28 |
| [IntelliJ IDEA] 파일 생성시 라이센스 정보 자동으로 입력하기 (0) | 2022.12.23 |