Intro
LLM 모델 하면 ChatGPT를 떠올리는 사람들이 많지만, 오픈소스 AI 모델들도 꾸준히 발전하고 있다. LLAMA3는 Meta에서 개발한 대규모 언어 모델로, 오픈소스 모델 중에서도 상당히 주목받고 있다. 이를 로컬 환경에서 실행할 수 있게 도와주는 도구가 Ollama다. Ollama는 간단한 명령어로 LLAMA3 같은 모델을 다운로드하고 실행할 수 있게 해주는 도구로, REST API까지 제공해서 확장성도 꽤 뛰어나다.
이번 글에서는 LLAMA3를 설치하고 실행해 본 경험을 바탕으로 이 모델의 장단점과 활용 가능성을 리뷰해 보려고 한다.
설치 및 실행
설치
리눅스 및 macOS 환경에서는 명령어 한줄로 실행 가능하다.
그 외의 환경(Windows)는 아래의 링크를 참고해서 설치한다.
# Linux
curl -fsSL https://ollama.ai/install.sh | bash
# MacOS
brew install --cask ollama설치 완료 후 확인
ollama --version
# ollama version is 0.5.4모델 다운로드
LLAMA3 기본 모델은 아래 명령어로 다운로드한다.
ollama pull llama3실행
다운로드가 끝나면 손쉽게 바로 실행 가능하다.
ollama run llama3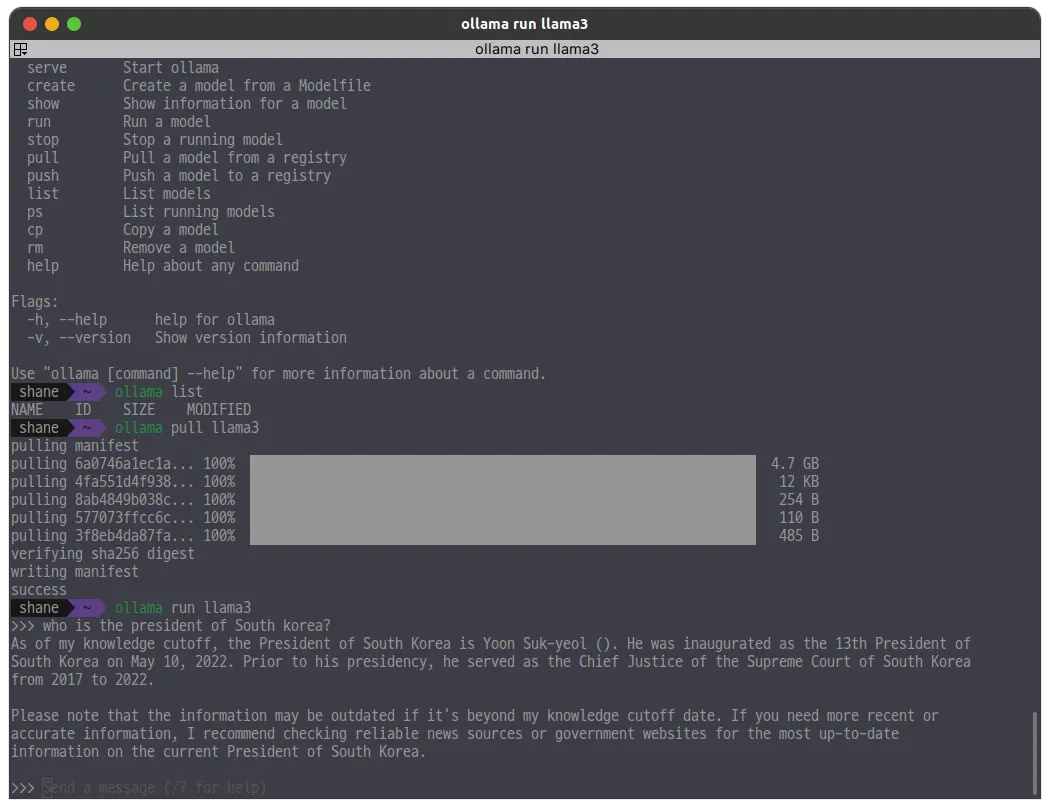
쿼리를 보내면 응답을 하는데 한국어는 잘 못한다. 그리고 학습 데이터가 꽤 오래전이다.
한국어 특화모델 테스트
한국어 성능 테스트를 위해 Hugging Face에서 한국어 모델을 다운로드 받아보았다.
https://huggingface.co/MLP-KTLim/llama-3-Korean-Bllossom-8B-gguf-Q4_K_M/tree/main
아래와 같은 내용으로 Modelfile 을 작성해준다.
FROM ./llama-3-Korean-Bllossom-8B-Q4_K_M.gguf작성후에는 create 명령어로 등록해준다.
ollama create llama3-Korean-Bllossom -f Modelfile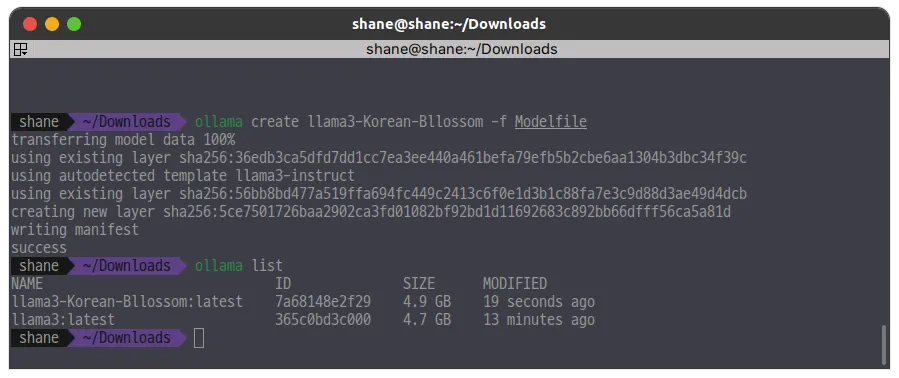
실행해준다.
ollama run llama3-Korean-Bllossom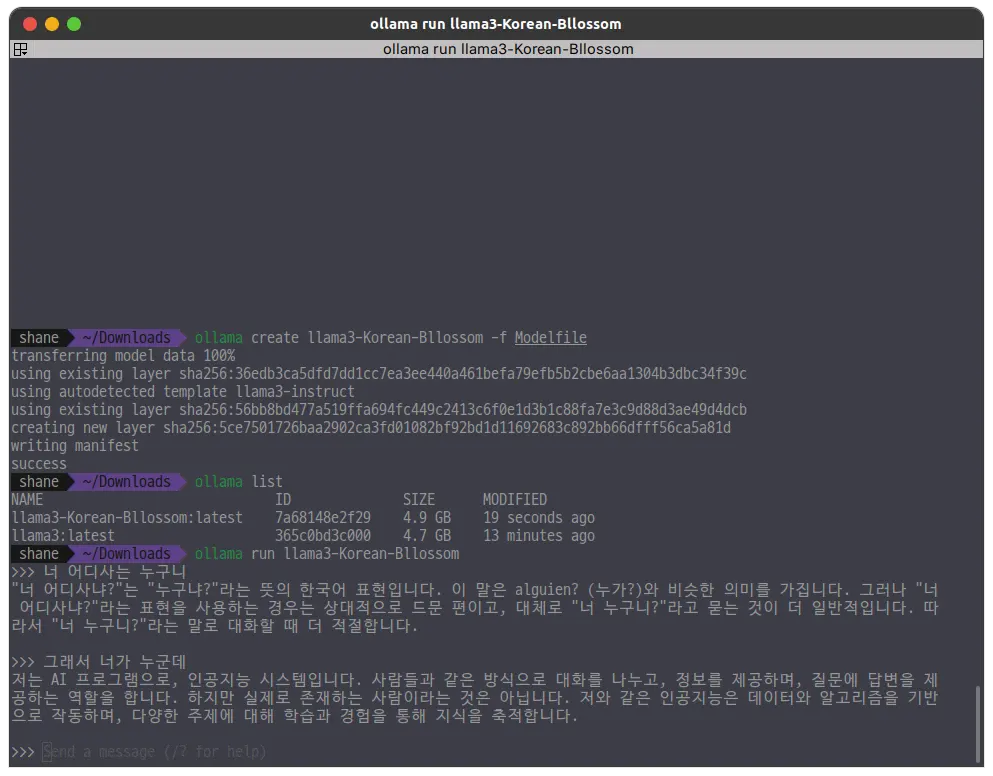
답변이 조금 이상한 면도 있긴 했지만 한국어도 곧잘 이해하는 편이다.
상태확인
ollama ps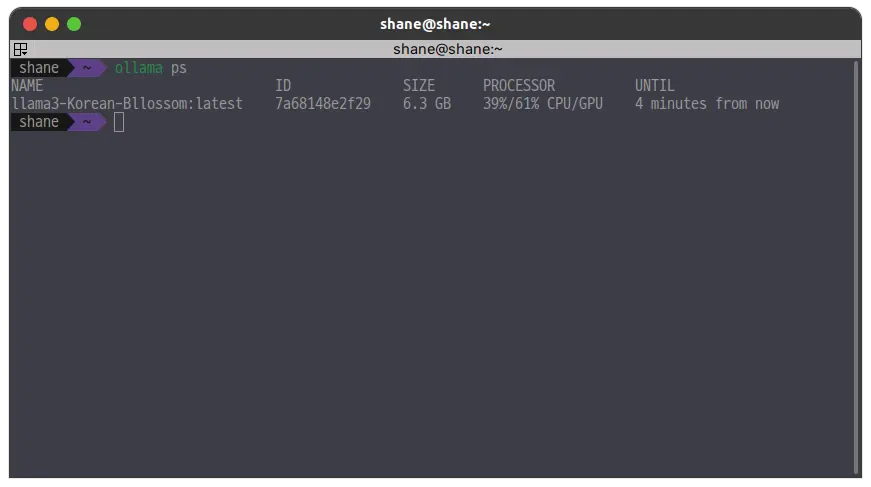
CPU 100% 로도 돌려보고, GPU와 병형해서도 돌려봤는데 확실히 비교해보니 성능 차이가 컸다. LLM을 로컬에서 실행하려면 GPU가 있는 환경으로 준비를 해두어야 겠다. 다만 한국어 모델임에도 한국어 성능이 기대보다는 이하였다.
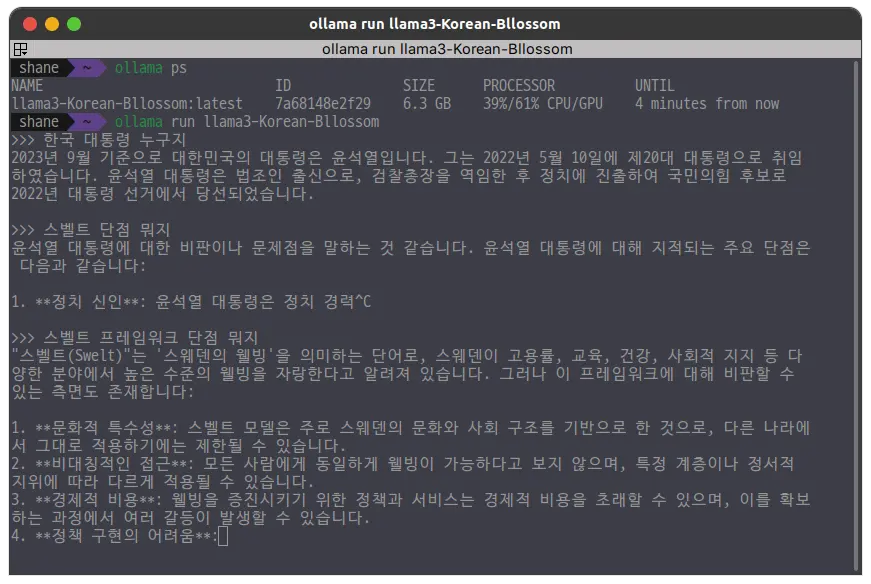
Context가 섞이자 엉뚱한 이야기를 한다.
한국어 특화 모델이지만 영어로 질문했을때 더 나은 답변을 잘 했다.
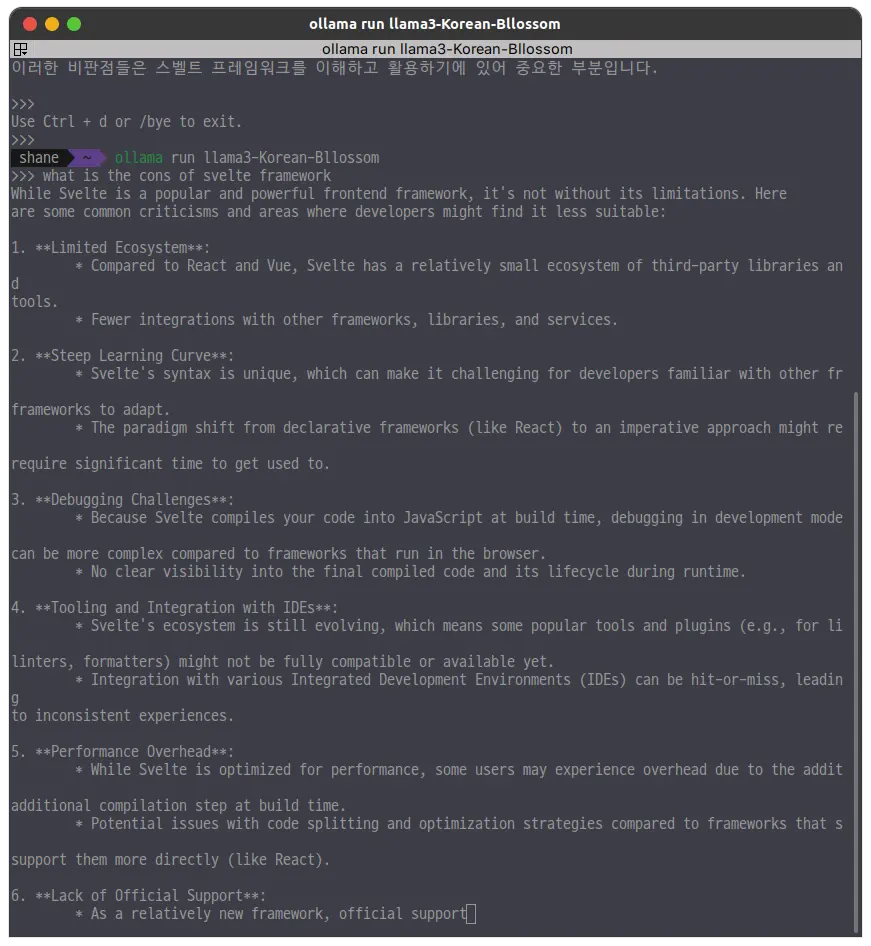
더 큰 모델 테스트
기본 llama3 는 8B(80억 파라미터) 모델이다. 학습 데이터도 오래되어서 별도의 두가지 다른 모델을 테스트 해보았다.
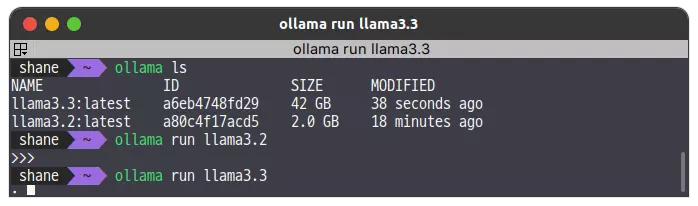
첫번째로는 llama3.2(3.2B) 모델인데, 더 가볍지만 성능은 나쁘지 않았다. 용량도 2.0GB로 적게 차지하고, 무엇보다 모델이 가벼워서 딱 쓰기 좋았다.
llama3.3
대망의 llama3.3(70B) 모델이다. 용량부터가 42GB로 어마무시하다. 성능이 어느정도 나올지 기대가 된다.
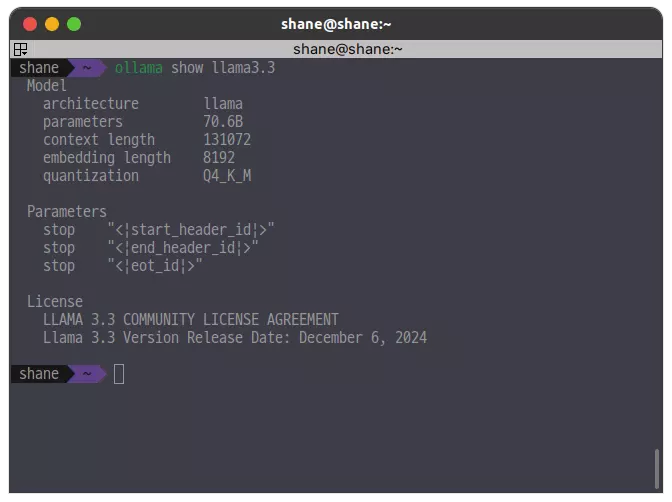
돌릴수 있을지 없을지 반신반의 했지만 간단한 쿼리를 해 보았다.
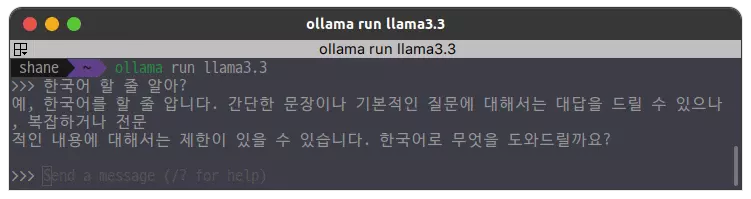
llama3(8B)나 llama3.2(3B) 모델과는 다르게 한국어도 자연스럽게 구사했다.
그런데 문제가 있었으니, 컴퓨터가 굉장히 괴로워한다. XPS15 9500 시리즈에 램도 64GB로 넉넉한데도 정말 가까스로 응답을 뱉어내는 수준이다. 응답도 아주 느려서 좀 더 복잡한 질문을 하면 굉장히 오래 기다려야 한다.
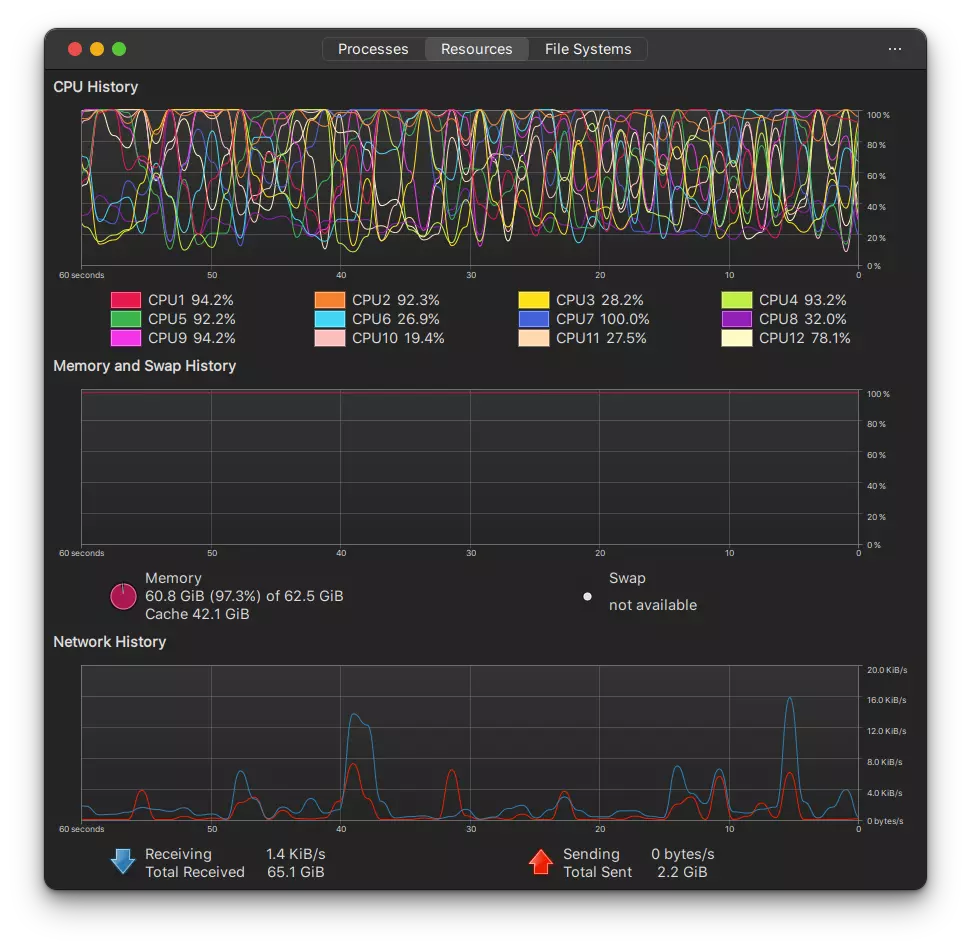
곧 응급실에 갈 것 같은 PC의 바이탈 상태
70B 정도의 큰 모델을 사용하려면 제대로된 PC 사양을 갖춰야하고, 전력도 엄청나게 소모할 것으로 보이는데 그러면 사실상 비용절약은 힘들어보인다. 보안상 문제로 on premise 구축만 허용된 상황에서나 활용을 고민해볼 듯 하다.
너무 느리고 PC에 부담이되는게 보여서 많은 테스트는 못 해보았지만 응답 품질은 기대보다 괜찮았다.
Ollama REST API
ollama 는 REST API를 제공한다. 이를 활용하면 모델과 쉽게 통신할 수 있어서 프로덕트에 활용하고싶다면 이를 사용하는편이 좋아보인다.
curl http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt": "Why is the sky blue?"
}'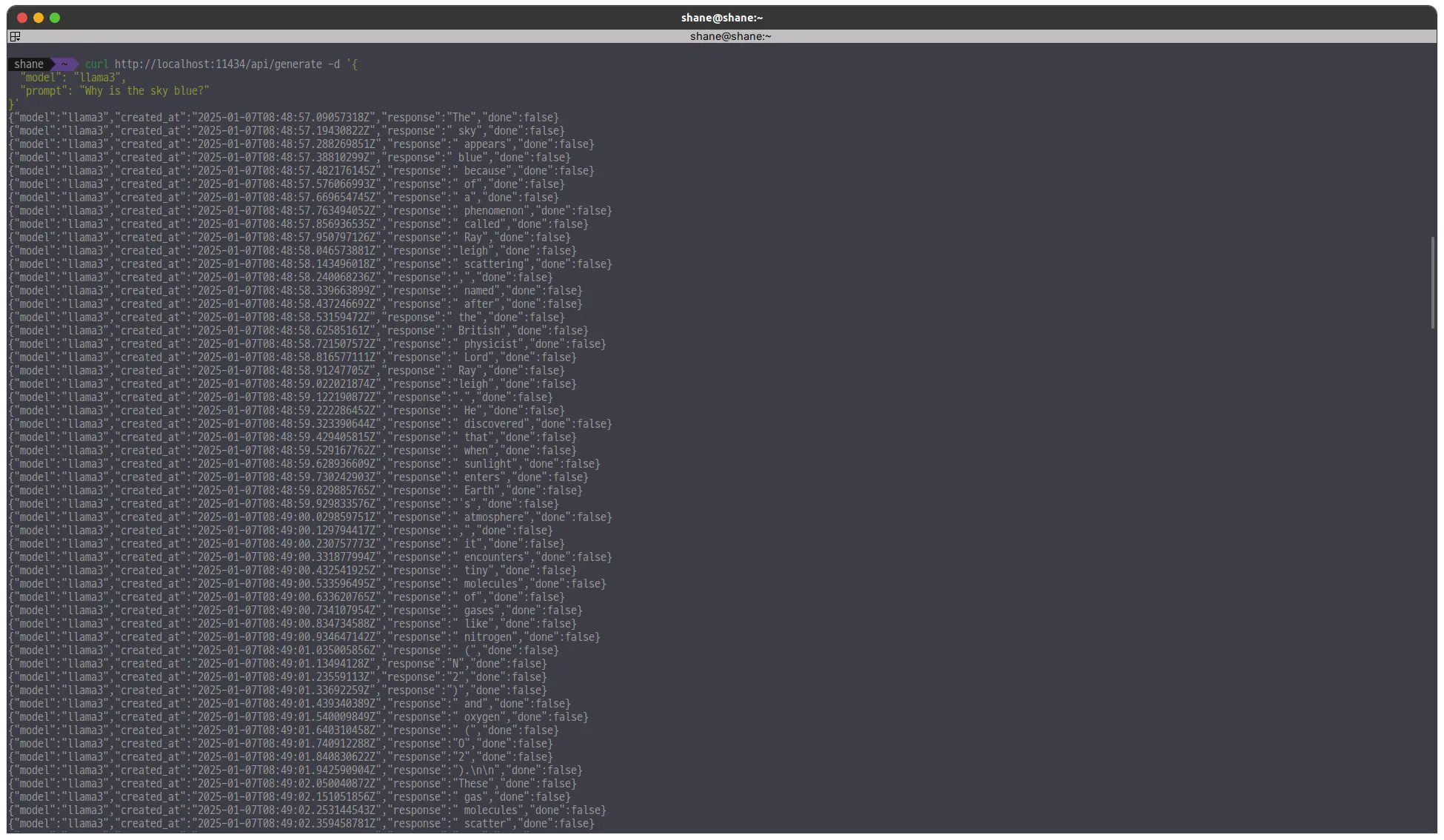
stream 옵션이 켜있으면 응답이 스트림으로 계속 온다.
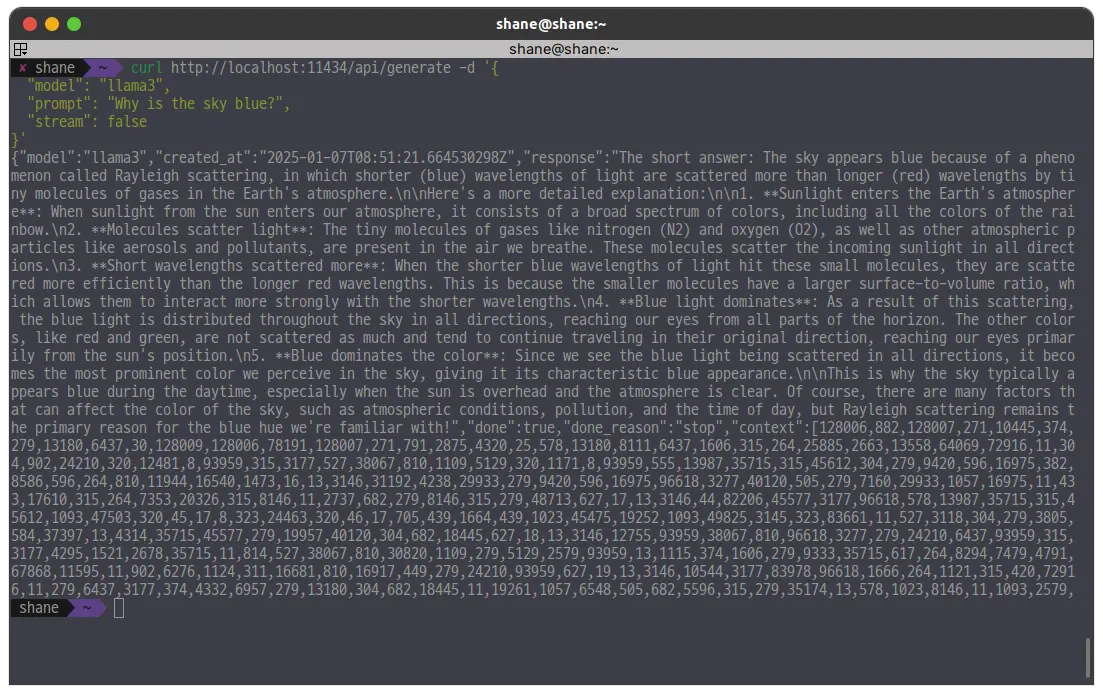
stream: false 를 하면 스트림으로 안오고 한번에 온다. 대신 응답은 굉장히 오래 걸린다.
curl http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt": "Why is the sky blue?",
"stream": false
}'
사용 후기 및 결론
- 응답 품질.
- LLAMA3는 영어 답변은 어느 정도 괜찮지만, 한국어 응답은 기대 이하.
- 심지어 한국어 특화 모델도 한국어보다는 영어에서 더 나은 성능을 보였다.
- 좋은 응답 품질을 얻기 위해서는 비례하는 컴퓨팅 자원 투자가 필수적임
- 속도
- GPU 환경에서 LLAMA3는 그나마 쓸만한 속도를 보여주지만, 그래도 나쁘지 않은 PC 성능을 감안하면 아쉬웠다.
- 활용성
- LLAMA3는 네트워크 없이 실행할 수 있다는 점이 강점.
- 하지만, 품질과 속도 이슈로 실제 프로젝트에 쓰려면 적당 크기의 모델에 파인튜닝을 해야할 듯 하다
로컬에서 AI 모델을 실행할 수 있고, 별도의 사용 요금이 들지 않는다는 뚜렷한 장점이 있다.
그렇기에 상용 모델에 비해서 품질은 조금 떨어질언정 프롬프트 엔지니어링을 좀 신경써서 하고 잘 활용한다면 나름대로 유용하게 활용할 수도 있어 보인다.
References
'Data > LLM' 카테고리의 다른 글
| Deepseek r1 모델을 로컬에서 돌려보자 (0) | 2025.02.02 |
|---|---|
| 개발자와 CHATGPT (5) | 2024.12.29 |