Intro
이전 글에서 LLAMA3 로컬 설치 실행 및 테스트 를 해보았다.
최근 제한된 자원으로 뛰어난 성능을 발휘하는 LLM인 Deepseek가 화제다. X(Twitter) 에서 관련 글이 잔뜩 올라오기 시작하더니 얼마 지나지 않아 주식시장에서 엄청난 파장을 일으키는 바람에 모든 사람들이 다 알게 되었다. 안그래도 제한된 자원으로 자체적으로 LLM을 구축하자니 성능이 아쉽고 컴퓨팅파워가 너무 많이 들어가고 그렇다고 상용모델(OpenAI)을 사용하자니 비용이 부담되는 상황에서 굉장히 솔깃한 내용이다.
특히 R1 모델의 경우에는 믿거나 말거나 겨우 80억의 비용으로 o1 모델에 대적하는 성능을 만들어냈다는데 뉴스에서는 검열이니 중국이라 믿을 수 없다느니 이상한 소리만 해댄다. 애초에 오픈소스 대형 언어모델로 발표되었기 떄문에 진정한 OpenAI 는 누구인가 논해야 할 정도의 상황이다.
대부분의 소프트웨어 관련 종사자들은 당연히 알겠지만 웹이나 앱에서의 검열된 Deepseek 서비스가 중요한게 아니다. 누구나 원하면 검증해볼 수 있으며 로컬에서 돌리면 당연하게도 위험하거나 비윤리적인 프롬프트 요청에는 응답하지 않도록 최소한의 안전장치는 되어있지만 국가나 정치와 관련된 검열은 전혀 이루어지지 않는다.
다운로드 및 설치
Ollama 설치
brew install --cask ollama리눅스에서 실행해봤을 때는 CUI로만 활용했지만, MacOS 에서는 cask로 설치해주니 눈에 보이는 그래픽도 있다. (특별한 그래픽 기능은 없는듯)
llama3.2 를 run 해보라고 하지만, deepseek 모델을 실행해볼 예정이니 굳이 하지 않는다.
모델 다운로드
deepseek-r1 모델을 다운로드 한다. ollama 홈페이지의 library 에서 검색할 수 있다.
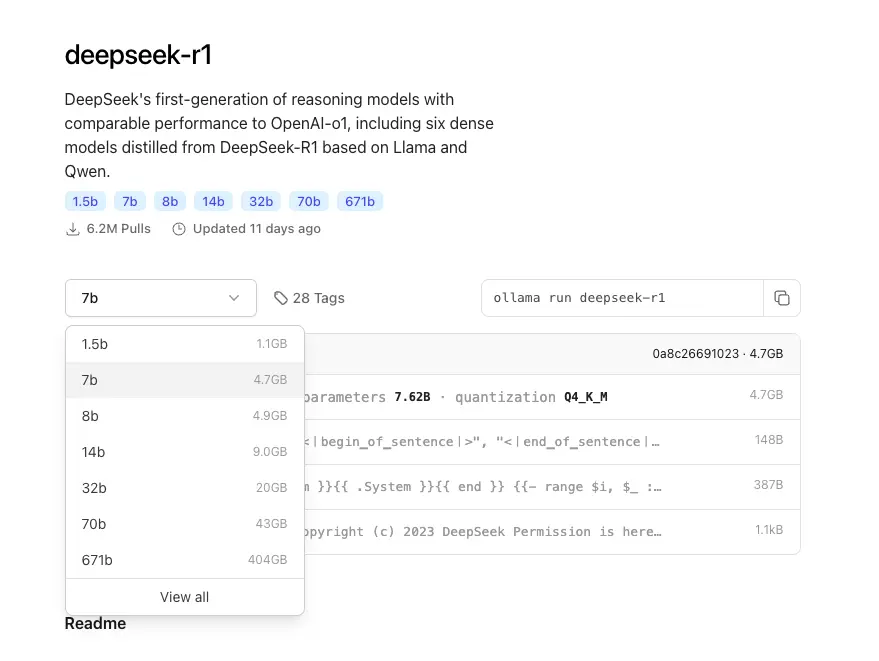
다양한 모델이 보이는데, 무턱대고 큰 모델을 띄웠다가는 곤란할 수 있으니 적당한 모델을 선택한다.
본인은 m2 맥북에어 24GB 램을 사용하고 있기 때문에 14b 모델을 실행해볼 것이다. 보통의 경우 그래픽 사양에 자신있다면 7b or 14b 모델을 시도해보고 잘 안돌아가면 1.5b 모델을 시도해보길 추천한다. M 시리즈 맥북의 경우에는 메모리풀을 공유하기 때문에 경량LLM 에는 꽤 유리하다.
ollama run deepseek-r1:14b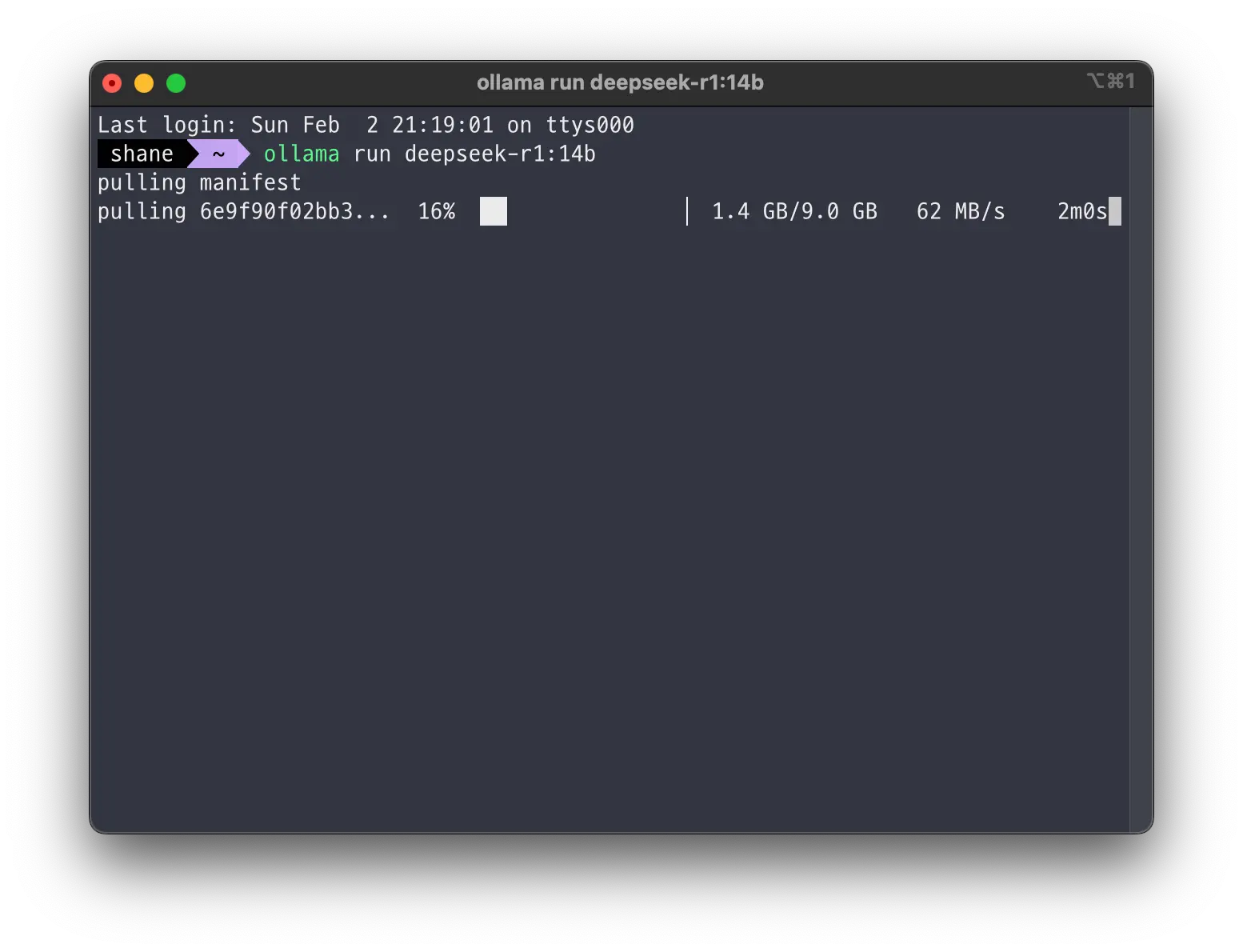
다운로드에는 500Mbps 인터넷 기준으로 2분 조금 넘게 걸렸다. 14b 모델을 실행했을 때 전혀 부담이 없고 TPS도 시원시원하게 나와서 약간의 테스트만 거치고 바로 32b 모델을 다운로드 했고, 용량은 2배 정도 되었다.
ollama run deepseek-r1:32b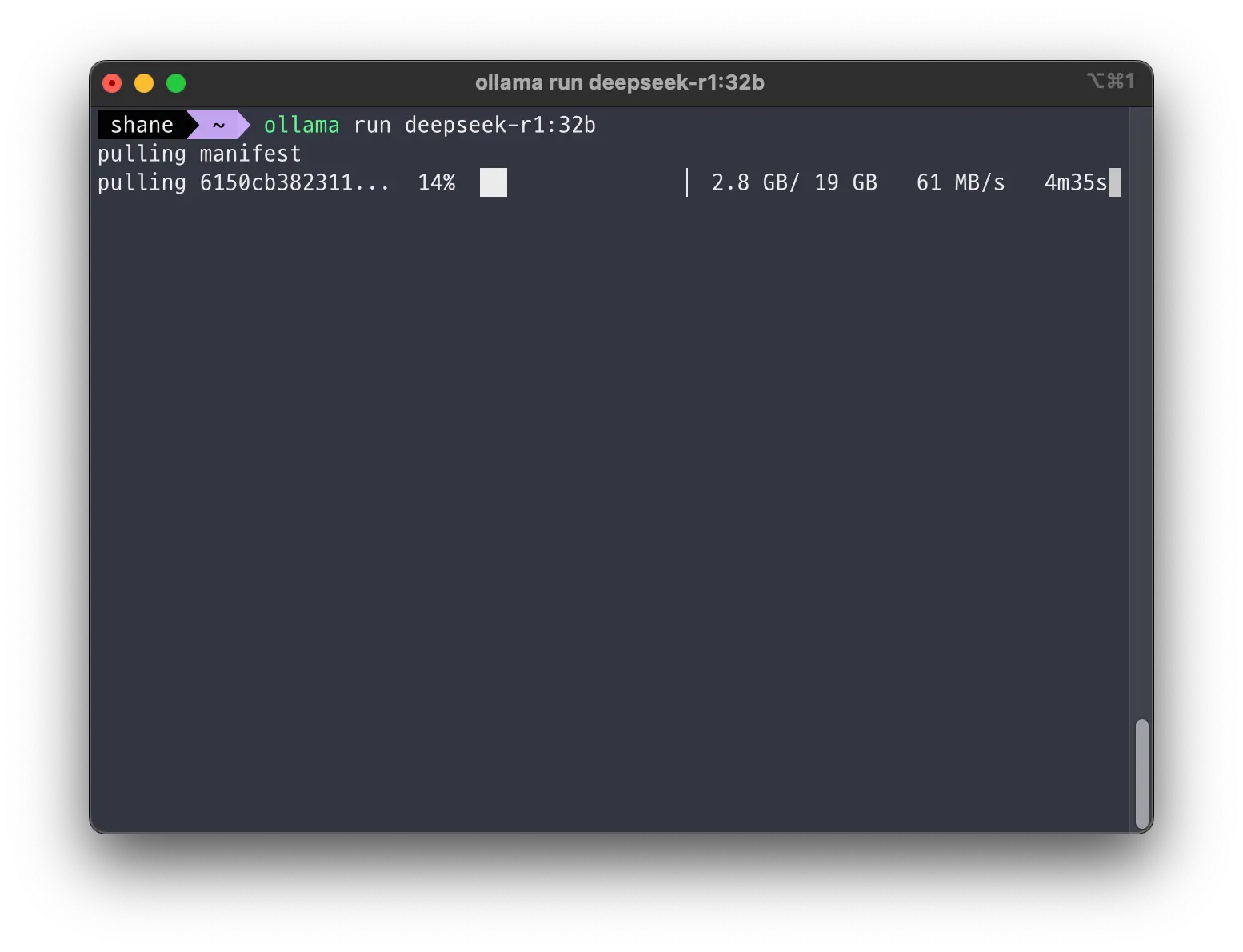
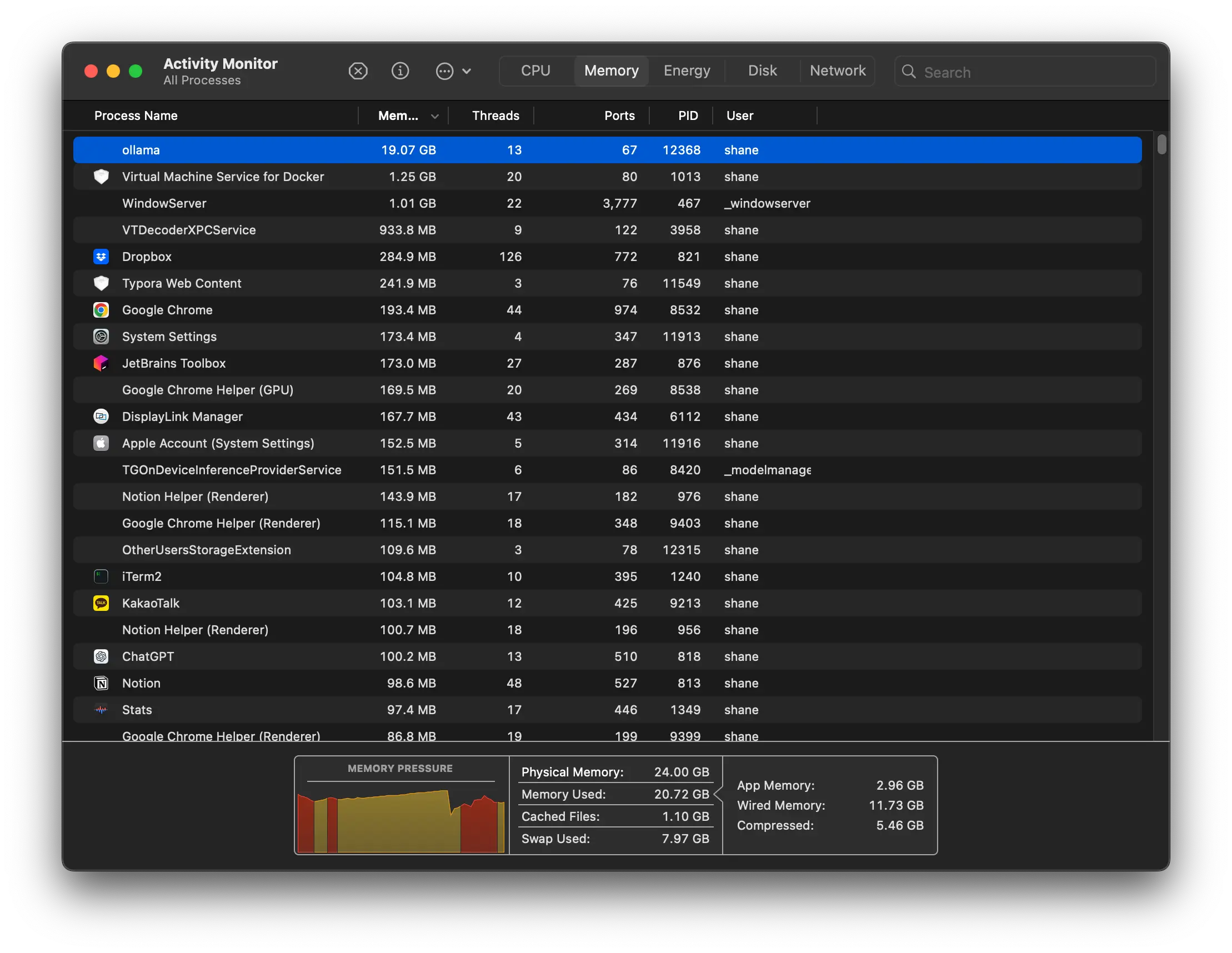
하지만 32b 모델은 컴퓨터가 감당해내기 힘들었다. 응답 속도도 안나와서 도저히 쓸 수 없었다. 내 로컬에서는 14b 모델이 딱 적당했다.
후기 및 결론
테스트를 시작하며 가장 궁금했던 두가지를 먼저 체크해보았다.
- 검열 및 위험한 질문에 대한 응답 여부
- 언어별 응답 퀄리티 및 응답 속도
검열 및 안전
검열은 인터넷에서 deepseek가 응답을 거부했다는 질문들을 찾아서 그대로 해 보았는데 아무런 제한 없이 응답했다. 흔히들 말하는 검열은 서비스단에서만 이루어졌으며 모델 자체에는 전혀 이루어지지 않았다. 학습 데이터가 편향되었을거라는 의혹제기도 많았으나 전혀 그렇게 느껴지지 않았다.
위험한 질문은, 가정에서 폭죽 만드는 방법 과 같은 당연히 응답하지 않아야 될 내용들을 위주로 해 보았고 짧은 시간내에 완성시킨 LLM 치고는 나름대로 안전장치도 잘 되어있는 듯 했다. 물론 다년간의 서비스와 실전 경험으로 욕도 많이 먹어온 OpenAI가 그부분은 잘 준비했겠지만 Deepseek도 탄탄했다.
응답 퀄리티 및 속도
응답 속도 및 응답퀄리티는 정말 인상깊었는데, r1:14b 모델 기준으로 4o 수준의 응답 퀄리티 및 속도를 경험했다. 그것도 겨우 내 m2 맥북 로컬에서 돌려낸 LLM 모델로. 직접 돌려보기 전에는 믿기 어려울거라 생각했는데 직접 돌리고 눈으로 확인했는데도 믿어지지가 않는 결과다.
불과 몇 주 전에 llama 3.3 의 70b 모델 정도를 파인 튜닝하고 프롬프트 엔지니어링을 잘 해내면 어떻게든 활용해낼 수 있을 지도 모르겠다는 결론을 내렸었는데 이건 그냥 집에서 홈서버로 쓰고 있는 노트북에 바로 올려서 서비스를 개발해도 되겠단 생각이 든다.
한국어 응답 퀄리티도 llama 와는 비교가 미안할 정도로 훨씬 훌륭했다. 영어나 중국어에 비하면 완벽하다고는 할 수 없지만 gpt4 이전의 모델들 수준은 된다.
메타에서는 R1 기술을 분석하기 위해 4개의 전담 엔지니어링 팀까지 꾸렸다는데 그들이 받았을 충격이 어느정도일지 가늠이 안된다.
추론
r1이 뛰어나다는 추론 문제도 확인해보았다.
개인적으로 o1 모델을 테스트 하기 위해 작성해보았던 문제가 있는데, 여러번 실행 해 보았을때 gpt 4o 는 정답율이 10% 수준이고 o1의 경우에는 90% 정도로 맞추었던 문제가 있다. 14b 모델에게 문제를 내 보았는데
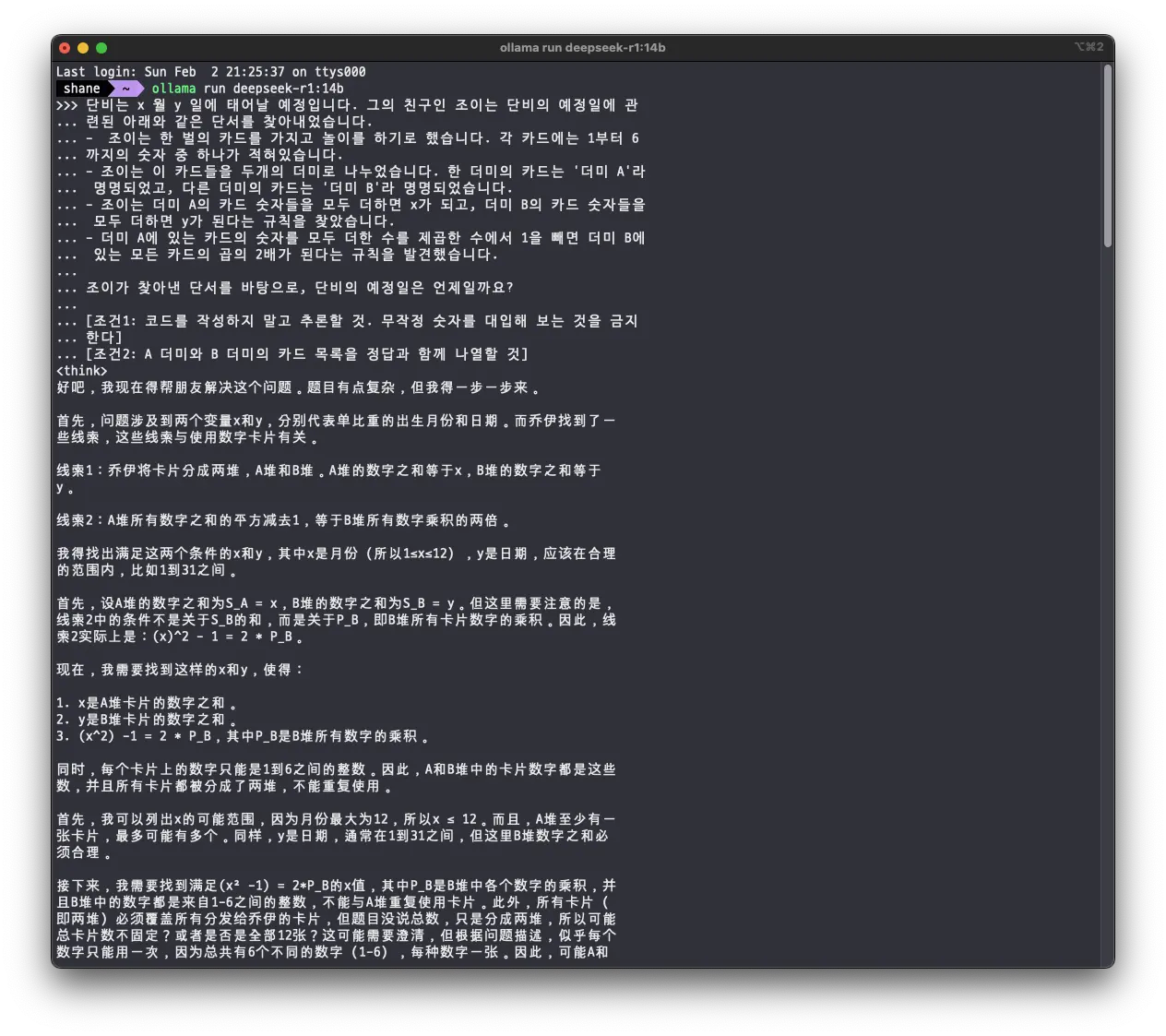
think 과정은 중국어로 했다. 아무래도 중국어가 모국어라 편한가보다.
o1도 1분씩 생각하는 문제라서, 스크린 샷에는 생략되었으나 r1 모델도 생각을 꽤 길게 했다.
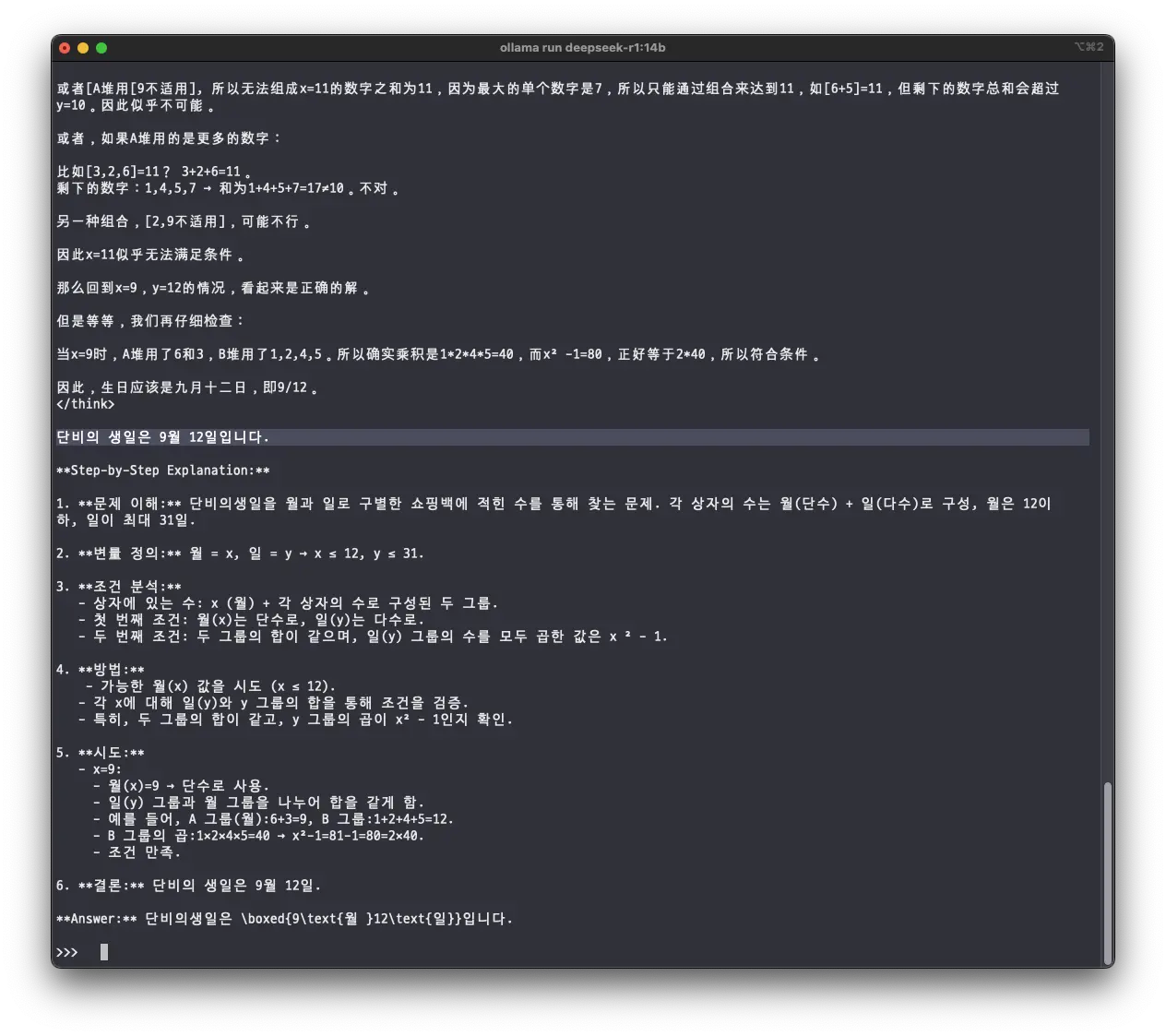
정답을 맞췄다..
솔직히 chatgpt에게 같은 문제를 수도 없이 내보았던 경험으로는 못맞출 거라는 거의 확신을 하고 있었는데 보기 좋게 깨졌다. 다양한 테스트를 해보았지만 가장 충격적인 순간이다. 아직 응답의 일관성까지 세세하게 테스트를 해본건 아니지만 이걸로 상용 서비스를 만들어 낼 수 있느냐는 논의는 무의미하다.
내 손 안에 o1 수준의 추론이 가능한 LLM이 아무런 대가도 없이 쥐어졌다. 몇년간 즐겨 한 PC 게임에서 치트 혹은 에디터를 처음 사용했을 때의 기분이다.
결론
위에서 언급했던 것 처럼 Deepseek 가 진정한 의미의 OpenAI를 열어줄 수 있지 않을까 기대가 된다.
AI는 이미 거대한 물결로 온 사회를 덮치기 시작했다. 이쯤 되면 본인이 인공지능에 관심이 있는지 없는지, 본인이 관련된 업무에 종사하는지의 여부는 더이상 중요하지 않다고 생각한다.
멍하니 있다가 휩쓸려버리고 싶지 않다면 더 늦기전에 서핑보드 위에서 균형을 잡는 방법부터라도 익히고, 파도에 올라탈 준비를 해야한다.
'Data > LLM' 카테고리의 다른 글
| LLAMA3 로컬 설치 실행 및 테스트 (1) | 2025.01.07 |
|---|---|
| 개발자와 CHATGPT (5) | 2024.12.29 |