Intro
무료 Gemini 2.5 API에서 Gemma 3로의 강제 이주기에서 Gemini 무료 티어가 대폭 축소되면서 Gemma 3로 이주했던 경험을 기록했다. 무료로 사용할 수 있는 상용 LLM API 의 선택 범위가 너무 좁다보니 성능손해를 보면서도 선택했고, 당시 추론 능력 차이로 인해 프롬프트 엔지니어링에 꽤 시간을 쏟아야 해 아쉬웠는데, 오늘은 Google의 Gemma 4 출시 소식을 들었다.
Gemma 4는 Gemini 3와 동일한 연구 기반으로 만들어진 오픈웨이트 모델로, 31B Dense와 26B MoE를 포함한 네 가지 크기로 제공되며 Apache 2.0 라이선스로 공개되었다. 특히 Gemma 3 대비 추론 능력이 크게 향상되었다는 점이 눈에 띄었다. 바로 기존 프로젝트에 모델명만 바꿔 테스트해보니 Gemma 3 때와는 결과가 차원이 달랐고, API를 Gemma 4로 전환하는 정도를 넘어 느낀바가 많았기에 글을 정리해본다.
테스트
Rate Limit
google AI studio에 접속해 Rate Limit 을 확인해보니 Gemma 4도 추가가 되어 있었다. 경량모델답게 Gemma3 때와 동일한 매우 관대한 정책을 취하고 있다. gemini api를 쓰다가 한번 호되게 당한적이 있기 때문에 Rate Limit이 계속 유지될거라는 기대는 하지 않지만 그래도 그때와 다르게 Gemma는 경량모델이며 공개된 모델이기 때문에 전환에 부담이 없다.
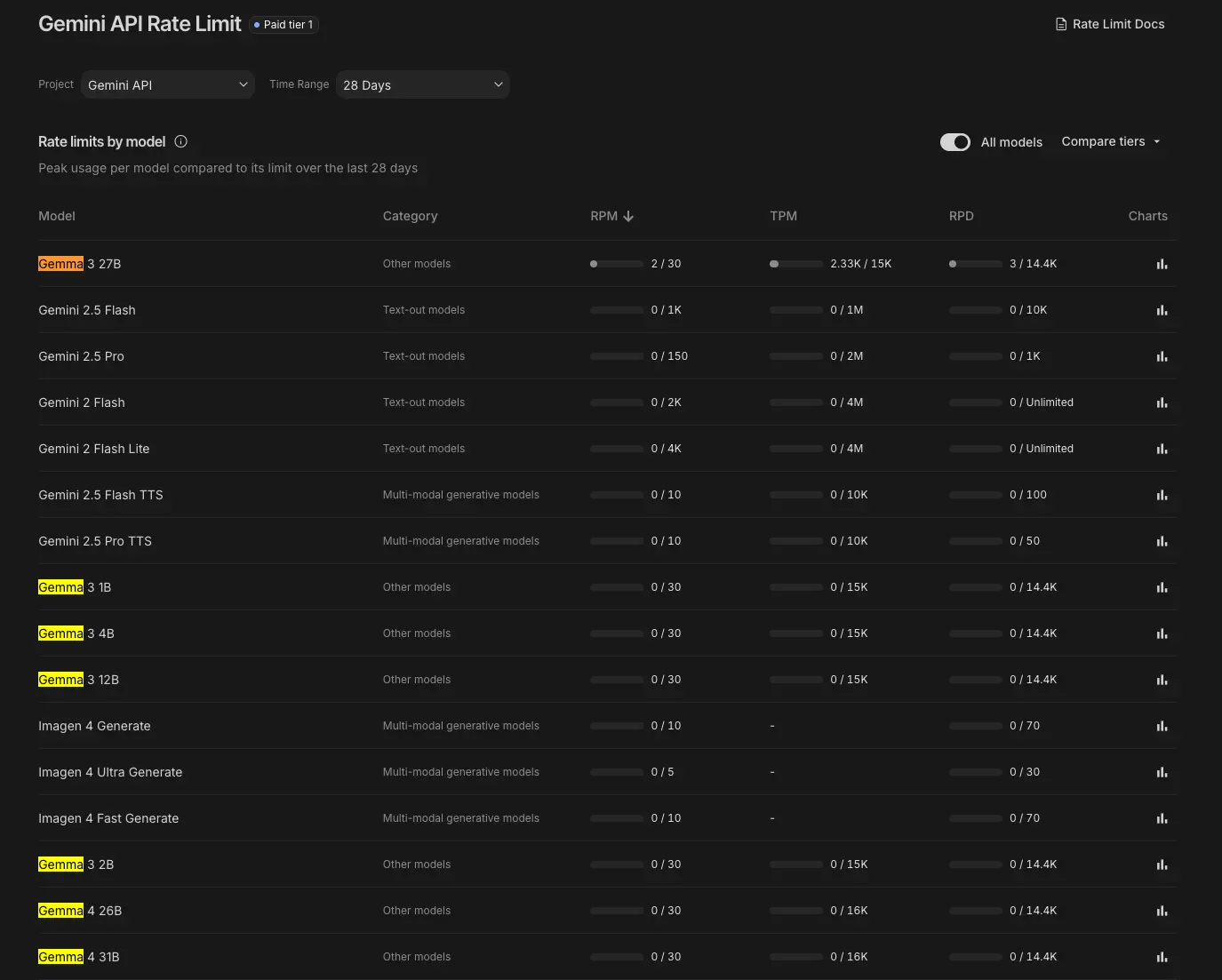
https://aistudio.google.com/app/rate-limit
RPM 30, TPM 16K 로 무료 Gemini API 에서는 Gemma4의 256K Context window를 모두 사용해볼 수는 없다.
가볍고 단순한 작업을 돌려보기엔 충분하며 모델 크기별로 쿼터가 별도로 돌기 때문에 26B, 31B를 번갈아가며 사용해도 된다.
gemma3 API 사용프로젝트
gemma3 API를 사용하는 프로젝트에서 그대로 gemma4 로 변경하여 테스트코드들을 돌려보았다. 단순하게 gemma-3-27b-it 를 gemma-4-31b-it 로 변경하는 것 만으로 즉시 모델이 변경되기 때문에 매우 편하다.
private fun makeService(): ScheduleTimeParsingService {
val timeout = Duration.ofMinutes(2)
val httpClient = HttpClient.create()
.responseTimeout(timeout)
val requestFactory = ReactorClientHttpRequestFactory(httpClient).apply {
setConnectTimeout(timeout)
setReadTimeout(timeout)
}
val connector = ReactorClientHttpConnector(httpClient)
val openapi = OpenAiApi
.builder()
.apiKey(apiKey)
.baseUrl("https://generativelanguage.googleapis.com/v1beta/openai/")
.completionsPath("/chat/completions")
.restClientBuilder(
RestClient.builder()
.requestFactory(requestFactory)
)
.webClientBuilder(
WebClient.builder()
.clientConnector(connector)
)
.build()
val chatOption = OpenAiChatOptions
.builder()
.model("gemma-4-31b-it")
// .model("gemma-3-27b-it")
.temperature(0.0)
.build()
val chatModel = OpenAiChatModel
.builder()
.openAiApi(openapi)
.defaultOptions(chatOption)
.build()
val service = ScheduleTimeParsingService(
chatModel = chatModel,
jsonMapper = jsr310JsonMapper()
)
return service
}주의사항
다만 추론능력이 생기며 처리시간이 좀 더 걸리기 때문에 timeout은 기존보다 늘려줘야 했다. 테스트 코드를 돌려 보았는데 응답에 10초가 넘게 걸리면서 타임아웃 계속해서 발생했다.
또한 응답에 추론블럭이 포함되기때문에 기존의 데이터 정규화 관련 코드는 수정이 좀 필요했다. 그래도 추론블럭 안의 텍스트를 보면 추론 성능이 좋아진게 눈에 띄어서 성능을 기대해 보아도 괜찮겠다는 생각이 벌써부터 들었다.
15:56:26.284 [Test worker] WARN com.tistory.shanepark.dutypark.schedule.timeparsing.service.ScheduleTimeParsingService -- Failed to parse JSON: <thought>* Input: `{"date":"2025-02-28","content":"2:50 산본제일 진료"}`
* Task: Extract time from Korean schedule text.
* Output: JSON only.
* Content: "2:50 산본제일 진료"
* Time marker: `2:50` (contains `:`)
* Hour: 2
* Minute: 50
* Date: 2025-02-28
* Rule: "Default hours: 1-6 = PM, 7-11 = AM (but consider activity context)"
* Hour is 2.
* Activity: "산본제일 진료" (Medical treatment/clinic visit).
* Medical clinics usually operate during the day/afternoon, not at 2 AM.
* Therefore, 2:50 should be interpreted as PM (14:50).
* `result`: true (Normal case)
* `hasTime`: true (Time marker `2:50` found)
* `startDateTime`: "2025-02-28T14:50:00"
* `endDateTime`: "2025-02-28T14:50:00" (No range specified)
* `content`: "산본제일 진료" (Strip the time expression "2:50")
* Is it a logical error? No.
* Is it an impossible hour? No.
* Is it multiple times? No.
* Is it a relative time? No.
{"result":true,"hasTime":true,"startDateTime":"2025-02-28T14:50:00","endDateTime":"2025-02-28T14:50:00","content":"산본제일 진료"}
여러가지 합리적인 추론을 단계적으로 해간다. Gemma3는 못했던 것이다.
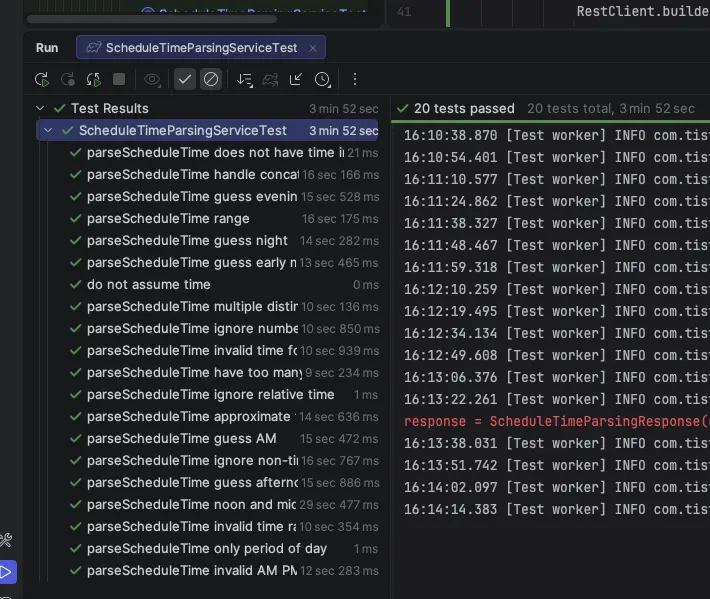
추론으로 인해 각 테스트가 10초 이상 걸렸지만, 최종 테스트는 문제 없이 통과했다.
Gemini 2.5에서 Gemma3 로 넘어갈때 깨졌던 테스트코드로 마주했던 수많은 빨간불이 기억난다. gemma4는 그때를 비웃기라도 하듯 한번에 모두 파란불이 들어왔다. 과거에 Gemma3 때문에 수없이 깎아냈던 프롬프트 엔지니어링을 생각하면 상당히 감동스러운 순간이다.
추가로 추론으로 인해 응답이 늦어지다보니 RPM / TPM 이 이전처럼 빠듯하게 돌아가지는 않아서 좋은점도 있다. 병렬로 돌리지 않는다면 딱히 limit에 걸릴 것 같지는 않다.
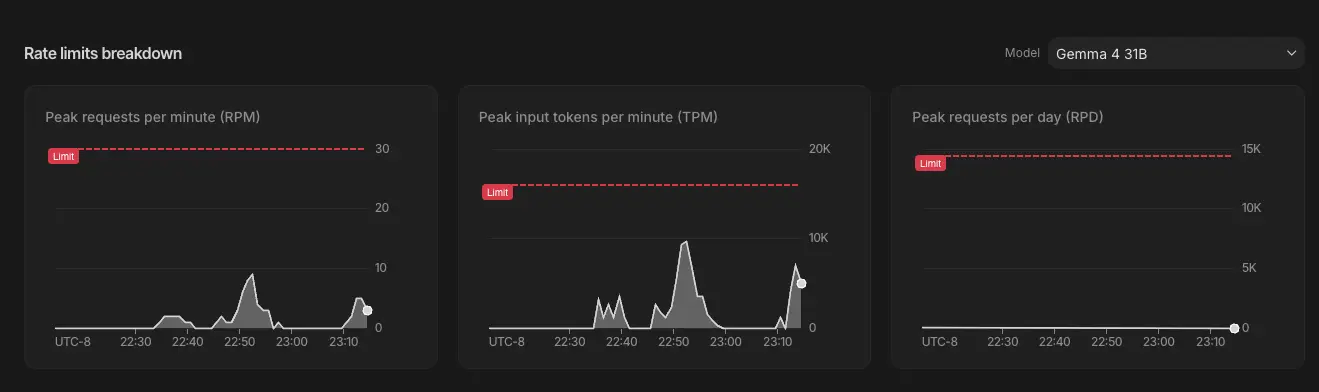
Rate limit에 여유가 있다.
Ollama
ollama 및 Hugging Face 에도 공개 되어있어 로컬에서 돌려볼 수 있다.
ollama run gemma4:e4b
ollama 최신 버전이 필요하다.
로컬 LLM에도 관심이 많아 ollma 에서 바로 돌려보았다.
일단 m5 pro 24GB 맥북에서 31b 를 시도해봤는데 어떻게든 돌아가긴 하는데 tps가 터무니없이 안나온다. 적어도 48G 이상의 통합메모리가 있어야 쓸만할 것 같다. 그래서 e4b 로 다시 시도해보았는데 여기에서 E 는 Effective Parameters 를 뜻한다. ollama에서의 모델 사이즈도 26b의 18GB의 절반인 9.6GB 에 달하기 때문에 4b라고 무시할건 아니다.
e4b로 변경하자 m5 pro 24GB 맥북에서 일반 상용 API 들 쓰는 것 이상의 좋은 TPS가 나왔으며 Memory Pressure 도 낮은 수준이 유지되었다.
TPS 뿐만 아니라 응답 품질도 굉장히 만족스러웠다. 이정도 성능이 로컬에서 이정도로 가볍고 빠르게 돌아간다는게 믿기지 않는다.
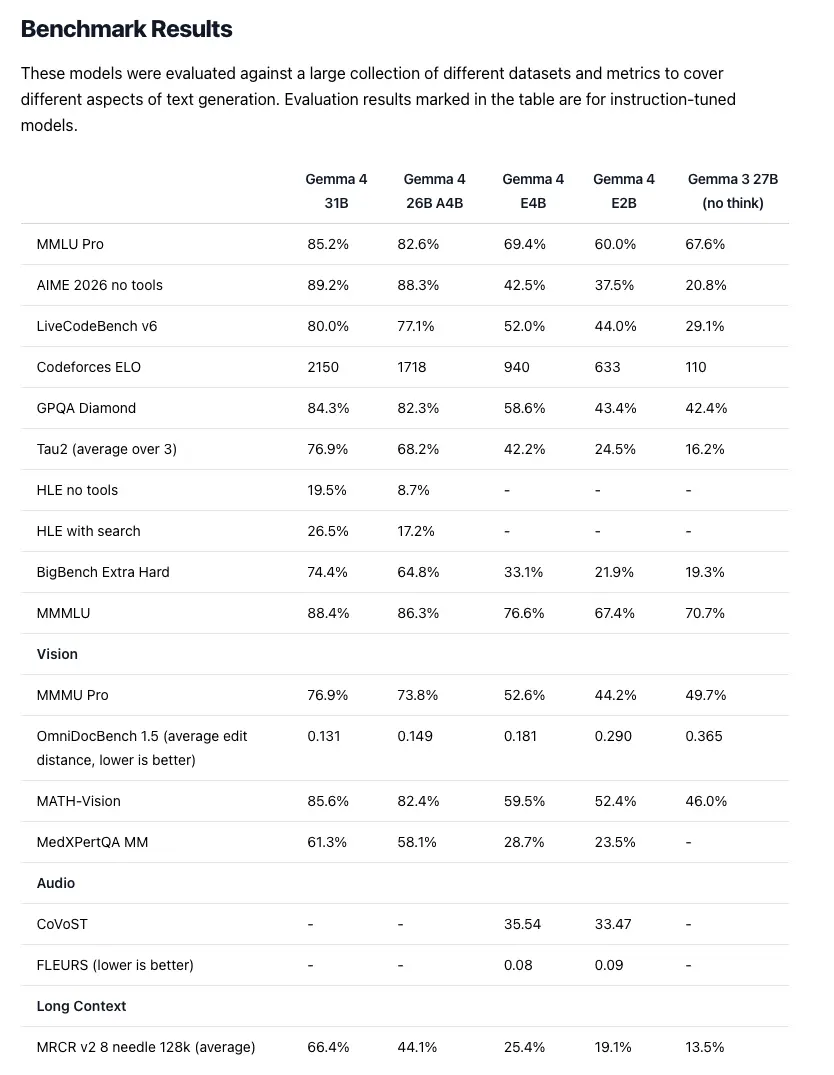
벤치마크 결과도 Gemma3 와 비교하는게 실례일 정도로 크게 차이가 났다. Gemma4 E2B 모델조차 Gemma 3 27B 모델을 압도한다.
최근에 qwen3.5에서 큰 감동을 받았었는데 앞으로 로컬 모델로 qwen과 함께 애용하게 될 듯 하다. 이정도면 무료 API 사용 못하게 되더라도 그냥 로컬에서 돌려버리면 그만이겠다.
마치며
AI시대가 왔다고 하지만 진짜 생활에서는 프론티어모델 못지않게 경량모델들의 성능이 더 중요할거라고 생각한다. 개인 핸드폰, 노트북을 넘어 조금만 지나면 청소기, 세탁기, 건조기, 식기세척기, 로봇청소기 등의 가전들이 스스로 생각하고 진짜 AI가 될날이 아주 가까워졌다.
실생활에 인공지능을 접목시키고 싶은 분야가 너무 많았는데 앞으로의 일들이 정말 기대된다.
References
'Data > LLM' 카테고리의 다른 글
| 우분투에 Openclaw 설치하기 및 후기 (0) | 2026.03.26 |
|---|---|
| Codex 서브에이전트 최대 스레드 수 늘리기 (0) | 2026.03.20 |
| Codex 서브에이전트 도입 소식 및 활용팁 (0) | 2026.03.18 |
| Playwright MCP 멀티 에이전트 경합 문제해결 (0) | 2026.01.21 |
| 무료 Gemini 2.5 API에서 Gemma 3로의 강제 이주기 (0) | 2026.01.12 |