Intro
코드를 작성하다 보면 switch 문으로 작성할지, 혹은 if-else 를 사용할 지 고민될때가 자주 있습니다.
개인적으로는 보통 elseif 가 두개이상 붙게되는 시점부터는 보통 코드의 가독성이나 문맥에 따라 switch 문을 사용 하려 하고 있습니다.
if.java
void function(String args) {
if ("a".equals(args)) {
// A logic
} else if ("b".equals(args)) {
// B logic
} else {
// C logic
}
}switch.java
void function(String args) {
switch (args) {
case "a": // A logic
break;
case "b": // B logic
break;
default: // C logic
break;
}
}
동일 로직에 대한 If-else 및 switch 의 예
if 블럭은 분기점이 늘어나면 늘어날 수록 코드를 읽기가 굉장히 피곤해지는데요, 코드가 처음 작성할 때 부터 분기가 많은 경우보다는 확장되면서 자연스럽게 분기가 늘어나는 일이 많다보니 if-else 문이 사용되는 경우가 꽤 잦은 편입니다.
자바 7 부터는 switch 문에서 String 객체도 사용 할 수 있게 되었는데요, 해당 API 문서에는 아래와 같은 설명이 작성되어 있습니다.
자바 컴파일러는 일반적으로 switch 문을 사용 할 때에 if-then-else 체이닝에 비해 더 효율적인 바이트 코드를 생성 합니다.
원문: The Java compiler generates generally more efficient bytecode from
switchstatements that useStringobjects than from chainedif-then-elsestatements.https://docs.oracle.com/javase/7/docs/technotes/guides/language/strings-switch.html
이에 따라 이번 글에서는 코드의 가독성 측면을 넘어서 JVM의 구현에서는 어떤식으로 if문보다 더 효율적인 바이트코드로 변환되는지를 알아보도록 하겠습니다.
Switch
switch문의 컴파일에 대해서는 아래의 oracle java specs를 참고 했습니다.
https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-3.html#jvms-3.10
문서에 따르면, switch문을 컴파일 할 때에는 tables witch혹은 lookup switch가 사용된다고 합니다. 보통은 처음접하는 분이 많은 생소한 개념일텐데요 차근차근 알아보겠습니다.
Tableswitch
table switch는 switch문의 케이스들이 대상 오프셋 테이블에 인덱스로 효율적으로 표시될 수 있을 때 사용합니다. 또한 스위치 표현식의 값이 유효한 인덱스의 범위를 벗어나는 경우에는 switch문에서의 default taget이 사용됩니다.
이해하기가 조금 어려울 수 있는데 코드를 함께 보면 조금 더 간단하게 이해 할 수 있습니다.
int chooseNear(int i) {
switch (i) {
case 0: return 0;
case 1: return 1;
case 2: return 2;
default: return -1;
}
}예를들어 위의 코드에서 case는 0,1,2 이기 때문에 0부터 시작한 offset 테이블로 간단하게 표현 할 수 있습니다. 그 외에 해당 범위가 벗어나는 경우에는 default target으로 넘어가게 되는데요, 이 코드는 아래와 같이 컴파일 됩니다.
Method int chooseNear(int)
0 iload_1 // 지역변수1(아규먼트i) 를 push
1 tableswitch 0 to 2: // 유효한 색인은 0~2
0: 28 // i 가 0일 경우, continue at 28
1: 30 // i 가 1일 경우, continue at 30
2: 32 // i 가 2일 경우, continue at 32
default:34 // 범위를 벗어날 경우, continue at 34
28 iconst_0 // i가 0 이므로 int constant 0을 push
29 ireturn // 반환
30 iconst_1 // i가 1 이므로 int constant 1을 push
31 ireturn // 반환
32 iconst_2 // i가 2 이므로 int constant 2을 push
33 ireturn // 반환
34 iconst_m1 // 그 외의 경우에는 상수 -1을 push
35 ireturn // 반환참고로 JVM의 tableswitch와 lookupswitch 명령은 int 데이터에서만 작동합니다.
byte, char, short 등의 값 타입에 대한 연산은 내부적으로 int로 승격되기 때문에 byte, char, short 중 하나로 evaluate 되는 switch 문 표현식 역시 int 타입으로 evaluate 되는 것 처럼 컴파일 됩니다.
그 말은 즉 만약 위에있는 chooseNear() 메서드가 int가 아닌 short 타입으로 작성되었다고 하더라도
short chooseNear(short s)
JVM은 동일한 JVM 명령을 생성 할 것입니다.
그 외의 숫자 타입들은 switch문 내에서 사용하기 위해서는 int 타입으로 범위를 좁혀 주어야만 합니다.
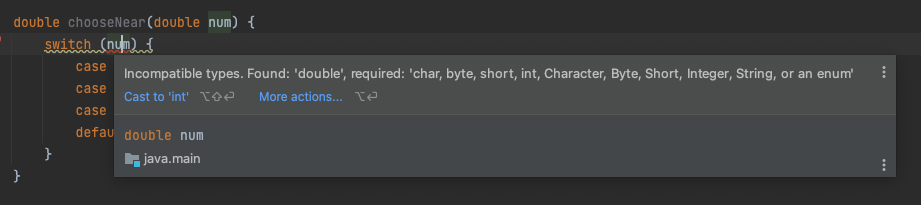
double 타입을 switch 문에 넣으려고 하면 char, byte, short, int, String 혹은 enum 타입만 가능하다는 에러가 나옵니다.
- 재밌는 사실은 tableswitch가 이름과는 어울리지 않게 18개 케이스 미만에서는 일련의 cmp/je (if나 goto문 같은) 로 번역되고 그 이상의 케이스에서만 assembly 레벨에서도 진정한 table switch로 작동한다고 합니다.
Lookupswitch
반면에 switch의 case 들이 드문드문 있을 경우에는 tableswitch 명령어의 테이블 표현은 공간적인 측면에서 비효율적이게 됩니다.
케이스가 -100, 0, 100 이렇게 있는데 -100 부터 100까지 201개의 공간을 만들어놓고 3개만 사용한다면 엄청난 메모리 낭비가 되는거죠.
다행히도 이럴때는 lookupswitch 명령이 대신 사용됩니다. lookupswitch 명령은 int key들과(-100, 0, 100과 같은 케이스) 테이블의 target offset 들과의 Pair를 만들어 둡니다. 그래서 lookupswitch 명령이 실행 되는 시점에 switch 표현식의 값이 테이블의 키들과 비교를 하게 되는데요. 만약 int keys중 하나가 표현식의 값과 일치한다면 관련된 target offset 으로 실행이 이어집니다.
반면 만약 어느 키도 매치되지 않는다면 tableswitch에서 범위를 벗어날때와 마찬가지로 default target 에서 실행을 이어가게 됩니다.
이번에도 예제 코드를 확인 해 보겠습니다.
int chooseFar(int i) {
switch (i) {
case -100: return -1;
case 0: return 0;
case 100: return 1;
default: return -1;
}
}
위의 코드는 아래와 같이 컴파일 됩니다.
Method int chooseFar(int)
0 iload_1
1 lookupswitch 3: // 이번에는 lookupswitch가 사용되었습니다.
-100: 36
0: 38
100: 40
default: 42
36 iconst_m1
37 ireturn
38 iconst_0
39 ireturn
40 iconst_1
41 ireturn
42 iconst_m1
43 ireturnJVM 스펙에서는 일반적인 선형적인 스캔 O(N) 보다는 더 효율적인 검색을 구현하기 위해 lookupswitch명령의 테이블이 key로 정렬 되어있어야 한다고 명시 하고 있습니다. 아마도 이진탐색등 보다 효율적인 검색 알고리즘을 사용하려는 것 이겠죠?
하지만 그럼에도 불구하고 단순히 범위검사를 수행하고 테이블에 인덱스 하는 Tableswitch 와는 대조적으로, lookupswitch는 key들 중에서 일치하는 항목을 검색 해야만 합니다.
따라서 tableswitch 명령이 공간이 허용되는 한 lookupswitch 보다 효율적인 것은 사실입니다.
Switch 문에서의 String
위에서 "JVM의 tableswitch와 lookupswitch 명령은 int 데이터에서만 작동합니다." 라고 언급을 짧게 했었는데, 그렇다면 JAVA 7에서 추가된 String의 Switch 문은 어떤 원리로 동작하는 걸 까요?
public static void main(String[] args) {
String s = "Bar";
switch (s) {
case "Foo":
System.out.println("Foo match");
break;
case "Bar":
System.out.println("Bar match");
break;
}
}위에서의 코드로부터는 아래와 같은 bytecode 조각이 생성됩니다.
INVOKEVIRTUAL java/lang/String.hashCode ()I
LOOKUPSWITCH
-2049557543: L2
-1984635600: L3
-1807319568: L4
이제 위에서 학습했기 때문에 bytecode가 어느 정도 더 눈에 잘 들어옵니다. 거기에 바이트코드에 적힌 힌트들을 보니 더욱 감이 잡힙니다.
확인해보니 String 의 경우에는 int 형태의 hashcode를 생성해 lookupswitch 명령을 사용하고 있었습니다.
hashcode 경우에는 case들이 더욱 규칙성 없이 드문 드문 떨어져 있기 때문에 tableswitch 대신 lookupswitch를 사용 하고 있습니다.
또한 L2, L3, L4 에 있는 바이트코드들을 확인 해 보면 String.equals 메서드를 호출 하고 있는데요, hashCode로 찾아왔기 때문에 String이 정말 같은지 확실하게 확인하는 작업이 더 필요 한 것 입니다.
if문보다 효율적인 이유
지금까지 switch 문의 동작 원리에 대해 충분히 알아보았으니 이제는 왜 switch문이 if문에 비해 더 효율적인지 이해 할 수 있습니다.
if-else문 chain의 경우에는 조건의 갯수에 대해 선형적인 연산이 필요합니다. 최악의 경우 n개의 조건문에 대해서 n개의 equals를 하나하나 전부 확인 해 보아야 하기 때문에 O(N)의 시간 복잡도가 필요합니다.
반면에 switch문의 경우에는 위에서 이미 한번 확인 했던 자바 코드를 예를 들면
public static void main(String[] args) {
String s = "Bar";
switch (s) {
case "Foo":
System.out.println("Foo match");
break;
case "Bar":
System.out.println("Bar match");
break;
}
}
Switch 문에서의 String 에서 확인 했던 java 코드
아래의 자바 코드와 비슷하게 동작 하게 됩니다.
final static int FOO_HASHCODE = 70822; // "Foo".hashCode();
final static int BAR_HASHCODE = 66547; // "Bar".hashCode();
public static void main(String[] args) {
String s = "Bar";
switch (s.hashCode()) {
case FOO_HASHCODE:
if (s.equals("Foo"))
System.out.println("Foo match");
break;
case BAR_HASHCODE:
if (s.equals("Bar"))
System.out.println("Bar match");
break;
}
}
완전히 동일한 바이트 코드가 된다고 할 수는 없지만, 디컴파일 해보면 같은 순서로 동작하는걸 확인 할 수 있습니다.
switch 문에서는 적절한 조건문으로 (거의) 바로 점프 하니 O(1) 의 시간복잡도라고 할 수 있습니다.
마치며
단순히 코드의 가독성 측면을 넘어서 switch 문이 가지는 장점에 대해 알아 보았습니다.
사실 if문의 갯수가 무지막지하게 늘어나는 거의 없기 때문에 메인 이벤트 루프에서 switch 대신 if문이 사용된다고 해도 코드 실행시간이 급격하게 나빠진다거나 하지는 않을 것으로 예상 됩니다.
지금까지 해 온 것 처럼 비즈니스 로직에서 코드의 가독성이나 문맥을 고려해 if문이나 switch 중 적절한 제어문을 선택하되, 일반적인 상황에서는 switch 문이 더 효율적으로 동작한다는 사실은 알고 있는것이 좋겠습니다.
이상입니다.
References
'Programming > Java' 카테고리의 다른 글
| Armeria 튜토리얼 따라해보기 (0) | 2022.08.20 |
|---|---|
| [Java] Optional 올바르게 사용하기 (0) | 2022.07.21 |
| [JAVA] zxing 활용해 QR코드 생성하기 (0) | 2022.06.30 |
| JAVA) 자바에서는 Call By Reference가 불가능 합니다. (0) | 2022.06.06 |
| JAVA) Date 를 LocalDateTime 으로, 혹은 그 반대로 변환하기 (0) | 2022.05.23 |