Intro
컬렉션을 사용할 때, 특히 중복을 허용하지 않는 Set을 사용할 경우, 우리는 보통 사용하는 클래스의 equals와 hashCode만 올바르게 오버라이드하면 된다고 생각한다. HashMap에서는 그랬을지 몰라도 TreeSet을 사용할 때는 상황이 조금 달라진다.
TreeSet은 내부적으로 요소를 정렬하는 과정에서 compareTo 메서드를 사용하는데, 이를 간과하면 문제가 발생할 수 있다. compareTo 메서드는 단순히 정렬만을 위한 것이 아니라, 중복을 체크하는 데도 사용되기 때문이다.
이 글에서는 TreeSet에 집어넣는 클래스의 equals, hashCode 뿐만아니라 compareTo에 대해서도 신경 써야 하는 이유에 대해 살펴본다.
문제 상황
TreeSet은 삽입된 데이터를 자동으로 정렬하고, 이를 통해 중복을 방지한다. 이 과정에서 compareTo 메서드를 사용하여 객체의 순서를 결정하는데, 이때 equals나 hashCode는 사용되지 않는다. 이를 제대로 이해하지 못하면, 객체의 상태나 값이 다름에도 불구하고 같은 객체로 처리되는 상황을 마주할 수 있다.
다음은 이러한 문제를 겪을 수 있는 User 클래스의 예시를 들어보았다.
static class User implements Comparable<User> {
private final UUID id = UUID.randomUUID();
private final String name;
private final int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof User user)) return false;
return Objects.equals(id, user.id);
}
@Override
public int hashCode() {
return Objects.hashCode(id);
}
@Override
public int compareTo(User other) {
return Integer.compare(this.age, other.age);
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
}위 코드는 id 필드가 동일한 객체는 동일한 객체로 간주되도록 equals와 hashCode를 오버라이드하고 있다. 하지만 compareTo는 정렬을 위해 오직 age 필드만을 기준으로 비교하고 있다. id만으로 동일성을 구분하는건 많이들 사용해 보았을 것이라 생각한다.
다음은 HashSet에 User 객체를 추가하고 contains 메서드를 호출하는 간단한 테스트 코드다.
@Test
public void hashSetTest() {
Set<User> hashSet = new HashSet<>();
hashSet.add(alice);
hashSet.add(bob);
hashSet.add(charlie);
hashSet.add(dave);
assertThat(hashSet.size()).isEqualTo(4); // success
}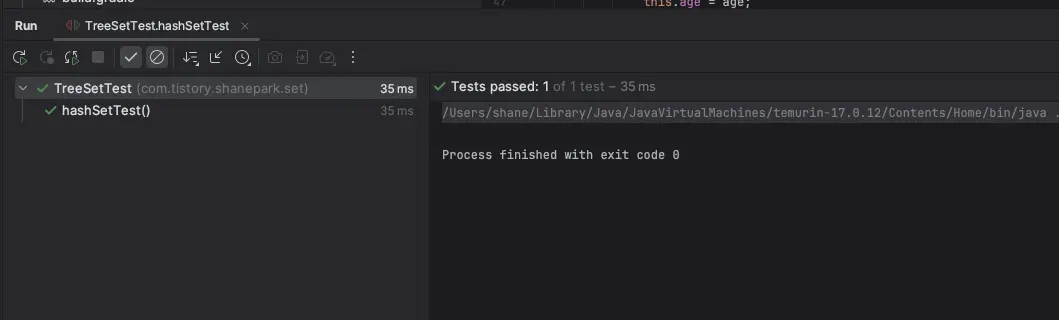
Set에 담긴 사람은 4명이고, 당연히 이 코드는 테스트를 통과한다.
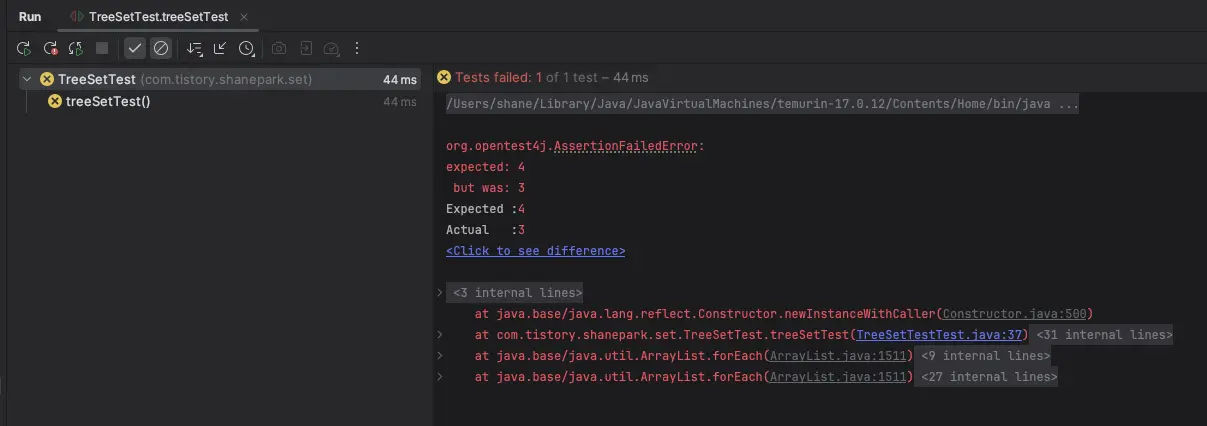
하지만 TreeSet 경우는 다르다. set 사이즈는 4가 나와야 할 것 같은데 그렇지 않았다.
@Test
public void treeSetTest() {
Set<User> treeSet = new TreeSet<>();
treeSet.add(alice);
treeSet.add(bob);
treeSet.add(charlie);
treeSet.add(dave);
assertThat(treeSet.size()).isEqualTo(4); // fail
}
TreeSet 을 출력해보면 아래와 같은 값이 나온다. Charlie 가 보이질 않는다. 기적의 확률을 뚫고 동일한 uuid를 가진 유저가 생성된 것일까?
[User{id=1e3e3cf7-2b2b-4302-8a8c-44ab7ea02513, name='Bob', age=25}, User{id=c8454284-0433-49e4-8c15-78a05eea1984, name='Dave', age=28}, User{id=02e2a994-7ace-4657-9dde-14fd755c06e4, name='Alice', age=30}]원인
TreeSet의 내부 동작을 이해하기 위해서는, 먼저 TreeSet이 데이터를 어떻게 저장하는지 살펴봐야 한다. TreeSet은 데이터를 저장할 때 TreeMap을 사용한다. 여기서 중요한 건, TreeMap이 데이터를 저장할 때 키의 순서를 결정하기 위해 compareTo 메서드를 사용한다는 점이다.
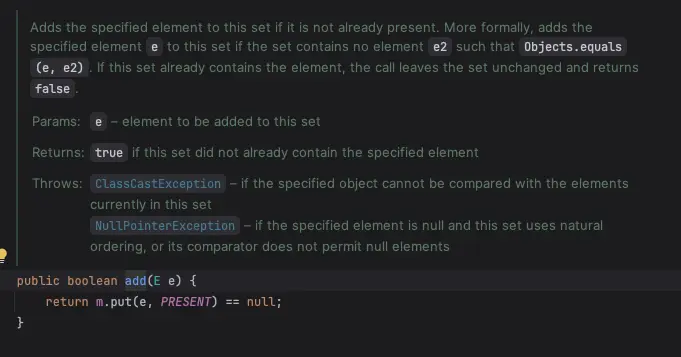
TreeSet의 add 메서드
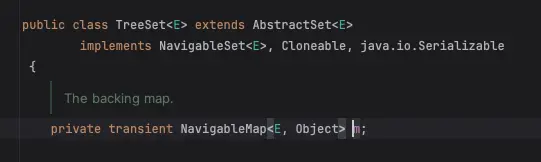
NavigableMap 을 내부적으로 사용하고 있는데,
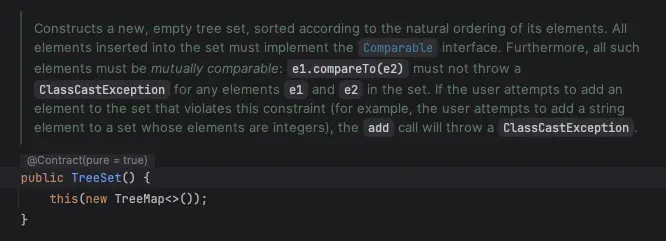
그 구현체는 TreeMap을 사용하고 있다.
위에서 알아 본 것처럼 TreeSet의 add 메서드를 타고 들어가면, 내부적으로 TreeMap의 put 메서드를 호출한다.
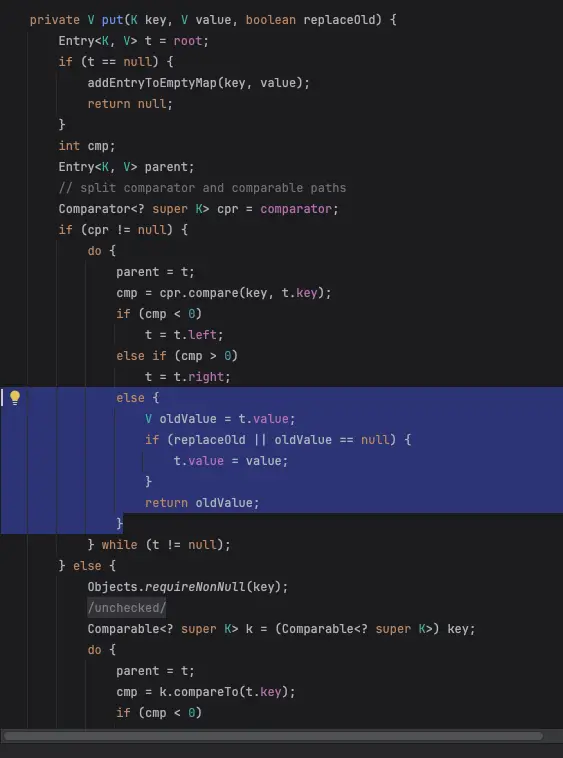
cmp변수에 compare 결과를 저장하고 이를 사용한다.
이 과정에서 compareTo가 사용되며, 비교 결과가 0일 경우, TreeMap은 새로운 데이터를 추가하지 않고 기존 데이터를 덮어쓴다. 즉, compareTo의 결과가 0이라면, 객체가 동일하다고 판단되고, 이는 equals나 hashCode와는 무관하게 동작한다.
그래서 마지막에 추가했던 Charlie 는 자신과 나이가 같은 Bob이 조금 먼저 추가되었기 때문에 동일객체로 판단되었다.
해결 방법
TreeSet에서 중복 문제를 해결하려면 compareTo 메서드를 신중하게 설계해야 한다. 특히, 객체의 고유성을 나타내는 모든 필드를 비교하는 것이 중요하다. 단순히 한두 개의 필드만으로 비교할 경우, 해당 필드 값이 같으면 서로 다른 객체라도 중복으로 처리된다.
예를 들어, 아래와 같이 User 클래스의 compareTo 메서드를 수정할 수 있다:
@Override
public int compareTo(User other) {
int ageComparison = Integer.compare(this.age, other.age);
if (ageComparison != 0) {
return ageComparison;
}
return this.id.compareTo(other.id); // age가 같으면 id로 추가 비교
}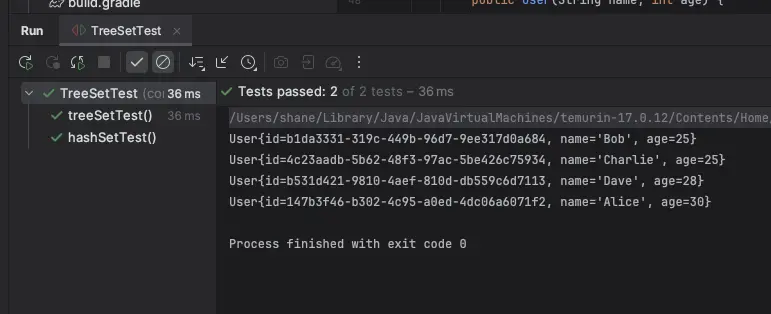
compareTo를 변경하면 테스트에 통과한다.
결론
TreeSet은 정렬된 순서를 유지하면서 중복을 허용하지 않는 매우 유용한 자료구조다. 내부적으로 Red-Black Tree 기반의 TreeMap을 사용하기 때문에 탐색, 삽입, 삭제 연산이 O(log n)의 효율적인 시간 복잡도를 가진다. 특히, TreeSet은 범위 기반 검색, 특정 값 이상의 최소값이나 이하의 최대값을 빠르게 찾는 등의 연산에서도 뛰어난 성능을 제공한다.
하지만 앞서 알아본 것 처럼 이를 제대로 사용하려면 compareTo 메서드를 적절하게 구현하는 것이 필수적이다. 단순히 equals와 hashCode만으로 중복 처리를 하던 HashSet과 달리, TreeSet에서는 compareTo의 결과가 중복 여부를 결정한다는 점을 명심해야 한다. 객체의 고유성을 반영하는 모든 필드를 비교하는 방식으로 compareTo를 작성하면, 예기치 못한 동작을 방지할 수 있을 것이다.
'Programming > Java' 카테고리의 다른 글
| Jsoup 활용한 웹페이지 요청 및 응답 파싱 (3) | 2024.11.11 |
|---|---|
| Java로 Tesseract를 활용한 OCR 구현하기 (2) | 2024.11.07 |
| [Java] Carriage return 그리고 Line feed (0) | 2024.01.05 |
| [Java] Serializable 인터페이스 이해하기 (0) | 2023.11.08 |
| [Maven/Gradle] 의존중인 모든 라이브러리의 라이센스 정보 불러오기 (0) | 2023.07.21 |