Intro
최근에 점심 도시락 메뉴가 종종 궁금한데 확인하러 일일히 들어가는 건 번거로워서 슬랙 봇을 만들까 생각을 했다.
점심 도시락 업체에서는 메뉴를 이미지로 웹사이트에 게시하고 있었고, 이 이미지를 가져오면 되는데, 이왕 하는 김에 텍스트로 변환까지 하면 더 좋겠단 생각이 들었다. 이를 위해 OCR(Optical Character Recognition) 기술을 활용했고, 그 과정에서 얻은 경험을 공유하려고 한다.
OCR은 이미지나 PDF에 포함된 텍스트를 기계가 인식하여 디지털 텍스트로 변환하는 기술이다. 스캔된 문서, 사진 속 텍스트 등을 데이터로 활용할 수 있게 해주며, 문서 디지털화, 자동 번역, 데이터 입력 자동화 등 다양한 분야에서 활용되고 있다.
Tesseract
Tesseract는 HP에서 아주 오래전 처음 개발되고, 구글에서 지원하고 있는 오픈 소스 OCR 엔진으로, 높은 정확도와 다국어 지원으로 널리 사용되고 있다. 특히 한국어 인식도 지원하여 활용하기가 좋다.
설치
macOS
bash
brew install tesseract
Ubuntu
bash
sudo apt install tesseract-ocr sudo apt install libtesseract-dev
Windows
Tesseract 공식 사이트에서 Windows용 설치 파일을 다운로드하여 설치한다. 설치 시 추가 언어 데이터를 선택하여 설치할 수 있다.
한국어 데이터
Tesseract는 언어별로 학습된 데이터가 필요하다. 한국어 인식을 위해서는 kor.traineddata 파일을 다운로드하여 tessdata 경로에 넣어주어야 한다.
세 가지 옵션이 있는데, 이번 프로젝트에서는 정확도가 중요해서 tessdata_best의 데이터를 사용했다. 요구사항에 맞게 적절한 학습 데이터를 고른다.
kor.traineddata파일을 다운로드하여 tessdata 경로에 넣어준다.
Java에서 Tesseract OCR 사용
위에서 설명한 Tesseract가 PC에 먼저 설치되어야 한다.
1. 라이브러리 추가
Maven
xml<dependency> <groupId>net.sourceforge.tess4j</groupId> <artifactId>tess4j</artifactId> <version>5.13.0</version> </dependency>
Gradle
gradleimplementation 'net.sourceforge.tess4j:tess4j:5.13.0'
이미지 전처리를 위해 OpenCV를 사용했으므로, 해당 라이브러리도 미리 추가해준다.
gradleimplementation 'org.bytedeco:javacv-platform:1.5.10'
2. tessdata 경로 설정
운영체제별로 tessdata 경로가 다르므로, 이에 맞게 설정해주어야 한다. 아래의 내용을 참고하면 된다.
javaprivate final String TESSDATA_PATH_LINUX = "/usr/share/tesseract-ocr/5/tessdata"; private final String TESSDATA_PATH_MAC = "/opt/homebrew/share/tessdata"; private final String TESSDATA_PATH_WINDOWS = "C:\\Program Files\\Tesseract-OCR\\tessdata";
Apple Silicon 맥북에서는 build.gradle 파일에 아래의 내용을 추가해줘야 했다.
groovytest { systemProperty "jna.library.path", "/opt/homebrew/opt/tesseract/lib" }
위 설정은 JNA(Java Native Access)가 Tesseract의 네이티브 라이브러리를 찾을 수 있도록 경로를 지정해주는 것이다. Apple Silicon 환경에서는 라이브러리 경로가 일반 Intel 맥과 다를 수 있으므로 이 설정이 필요하다.
3. 간단한 OCR 구현
우선 간단한 예제로 시작해보자. 이미지에서 텍스트를 추출하는 기본 코드다.
모든 운영체제에서 동작하도록 하려고 코드를 다소 복잡하게 작성하였으나, dataPath 각자의 OS에 맞게 넣어줘도 된다.
javaimport net.sourceforge.tess4j.Tesseract; import net.sourceforge.tess4j.TesseractException; import java.io.File; public class SimpleOCR { public static void main(String[] args) { Tesseract tesseract = new Tesseract(); String os = System.getProperty("os.name").toLowerCase(); if (os.contains("win")) { tesseract.setDatapath("C:\\Program Files\\Tesseract-OCR\\tessdata"); } else if (os.contains("mac")) { tesseract.setDatapath("/opt/homebrew/share/tessdata"); } else { tesseract.setDatapath("/usr/share/tesseract-ocr/5/tessdata"); } tesseract.setLanguage("kor"); try { String result = tesseract.doOCR(new File("sample.png")); System.out.println(result); } catch (TesseractException e) { e.printStackTrace(); } } }
위 코드는 sample.png 이미지 파일에서 텍스트를 추출하여 출력한다.
아래는 실제 텍스트 추출에 사용한 메뉴 사진이다.
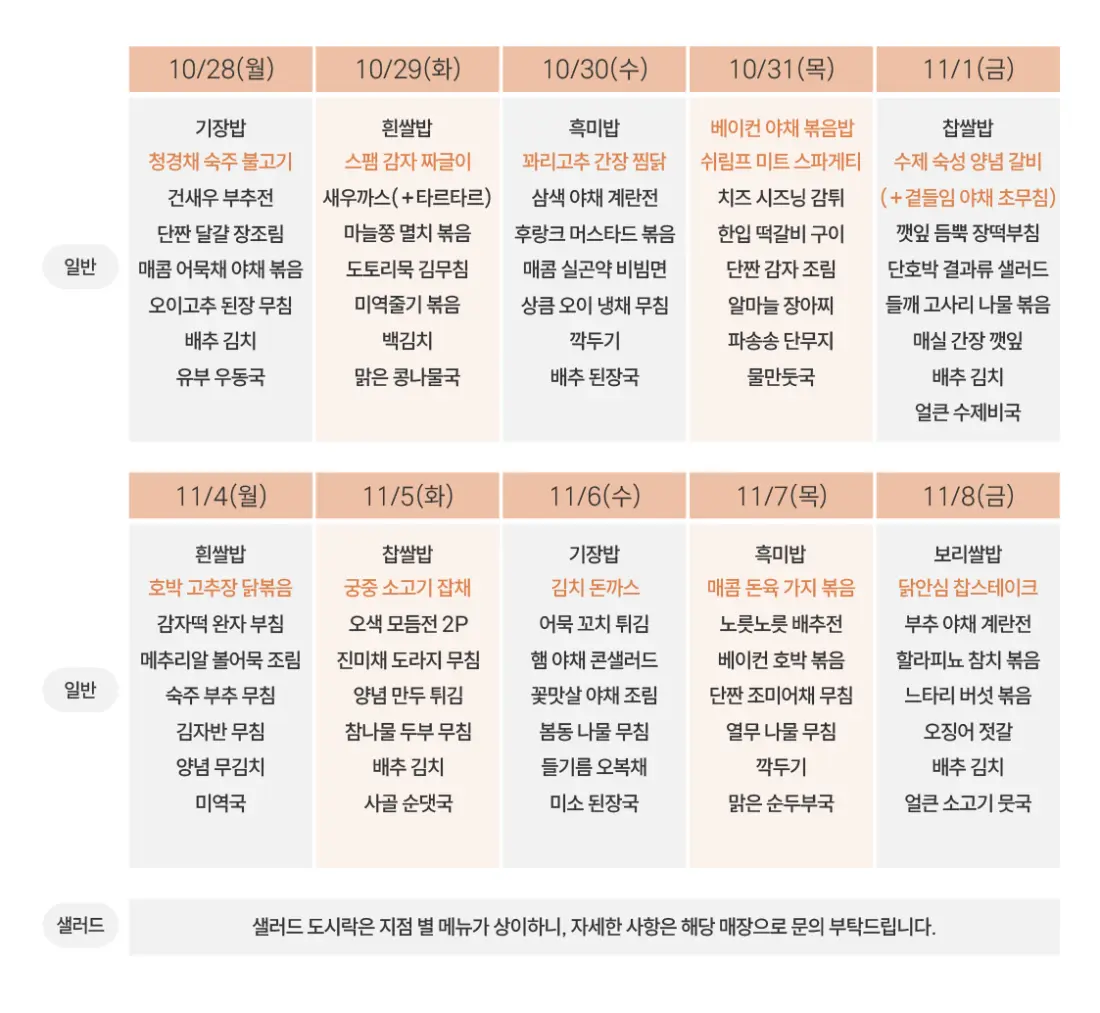
출처: 푸드박스 대전 유성점
코드 실행 결과는 아래와 같다.
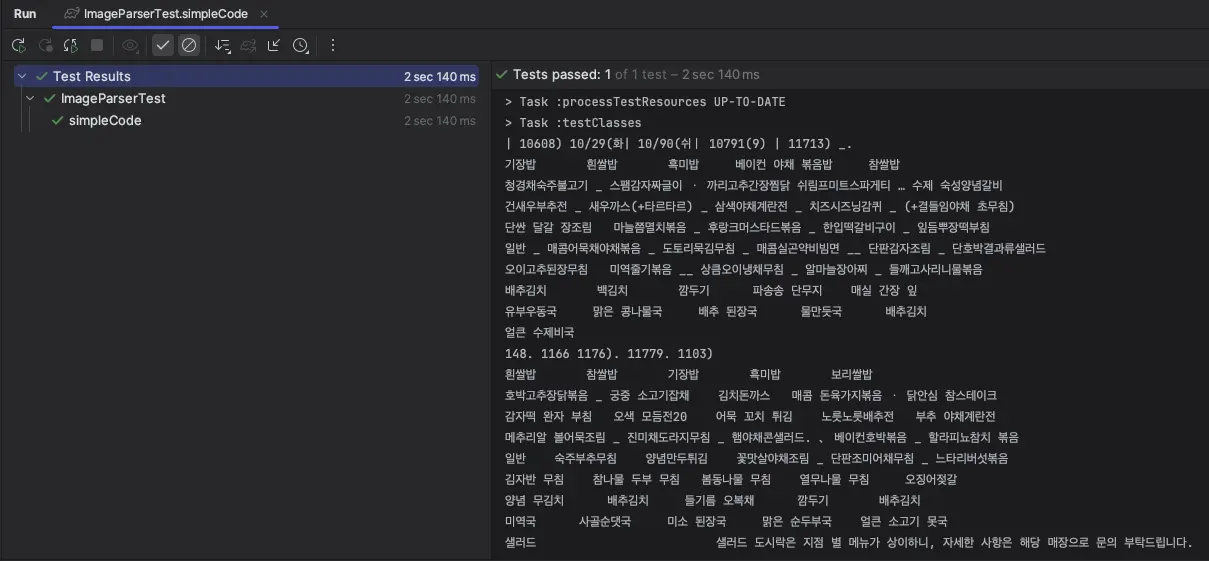
구조가 엉망이긴 하지만 일단 문자들이 잘 추출된 것이 확인된다.
4. 이미지 전처리
이미지의 해상도나 품질에 따라 OCR의 인식률이 크게 달라진다. 특히 작은 글씨나 노이즈가 많은 이미지의 경우 인식률이 저하될 수 있다.
이를 개선하기 위해 이미지 전처리가 필요하고, OpenCV를 사용했다.
javaimport org.bytedeco.opencv.opencv_core.*; import org.bytedeco.opencv.global.opencv_imgproc; import org.bytedeco.javacv.*; private BufferedImage preprocessImage(BufferedImage image) { try (OpenCVFrameConverter.ToMat converterToMat = new OpenCVFrameConverter.ToMat(); Java2DFrameConverter converterToFrame = new Java2DFrameConverter()) { Mat mat = converterToMat.convert(converterToFrame.convert(image)); Mat resizedMat = new Mat(); opencv_imgproc.resize(mat, resizedMat, new Size(mat.cols() * 2, mat.rows() * 2)); return converterToFrame.convert(converterToMat.convert(resizedMat)); } }
이미지를 확대하거나 명암비를 조절하여 인식률을 높일 수 있다. 상황에 따라 인식율이 달라지니 여러가지 테스트를 해보며 최적의 이미지를 찾아보자.
5. 특정 영역 OCR 및 데이터 구조화
이미지에서 전체가 아닌 특정 부분만 OCR이 필요할 때가 있다. 예를 들어, 메뉴 이미지에서 날짜와 메뉴 부분을 각각 추출해야 하는 경우다.
javaBufferedImage subImage = image.getSubimage(x, y, width, height); String text = tesseract.doOCR(subImage);
이렇게 이미지의 특정 영역을 잘라내어 OCR을 수행할 수 있다.
6. Whitelist와 Blacklist로 인식률 향상
Tesseract는 인식할 문자 집합을 지정하여 불필요한 문자의 인식을 배제할 수 있다. 이는 인식률 향상에 큰 도움이 된다.
예를 들어 날짜부분에는 숫자와 요일, 몇가지 기호만이 들어가며 메뉴부분에는 숫자가 들어갈 일이 거의 없다.
예제 이미지에서는 오색 모듬전 2P에 들어가있지만 2P가 메뉴에 있어 크게 의미 있는 텍스트는 아니다.
java// 날짜 부분 인식 시 tesseract.setVariable("tessedit_char_whitelist", "0123456789년월화수목금토일/()"); tesseract.setVariable("tessedit_char_blacklist", ""); // 메뉴 부분 인식 시 tesseract.setVariable("tessedit_char_whitelist", ""); tesseract.setVariable("tessedit_char_blacklist", "0123456789");
위 설정을 통해 특정 문자를 제외하거나 포함시켜 훨씬 나은 결과를 얻을 수 있다.
7. 전체 코드 구성
이제 샘플로 작성해 둔 전체 코드를 단계별로 살펴보자.
setPageSegMode는 Tesseract가 이미지를 어떻게 해석할지에 대한 모드를 설정하는 옵션이다. Tesseract는 다양한 PSM을 제공하며, 상황에 맞게 설정하면 인식률을 향상시킬 수 있다.
- PSM 1: 자동 페이지 세그멘테이션
- PSM 3: 완전 자동 페이지 세그멘테이션
- PSM 6: 균일한 블록의 단일 텍스트
- PSM 7: 단일 텍스트 줄
- PSM 11: 단일 수평 텍스트 줄
ImageParser.javaimport net.sourceforge.tess4j.Tesseract; import net.sourceforge.tess4j.TesseractException; import java.awt.image.BufferedImage; import java.io.File; import java.io.IOException; import java.util.*; import javax.imageio.ImageIO; import org.bytedeco.opencv.opencv_core.*; import org.bytedeco.opencv.global.opencv_imgproc; import org.bytedeco.javacv.*; public class ImageParser { private final Tesseract tesseract; private final int SINGLE_HEIGHT = 346; private final int HEADER_HEIGHT = 46; private final int GAP_SMALL = 4; final int DAY_PER_ROW = 5; final int singleWidth = 183; public ImageParser(String dataPath) { this.tesseract = new Tesseract(); tesseract.setDatapath(dataPath); this.tesseract.setLanguage("kor"); this.tesseract.setPageSegMode(6); } public List<ParsedMenu> parse(File file) throws TesseractException, IOException { final int marginLeft = 129; final int marginTop = 46; final int gapBig = 30; BufferedImage bufferedImage = ImageIO.read(file); List<ParsedMenu> days = new ArrayList<>(); days.addAll(readFiveDays(bufferedImage, tesseract, marginLeft, marginTop)); days.addAll(readFiveDays(bufferedImage, tesseract, marginLeft, marginTop + HEADER_HEIGHT + GAP_SMALL + SINGLE_HEIGHT + gapBig)); return days; } private BufferedImage preprocessImage(BufferedImage image) { try (OpenCVFrameConverter.ToMat converterToMat = new OpenCVFrameConverter.ToMat(); Java2DFrameConverter converterToFrame = new Java2DFrameConverter()) { Mat mat = converterToMat.convert(converterToFrame.convert(image)); Mat resizedMat = new Mat(); opencv_imgproc.resize(mat, resizedMat, new Size(mat.cols() * 2, mat.rows() * 2)); return converterToFrame.convert(converterToMat.convert(resizedMat)); } } private List<ParsedMenu> readFiveDays(BufferedImage image, Tesseract tesseract, int x, int y) throws TesseractException { List<ParsedMenu> days = new ArrayList<>(); ParseRegion region = new ParseRegion(x, y, singleWidth, HEADER_HEIGHT); for (int i = 0; i < DAY_PER_ROW; i++) { String date = readImagePartHeader(image, tesseract, region); days.add(new ParsedMenu(date)); region.addX(singleWidth + GAP_SMALL); } region = new ParseRegion(x, y + HEADER_HEIGHT + GAP_SMALL, singleWidth, SINGLE_HEIGHT); for (int i = 0; i < DAY_PER_ROW; i++) { String menu = readImagePartMenu(image, tesseract, region); days.get(i).setMenu(menu); region.addX(singleWidth + GAP_SMALL); } return days; } private String readImagePartMenu(BufferedImage image, Tesseract tesseract, ParseRegion region) throws TesseractException { tesseract.setVariable("tessedit_char_whitelist", ""); tesseract.setVariable("tessedit_char_blacklist", "0123456789"); return readImagePart(image, tesseract, region); } private String readImagePartHeader(BufferedImage image, Tesseract tesseract, ParseRegion region) throws TesseractException { tesseract.setVariable("tessedit_char_whitelist", "0123456789년월화수목금토일/()"); tesseract.setVariable("tessedit_char_blacklist", ""); return readImagePart(image, tesseract, region); } private String readImagePart(BufferedImage image, Tesseract tesseract, ParseRegion region) throws TesseractException { BufferedImage subImage = image.getSubimage(region.getX(), region.getY(), region.getWidth(), region.getHeight()); subImage = preprocessImage(subImage); return tesseract.doOCR(subImage) .replaceAll("\n\n", "\n"); } }
ParseRegion.javaimport lombok.Getter; @Getter public class ParseRegion { private int x; private int y; private int width; private int height; public ParseRegion(int x, int y, int width, int height) { this.x = x; this.y = y; this.width = width; this.height = height; } public void addX(int i) { x += i; } }
ParsedMenu.javaimport lombok.Getter; import java.util.ArrayList; import java.util.List; @Getter public class ParsedMenu { private final String date; private final List<String> menus = new ArrayList<>(); public ParsedMenu(String date) { this.date = date.replaceAll("\n", ""); } public void setMenu(String menu) { for (String m : menu.split("\n")) { m = m.trim(); if (!m.isEmpty()) { menus.add(m); } } } @Override public String toString() { return String.format("<%s>\n%s\n", date, menus.toString()); } }
ImageParserTest.javaimport org.junit.jupiter.api.BeforeEach; import org.junit.jupiter.api.Test; import net.sourceforge.tess4j.TesseractException; import java.io.File; import java.io.IOException; import java.util.List; import static org.assertj.core.api.Assertions.assertThat; class ImageParserTest { private final String TESSDATA_PATH_LINUX = "/usr/share/tesseract-ocr/5/tessdata"; private final String TESSDATA_PATH_MAC = "/opt/homebrew/share/tessdata"; private final String TESSDATA_PATH_WINDOWS = "C:\\Program Files\\Tesseract-OCR\\tessdata"; ImageParser parser; @BeforeEach void setUp() { String os = System.getProperty("os.name").toLowerCase(); String dataPath; if (os.contains("win")) { dataPath = TESSDATA_PATH_WINDOWS; } else if (os.contains("mac")) { dataPath = TESSDATA_PATH_MAC; } else { dataPath = TESSDATA_PATH_LINUX; } parser = new ImageParser(dataPath); } @Test void parse() throws IOException, TesseractException { File file = new File("메뉴.png"); List<ParsedMenu> parsedMenu = parser.parse(file); System.out.println("parsedMenu: " + parsedMenu); assertThat(parsedMenu).hasSize(10); assertThat(parsedMenu.get(0).getDate()).isEqualTo("10/28(월)"); } }
코드를 실행하여 같은 이미지를 분석한 결과는 아래와 같다.
의미없는 문자들의 나열이 아닌 구조화된 텍스트가 완성되었다.
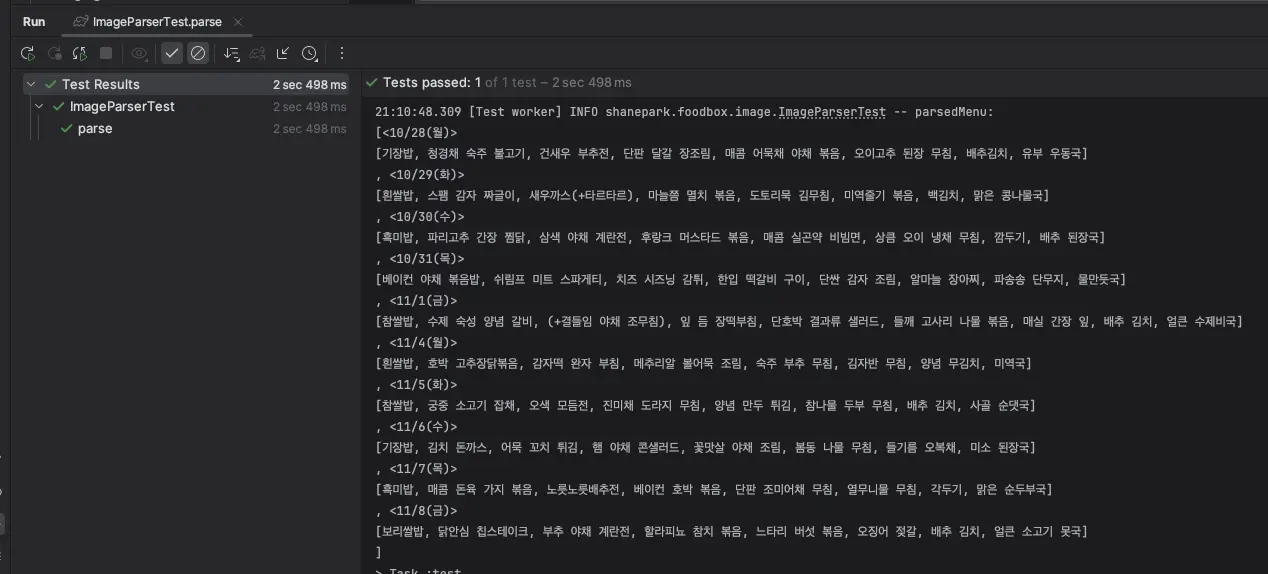
물론 자세히 보면 잘못 인식한 텍스트가 전혀 없는건 아니지만 전보다 훨씬 낫다.
인식율을 높이려면 이미지 전처리나 문자 데이터 훈련 등의 방법을 동원할 수 있다.
결론
이번 글에서는 Tesseract를 활용하여 Java에서 OCR을 구현하는 방법을 단계별로 알아보았다.
OCR을 적용하면서 많은 시행착오가 있었는데, 비슷한 문제를 해결하려는 분들께 도움이 되었으면 한다.
끝
'Programming > Java' 카테고리의 다른 글
| Gradle Wrapper 버전이 낮아서 JDK 21 지원을 안한다면 (0) | 2024.11.20 |
|---|---|
| Jsoup 활용한 웹페이지 요청 및 응답 파싱 (3) | 2024.11.11 |
| TreeSet에서 객체를 구별할 때 equals와 hashCode만으로는 충분하지 않다 (0) | 2024.09.29 |
| [Java] Carriage return 그리고 Line feed (0) | 2024.01.05 |
| [Java] Serializable 인터페이스 이해하기 (0) | 2023.11.08 |