Intro
Jsoup은 HTML 파싱을 위한 Java 라이브러리로, 웹페이지의 HTML을 가져와 파싱하고 조작할 수 있다. CSS 셀렉터를 이용해 원하는 요소를 선택할 수 있어서, 웹 스크래핑과 같은 작업에 유용하다.
이전 글에서 이미지 파일을 대상으로 OCR 하는 방법에 대해 알아보았는데, 이번에는 OCR의 대상이 되는 이미지를 직접 웹페이지에서 찾아오는 방법을 알아보도록 한다.
실습
jsoup 추가
gradle
implementation 'org.jsoup:jsoup:1.15.3'maven
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
HTTP요청
간단하게 http 요청으로 웹페이지의 응답을 받아오는 예시를 작성해보겠다.
JDK 11 에서부터는 java.net.http.HttpClient가 생겨서 그나마 간단해졌지만, 그 전까지는 까다로운 HttpURLConnection 사용해서 연결을 수립해야 했다.
Jsoup은 간편하게 요청 후 응답을 받을 수 있는 API를 제공한다.
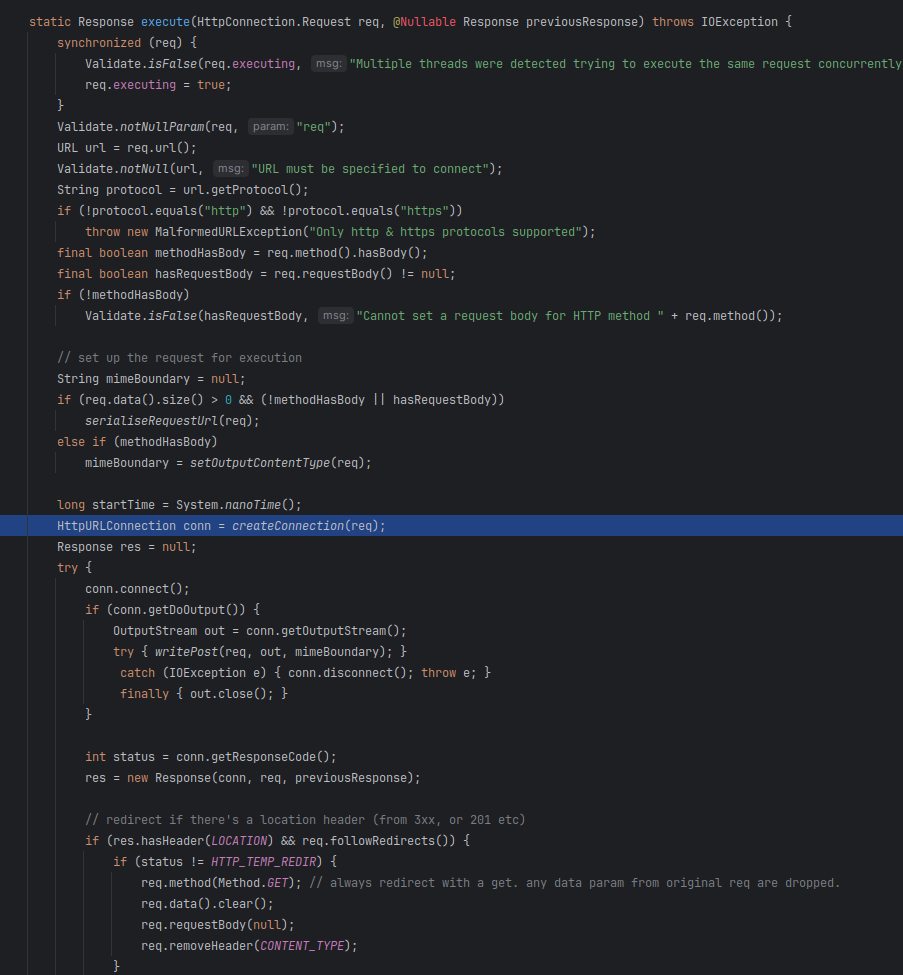
궁금함에 Jsoup의 코드를 살펴보니, HttpURLConnection으로 연결을 수립해 응답을 받아오고 있다.
@Test
public void simpleSoup() throws IOException {
Document doc = Jsoup.connect("https://shanepark.tistory.com").get();
System.out.println(doc);
assertThat(doc.text()).contains("Shane");
}코드를 작성하고 실행 해 본다.
방대한 양의 HTTP 응답이 출력된다.
필요한 부분 선택
Jsoup의 유용함은 이제부터 시작이다. css 셀렉터를 이용하여 필요한 부분을 선택 할 수 있다.
@Test
public void simpleSoup() throws IOException {
Document doc = Jsoup.connect("https://shanepark.tistory.com").get();
Element body = doc.body();
Elements titles = body.select(".article-content");
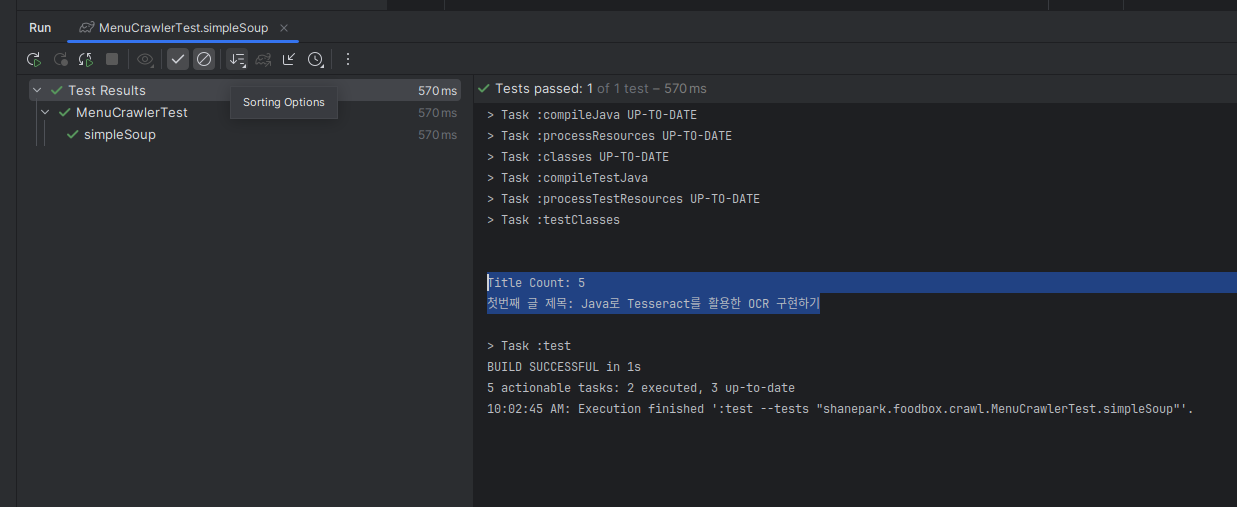
System.out.printf("\n\nTitle Count: %d\n", titles.size());
String firstTitleText = titles.getFirst().select(".title").text();
System.out.printf("첫번째 글 제목: %s\n\n", firstTitleText);
assertThat(titles.size()).isGreaterThan(0);
}
응용
특정 url에서 css 셀렉터를 활용해 원하는 이미지를 내려받는 코드를 작성해보자.
API를 먼저 설계 하고
public File downloadImage(String url, String cssSelector, int index) {
return null;
}테스트 코드를 먼저 작성해둔다.
class MenuCrawlerTest {
private final MenuCrawler menuCrawler = new MenuCrawler();
@Test
void downloadImage() throws IOException {
// Given
String url = "https://shanepark.tistory.com/510";
String cssSelector = ".article-view img";
// When
File image = menuCrawler.downloadImage(url, cssSelector, 0);
// Then
assertThat(image).exists();
assertThat(image).isFile();
// Open file
Desktop.getDesktop().open(image);
}
}실행하면 당연히 실패하는데, 이제부터 구현을 해서 테스트 코드가 작동하도록 하면 된다.
index를 넣은 이유는, css 셀렉터로 고른 이미지가 여러 개일 경우 그 중 몇 번째 것을 고를지 판단하기 위함이다.
마지막엔 다운받은 이미지를 직접 열어서 눈으로 확인할 수 있게 해 두었는데 이런 라인은 개발 할때만 편의를 위해 넣어두고 커밋하기 전에 제거하자.
차근 차근 구현을 각자 하면 되고 완성된 코드는 아래와 같다.
package shanepark.foodbox.crawl;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.IOException;
import java.nio.file.Files;
import java.util.UUID;
public class MenuCrawler {
public File downloadImage(String url, String cssSelector, int index) throws IOException {
Document document = Jsoup.connect(url).get();
Elements images = document.select(cssSelector);
if (images.size() <= index) {
throw new IllegalArgumentException("index is out of range");
}
Element image = images.get(index);
String imageSrc = getImageSrc(url, image);
return downloadFile(imageSrc);
}
private static String getImageSrc(String url, Element image) {
String imageSrc = image.attr("src");
if (!imageSrc.startsWith("http")) {
imageSrc = url + imageSrc;
}
return imageSrc;
}
private static File downloadFile(String imageSrc) throws IOException {
String fileName = imageSrc.substring(imageSrc.lastIndexOf("/") + 1);
File file = Files.createTempFile(UUID.randomUUID().toString(), fileName).toFile();
Connection.Response resultImageResponse = Jsoup.connect(imageSrc)
.ignoreContentType(true)
.execute();
try (BufferedInputStream bufferedInputStream = resultImageResponse.bodyStream()) {
bufferedInputStream.transferTo(new java.io.FileOutputStream(file));
}
return file;
}
}
최대한 Jsoup에 이미 있는 기능등을 활용 하였고, 실행 결과 원하는 이미지를 잘 받아왔다.
바로 메모리에서 이미지를 처리해야 하거나, 다운로드한 이미지를 즉시 다른 곳에서 사용하는 경우에는 InputStream을 반환해 직접 데이터를 처리하는 편이 좋겠다.
끝
'Programming > Java' 카테고리의 다른 글
| Gradle Wrapper 버전이 낮아서 JDK 21 지원을 안한다면 (0) | 2024.11.20 |
|---|---|
| Java로 Tesseract를 활용한 OCR 구현하기 (2) | 2024.11.07 |
| TreeSet에서 객체를 구별할 때 equals와 hashCode만으로는 충분하지 않다 (0) | 2024.09.29 |
| [Java] Carriage return 그리고 Line feed (0) | 2024.01.05 |
| [Java] Serializable 인터페이스 이해하기 (0) | 2023.11.08 |