Intro
6개월간의 육아휴직을 마치고 복직하니 회사에 많은 것이 달라져 있었다.
더 넓고 좋은 사무실로 이사했으며, 새로운 동료들도 여럿 입사하였다.
그중에 또 중요한 변화가 있으니, 점심 도시락 업체가 바뀌었다는 점이다. 이전 업체보다 더 맛있어졌고 반찬의 종류도 풍부해졌는데 특이한 점은 창의적인 메뉴가 많다는 것 이었다.
직원들은 식사 중에도 ‘이건 무슨 요리일까?’를 자주 묻고는 했지만 누구도 명확한 답을 내리지 못했다.
호기심에 도시락 업체명으로 검색해 보니 식단표가 업로드되는 웹페이지가 있었고, 매일 도시락 메뉴를 확인하는 건 번거로우니 자동으로 점심 메뉴를 출근 시간에 맞춰 알림으로 보내면 좋겠다고 생각했다.
본 글은 해당 서비스를 제작하면서 부딪쳤던 문제들과 해결방법을 기록하기 위해 작성했다.
구현
단순하게 메뉴를 바로 볼 수 있는 링크를 올려둔다거나, 메뉴 사진을 통째로 보여주는 쉬운 구현도 생각해 보았지만, 정형데이터로 가공하는 쪽이 나중에 데이터를 활용해 여러 가지 기능을 추가하기에도 유리하다고 생각해서 메뉴 이미지 크롤링 -> OCR -> 데이터 저장 -> 슬랙 발송 플로우로 진행하기로 정했다.
크롤링
다행히도 메뉴 이미지를 크롤링 해오는 건 어렵지 않았는데
- 메뉴가 올라오는 URL이 변하지 않음
- 항상 같은 element의 두번째 이미지로 메뉴가 업로드 됨. (첫 번째 이미지는 매장 소개)
- 크롤링을 금지하거나 방해하지 않음
위의 조건을 만족하기 때문에 필요할 때 및 일정 주기로 이미지를 요청하여 얻어올 수 있었다.
OCR
사실상 이 프로젝트의 성패를 정하게 될 핵심 포인트인데 단순하게 이미지에 있는 텍스트를 OCR 하는 것 뿐만 아니라 적절한 범위로 구역을 나누는 것도 만만치 않게 중요하다.
대표적인 오픈소스 OCR 소프트웨어는 Tesseract, EascyOcr, PaddleOCR 등이 있는데,
오수은님의 [OCR/AI] 2023년 최신판 OCR 8가지 API 비교평가 테스트 글을 참고해서 Tesseract를 먼저 테스트 해 보기로 정했다.
한글 모델을 다운받아야 하는데, 여러 가지 모델을 비교해 본 결과 적어도 도시락 메뉴 이미지에서는 https://github.com/tesseract-ocr/tessdata_best 에 있는 모델의 한국어 인식률이 가장 좋았다.
다만 tesseract를 별도로 설치해야 하는 번거로움이 있었는데 Dockerfile 에 아래의 내용을 추가하고 서버를 도커 컨테이너에서 돌리는 방식으로 해결했다.
# Install tesseract-ocr and necessary packages
RUN apt-get update && apt-get install -y \
tesseract-ocr \
wget \
&& rm -rf /var/lib/apt/lists/*
# Download the Korean trained data for Tesseract
RUN wget -O /usr/share/tesseract-ocr/5/tessdata/kor.traineddata \
https://github.com/tesseract-ocr/tessdata_best/raw/refs/heads/main/kor.traineddataApple Silicon Mac에서 JNA가 Tesseract를 찾지 못하는 문제도 있었는데
UnsatisfiedLinkError ... libtesseract.dylib ...
이건 jna.library.path에 경로를 등록 해주는 걸로 해결이 가능했다. 아래의 두 가지 방법 중 하나를 사용하면 되는데
System.setProperty("jna.library.path", "/opt/homebrew/opt/tesseract/lib");# build.gradle에 추가
test {
systemProperty "jna.library.path", "/opt/homebrew/opt/tesseract/lib"
}
bootRun {
systemProperty "jna.library.path", "/opt/homebrew/opt/tesseract/lib"
}이건 런타임에서 OS를 및 아키텍처를 확인하고 필요할 때만 등록하게 하기 위해, 코드로 아래와 같이 처리했다.
String os = System.getProperty("os.name");
log.info("OS: {}, arch: {}", os, arch);
if (os.contains("Mac") && arch.contains("aarch64")) {
System.setProperty("jna.library.path", "/opt/homebrew/opt/tesseract/lib");
}특이하게도 Tesseract는 이미지의 전처리가 정확도에 있어 굉장히 중요했는데, 전체 이미지를 한번에 OCR하는 것 보다, 여러 개의 이미지로 쪼개어 별도로 요청하는 게 더 좋은 결과를 반환했고
단순한 이미지 확대만으로도 더 나은 인식률을 얻어낼 수 있었다.
private BufferedImage preprocessImage(BufferedImage image) {
try (OpenCVFrameConverter.ToMat converterToMat = new OpenCVFrameConverter.ToMat();
Java2DFrameConverter converterToFrame = new Java2DFrameConverter()) {
Mat mat = converterToMat.convert(converterToFrame.convert(image));
Mat resizedMat = new Mat();
opencv_imgproc.resize(mat, resizedMat, new Size(mat.cols() * 2, mat.rows() * 2));
return converterToFrame.convert(converterToMat.convert(resizedMat));
}
}또한 블랙리스트, 화이트리스트를 추가하여 인식에 도움을 줄 수도 있었다.
private String readImagePartHeader(BufferedImage image, Tesseract tesseract, ParseRegion region) throws TesseractException {
tesseract.setVariable("tessedit_char_whitelist", "0123456789년월화수목금/()");
tesseract.setVariable("tessedit_char_blacklist", "");
return readImagePart(image, tesseract, region);
}
날짜와 요일만 나오는 헤더를 인식할 때는 whitelist를 이용해 정확히 검출해낼 수 있다.
여러모로 커스터마이징의 요소가 많기 때문에 전체적으로 이미지를 흑백처리 해본다거나 컬러셋을 조정해본다거나 하는식으로 여러가지 테스트가 꼭 필요하다.
구역 나누기

정형데이터로 변환하기 위해 OCR에 앞서 구역을 나누어 내는게 필수인데, 이게 쉽지 않다.
메뉴는 위의 그림과 같았는데, 매번 업로드 될 때 마다 형식은 비슷한데 왼편의 일반, 샐러드 글씨가 있을때도 없을때도 있었고 각 구역의 좌표 및 크기도 미묘하게 달라져서 일관된 방법을 쓸 수 없었다.
그래서 좌상단부터 이미지의 픽셀을 잃으면서 백그라운드가 아닌 좌표를 찾아내고
private Point findLeftTop(BufferedImage image, int width, int height) {
for (int y = 0; y < height; y++) {
for (int x = 0; x < width; x++) {
if (isNotBackgroundColor(image.getRGB(x, y))) {
return new Point(x, y);
}
}
}
throw new RuntimeException("Cannot find left top point");
}
private boolean isBackgroundColor(int rgb) {
int red = (rgb >> 16) & 0xFF;
int green = (rgb >> 8) & 0xFF;
int blue = rgb & 0xFF;
return red == 255 && green == 255 && blue == 255;
}그걸 토대로 각 표의 폭을 계산해낸 뒤
다행히도 항상 폭은 모든 10개의 일자가 동일했다.
private int calcSingleWidth(BufferedImage image, Point leftTop, int width) {
for (int x = leftTop.x; x < width; x++) {
if (isBackgroundColor(image.getRGB(x, leftTop.y))) {
return x - leftTop.x;
}
}
throw new RuntimeException("Cannot find single width");
}비슷한 방법으로 header(날짜)의 높이, 메뉴칸의 높이 및 각 칸의 좌표들을 모두 계산해낸다.
private ImageMarginData calcMargin(BufferedImage image) {
int width = image.getWidth();
int height = image.getHeight();
Point leftTop = findLeftTop(image, width, height);
int marginTop = leftTop.y;
int marginLeft = leftTop.x;
int singleWidth = calcSingleWidth(image, leftTop, width);
int gapSmall = calcGapSmall(image, leftTop, singleWidth, width);
int headerHeight = calcHeaderHeight(image, leftTop, height);
int singleHeight = calcSingleHeight(image, leftTop, headerHeight, height);
int gapBig = calcGapBig(image, height, leftTop);
return new ImageMarginData(
marginLeft,
marginTop,
singleWidth,
singleHeight,
headerHeight,
gapSmall,
gapBig
);
}이제 그걸 토대로 날짜 구역과 메뉴 구역을 포함한 총 DayRegion을 계산한다. 이렇게 계산한 구역대로 이미지를 잘라내고 전처리해서 Tesseract로 보내 문자열을 추출하면 끝이다.
final int DAY_PER_ROW = 5;
public List<DayRegion> calcParseRegions(BufferedImage image) {
ImageMarginData marginData = calcMargin(image);
List<ParseRegion> dateRegions = new ArrayList<>();
List<ParseRegion> menuRegions = new ArrayList<>();
// first row
int x = marginData.marginLeft();
int y = marginData.marginTop();
ParseRegion dateRegion = new ParseRegion(x, y, marginData.singleWidth(), marginData.headerHeight());
for (int i = 0; i < DAY_PER_ROW; i++) {
dateRegions.add(dateRegion);
dateRegion = dateRegion.addX(marginData.singleWidth() + marginData.gapSmall());
}
ParseRegion menuRegion = new ParseRegion(x, y + marginData.headerHeight() + marginData.gapSmall(), marginData.singleWidth(), marginData.singleHeight());
for (int i = 0; i < DAY_PER_ROW; i++) {
menuRegions.add(menuRegion);
menuRegion = menuRegion.addX(marginData.singleWidth() + marginData.gapSmall());
}
// Last row
y += marginData.headerHeight() + marginData.gapSmall() + marginData.singleHeight() + marginData.gapBig();
dateRegion = new ParseRegion(x, y, marginData.singleWidth(), marginData.headerHeight());
for (int i = 0; i < DAY_PER_ROW; i++) {
dateRegions.add(dateRegion);
dateRegion = dateRegion.addX(marginData.singleWidth() + marginData.gapSmall());
}
y += marginData.headerHeight() + marginData.gapSmall();
menuRegion = new ParseRegion(x, y, marginData.singleWidth(), marginData.singleHeight());
for (int i = 0; i < DAY_PER_ROW; i++) {
menuRegions.add(menuRegion);
menuRegion = menuRegion.addX(marginData.singleWidth() + marginData.gapSmall());
}
List<DayRegion> list = new ArrayList<>();
int totalDays = dateRegions.size();
for (int i = 0; i < totalDays; i++) {
list.add(new DayRegion(dateRegions.get(i), menuRegions.get(i)));
}
return list;
}이렇게 만든 프로토타입으로 한명의 직원만 슬랙 채널에 초대해 몇주동안 상황을 지켜 봤고, 정상적으로 작동한다고 판단 될 때마다 한명씩 초대 인원을 늘렸다.
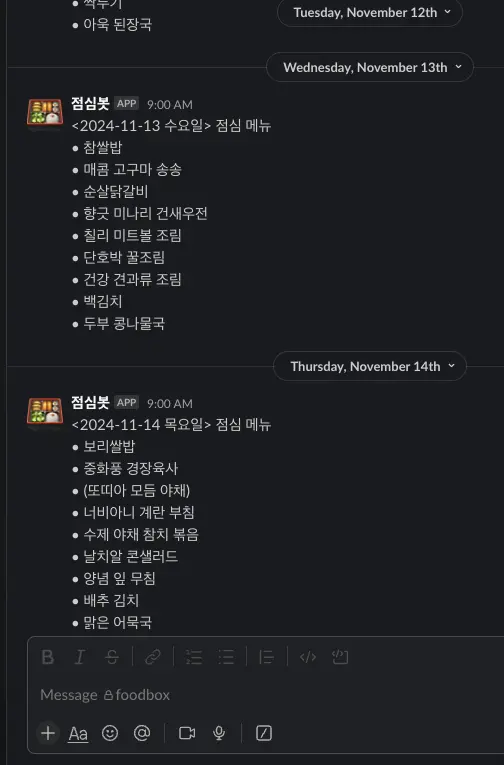
찹쌀밥 -> 참쌀밥
양념 깻잎 무침 -> 양념 잎 무침
OCR에서 약간의 부족함이 있었지만 기대했던 것 보다는 괜찮은 정확도를 보였고, 꼼꼼히 읽는게 아니라면 오타가 있는걸 모르기도 하고 전체적인 메뉴 파악에는 아무런 문제가 없었다.
문제해결
Naver OCR
몇주간 운영을 하며 지켜봤는데, 꾸준히 오타가 나는게 영 거슬렸다.
깍두기는 짝두기로, 깻잎은 쨋잎으로 해석하는데 항상 그런다. 어떤 메뉴인지 알아 볼 수는 있다지만..
직원들을 대상으로 도시락 메뉴를 보낼건데 명색에 프로그래머가 눈에 보이는 명백한 결함을 방치한다는게 영 자존심이 허락하지 않는다.
- 처음에는 tesstrain으로 훈련시켜서 여러가지 자주 오류가 나는 텍스트들을 해결해볼까 했는데 훈련데이터를 준비해서 훈련시키는게 만만치가 않은 작업이다. 이걸 이렇게까지 해야하나 싶어 탈락.
- PaddleOCR 등의 다른 오픈소스 OCR도 테스트 해 보았으나 Tesseract 보다 인식률이 떨어짐.
- LLM을 활용해서 오타로 판단되는 텍스트들은 알아서 수정하게끔 맡겨보았는데, "단짠 감자 조림" 같은 희한하지만 제대로 된 메뉴명들을 자기 멋대로 바꿔버려서 탈락.
그러다 문득 Naver Deview 2023 에 참석했을 때 들었던 세션 중 하나였던 네이버 OCR이 떠올랐다.

국제 대회에서 우승까지 했다고 들었는데 그 성능좀 보자~ 반신반의 하며 이미지들을 넣어 보았는데 모든 텍스트를 완벽하게 추출해냈다. 외부 연동 없이 최대한 심플하게 만들어내고 싶었지만 이정도 정확도를 그 누가 외면할 수 있을까? 바로 금액부터 확인해본다.
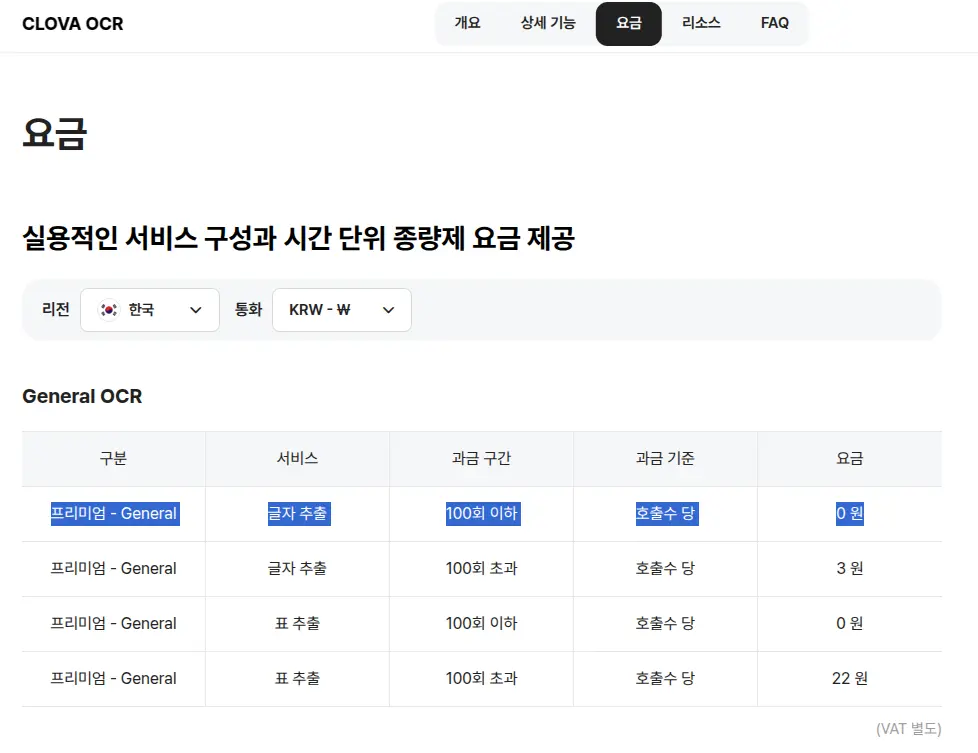
이 얼마나 아름다운 요금인가. 100회까지는 무료에, 100회를 넘긴다고 해도 건당 3원만 내면 된다.
2주 단위로 메뉴가 나오기때문에 한달에 최소 2번만 OCR을 요청하면 된다. 구역별로 이미지를 나누어 하루씩 구역을 잘라서 보낸다고 해도 월 22건 정도면 충분하다.
혹시 테스트 과정에서 100건을 넘길 수 있으니, 미리 응답결과를 파일로 저장해놓고 테스트 과정에선 실제 API 요청 대신 그 파일을 대신 읽도록 하면 된다.
참고로 OCR 요청은 POST 요청을 하면 되는데 꽤 복잡하다. RestTemplate 기준으로 아래와 같이 요청하면 된다.
@Component
@RequiredArgsConstructor
public class NaverClovaApi {
private final NaverClovaConfig naverClovaConfig;
private final RestTemplate restTemplate = new RestTemplateBuilder()
.setConnectTimeout(Duration.ofSeconds(5))
.setReadTimeout(Duration.ofSeconds(10))
.build();
public String clovaRequest(String base64Image) {
String requestBody = createRequestBody(base64Image);
HttpHeaders headers = createHeaders();
HttpEntity<String> request = new HttpEntity<>(requestBody, headers);
ResponseEntity<String> response = restTemplate.exchange(naverClovaConfig.getUrl(), POST, request, String.class);
return response.getBody();
}
private static String createRequestBody(String base64Image) {
JsonObject bodyJson = new JsonObject();
bodyJson.add("images", createImageArray(base64Image));
bodyJson.addProperty("lang", "ko");
bodyJson.addProperty("requestId", "string");
bodyJson.addProperty("resultType", "string");
bodyJson.addProperty("timestamp", Instant.now().toEpochMilli());
bodyJson.addProperty("version", "V1");
return bodyJson.toString();
}
private static JsonArray createImageArray(String base64Image) {
JsonArray images = new JsonArray();
JsonObject image = new JsonObject();
image.addProperty("format", "png");
image.addProperty("name", "menu");
image.addProperty("data", base64Image);
images.add(image);
return images;
}
private HttpHeaders createHeaders() {
HttpHeaders headers = new HttpHeaders();
headers.set("X-OCR-SECRET", naverClovaConfig.getSecretKey());
headers.set("Content-Type", "application/json");
return headers;
}
}
Clova OCR의 API 응답은 아래와 같은 방식으로 왔는데
{
"valueType": "ALL",
"boundingPoly": {
"vertices": [
{
"x": 530.0,
"y": 1060.0
},
{
"x": 579.0,
"y": 1060.0
},
{
"x": 579.0,
"y": 1081.0
},
{
"x": 530.0,
"y": 1081.0
}
]
},
"inferText": "단호박",
"inferConfidence": 1.0
},
{
"valueType": "ALL",
"boundingPoly": {
"vertices": [
{
"x": 575.0,
"y": 1060.0
},
{
"x": 665.0,
"y": 1060.0
},
{
"x": 665.0,
"y": 1080.0
},
{
"x": 575.0,
"y": 1080.0
}
]
},
"inferText": "오리훈제볶음",
"inferConfidence": 0.9997
},
{
"valueType": "ALL",
"boundingPoly": {
"vertices": [
{
"x": 685.0,
"y": 1071.0
},
{
"x": 719.0,
"y": 1071.0
},
{
"x": 719.0,
"y": 1091.0
},
{
"x": 685.0,
"y": 1091.0
}
]
},
"inferText": "철판",
"inferConfidence": 0.9998
},
{
"valueType": "ALL",
"boundingPoly": {
"vertices": [
{
"x": 718.0,
"y": 1071.0
},
{
"x": 753.0,
"y": 1071.0
},
{
"x": 753.0,
"y": 1091.0
},
{
"x": 718.0,
"y": 1091.0
}
]
},
"inferText": "사각",
"inferConfidence": 1.0
},
{
"valueType": "ALL",
"boundingPoly": {
"vertices": [
{
"x": 750.0,
"y": 1071.0
},
{
"x": 799.0,
"y": 1071.0
},
{
"x": 799.0,
"y": 1091.0
},
{
"x": 750.0,
"y": 1091.0
}
]
},
"inferText": "군만두",
"inferConfidence": 1.0
},inferConfidence가 아주 낮은 텍스트는 엉뚱한 이미지가 들어갔을 때가 많기 때문에 무시하도록 처리하였다.
또한 텍스트별로 x, y 좌표가 함께 제공되는데 먼저 작성한 코드에서 구역 나누기로 저장해 둔 날짜 및 메뉴 구역들이 있기 때문에
package shanepark.foodbox.image.domain;
public record ParseRegion(int x, int y, int width, int height) {
public ParseRegion addX(int i) {
return new ParseRegion(this.x + i, y, width, height);
}
public boolean contains(int x, int y) {
return this.x <= x && x <= this.x + width && this.y <= y && y <= this.y + height;
}
}위와 같이 구역에 속하는지를 검사해가며 파싱한 텍스트를 필요한 부분별로 구분해낼 수 있었다.
private static String buildMenuString(List<InferTextField> inferTextFields) {
int lastY = -1;
StringBuilder menuBuilder = new StringBuilder();
for (InferTextField inferTextField : inferTextFields) {
if (Math.abs(inferTextField.y - lastY) > 10) {
if (!menuBuilder.isEmpty()) {
menuBuilder.append("\n");
}
} else {
menuBuilder.append(" ");
}
menuBuilder.append(inferTextField.inferText);
lastY = inferTextField.y;
}
return menuBuilder.toString();
}잘 나누어낸 텍스트들은 메뉴 스트링을 다시 구성해 낼 때에, y 좌표로 같은 줄의 텍스트인지를 확인해가며, 띄어쓰기와 함께 이전 단어에 붙이거나 다음줄에서 새로운 메뉴명을 구성해내기 시작한다.
OCR 벤더가 바뀌고 OCR 결과의 응답 포맷이 크게 달라진다고 해도 적절히 기능별로 코드 설계를 해두면 얼마든지 전에 작성했던 코드도 변경 없이 활용할 수 있다.
Tesseract 에서 CLOVA OCR로 전환한 이후에는 인식률과 인식 속도가 매우 좋아졌다. 무엇보다 좋은건 램1GB의 저사양 무료 클라우드 컴퓨팅 인스턴스를 사용하고 있었는데 Tesseract 와 javaCV 를 걷어내니 빌드도 빨라지고 war 파일의 크기도 700MB 에서 20MB 로 줄어들었다.
성능 때문에 포기했던 CI/CD도 이제 가능해보인다.
구역나누기2
그렇게 한창을 잘 운영 하다가 몇 가지 문제가 발생했다.
첫 번째 문제: 네이버 modoo 중단 공지
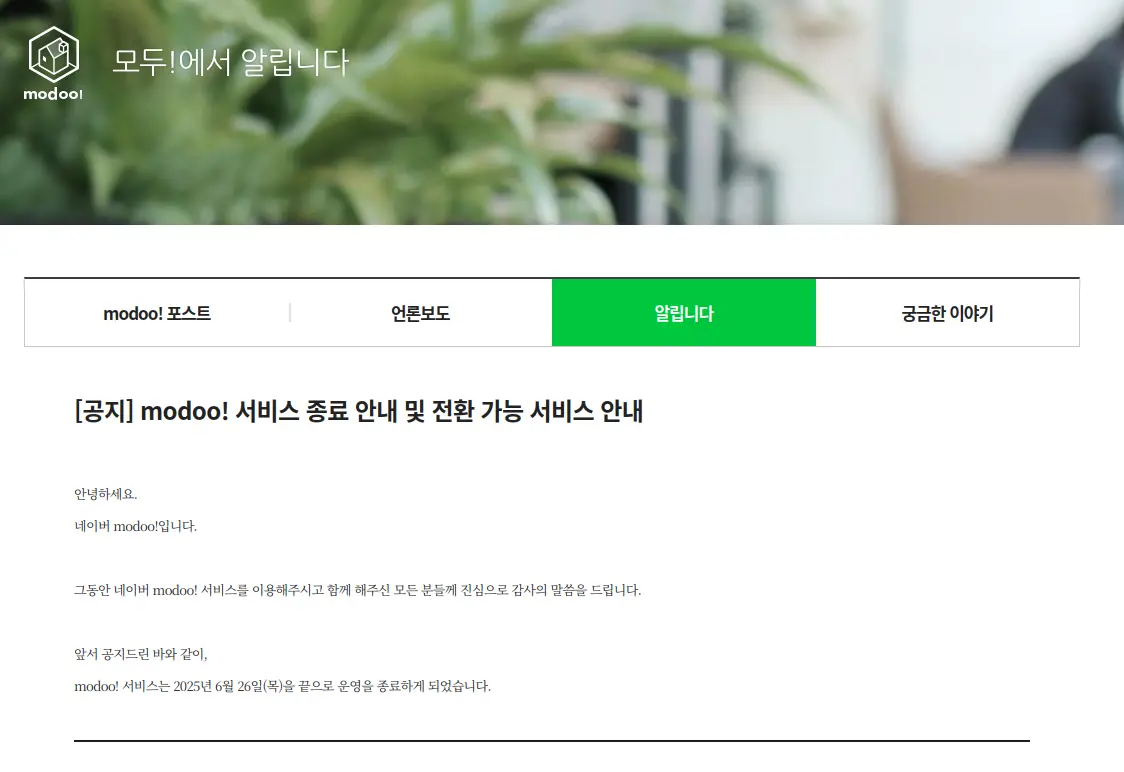
https://www.modoo.at/home/notice/noticeDetail?boardId=169&pageNum=1
메뉴가 올라오던 웹사이트를 modoo에서 호스팅 하고 있었기 때문에 메뉴가 더이상 업로드 되지 않을 수 있다. 그럼에도 첫 번째 문제는 해결할 필요도 없어진건 더 심각한 두번째 문제 때문이었는데
두 번째 문제: 회사에 배달오는 메뉴가 메뉴표에 올라온 메뉴와 다르게 제공되기 시작했다.
반년 이상 메뉴에 적혀 있는 메뉴가 정확히 배달왔었는데 갑자기 일주일 이상 메뉴가 계속 다른거다.
도시락 제공 업체에 문의한 결과 본사와 다르게 자체적으로 메뉴를 제공하기 시작했으며 메뉴는 카카오톡 프로필 사진으로 보여주니 카톡 친구추가를 해서 메뉴를 확인하라는거다.
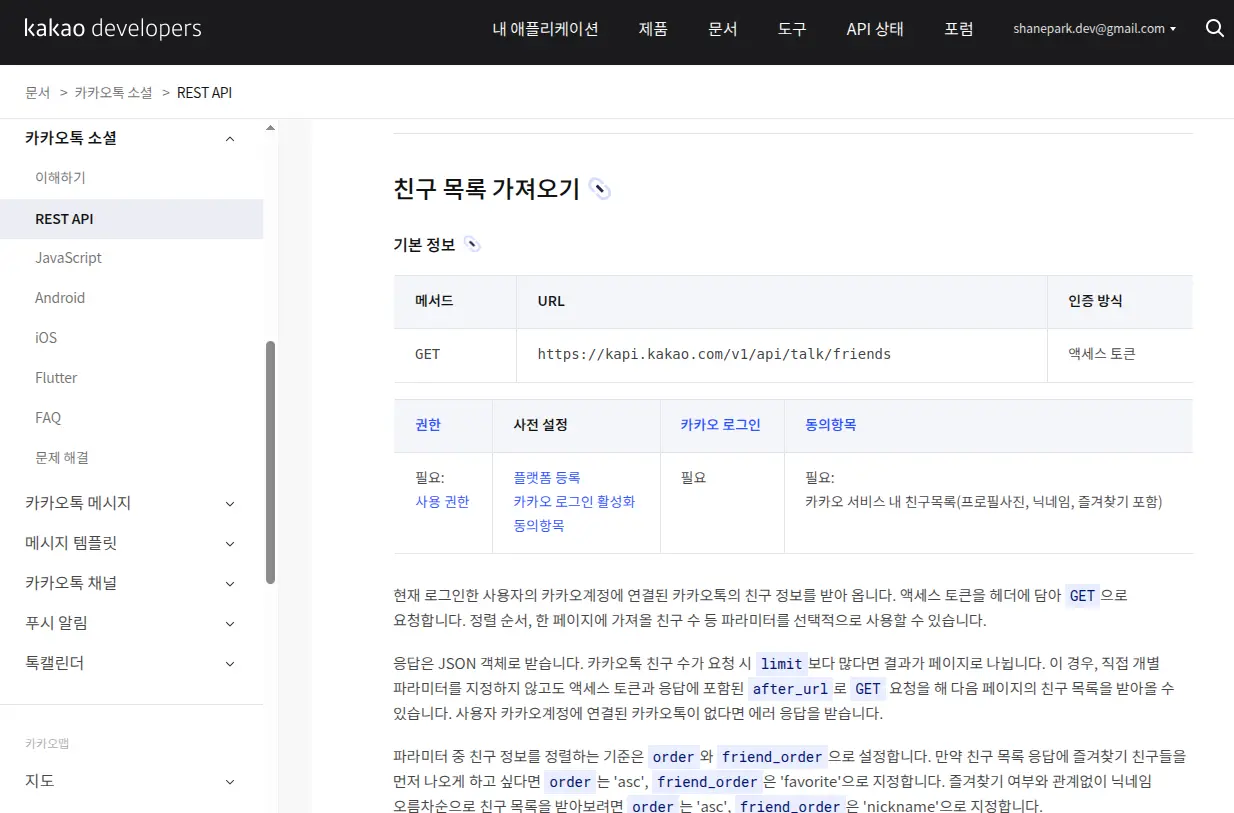
https://developers.kakao.com/docs/latest/ko/kakaotalk-social/rest-api
카카오톡 소셜의 친구 목록 가져오기 REST API를 테스트해보니 프로필 사진은 원본으로 제공하지 않고 썸네일로만 제공한다. 카카오 친구의 프로필 사진은 원본으로 저장이 안되며 스크린샷을 찍는다면 OCR 인식률이 크게 떨어진다.
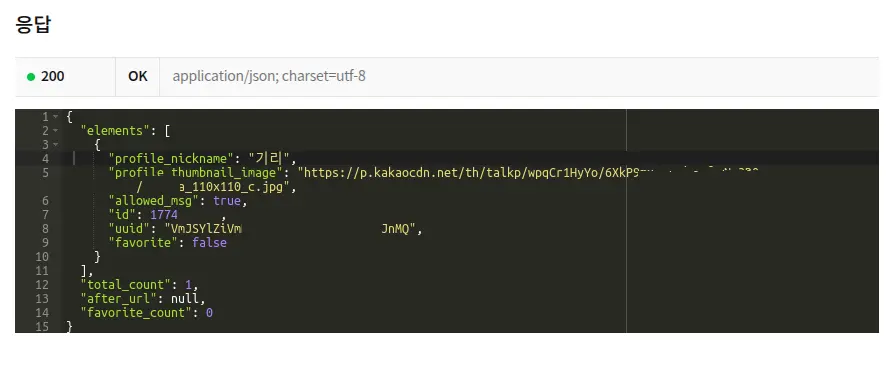
다행히도 프로필 썸네일 이미지 url에서 _110x110_c 라는 suffix를 제거하고 요청을 보내보니 썸네일 원본이 받아지긴 했다.
그럼에도 카카오톡 소셜 API에는 큰 함정이 있었으니,
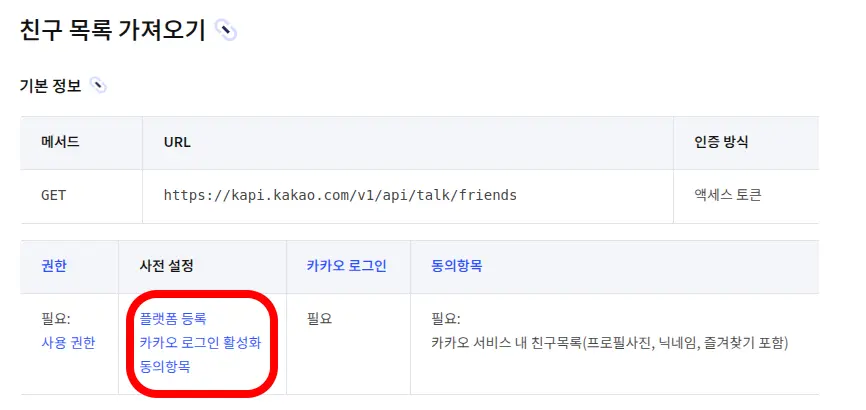
https://developers.kakao.com/docs/latest/ko/kakaotalk-social/rest-api#get-friends
그냥 친구추가만 되어있으면 끝나는게 아니고 나와 상대방이 모두 플랫폼(Kakao developers에 새로 등록한 어플리케이션)에 등록이 되어 있으며 카카오 서비스 내 친구목록(프로필사진, 닉네임, 즐겨찾기 포함) 에도 동의가 필요하다.
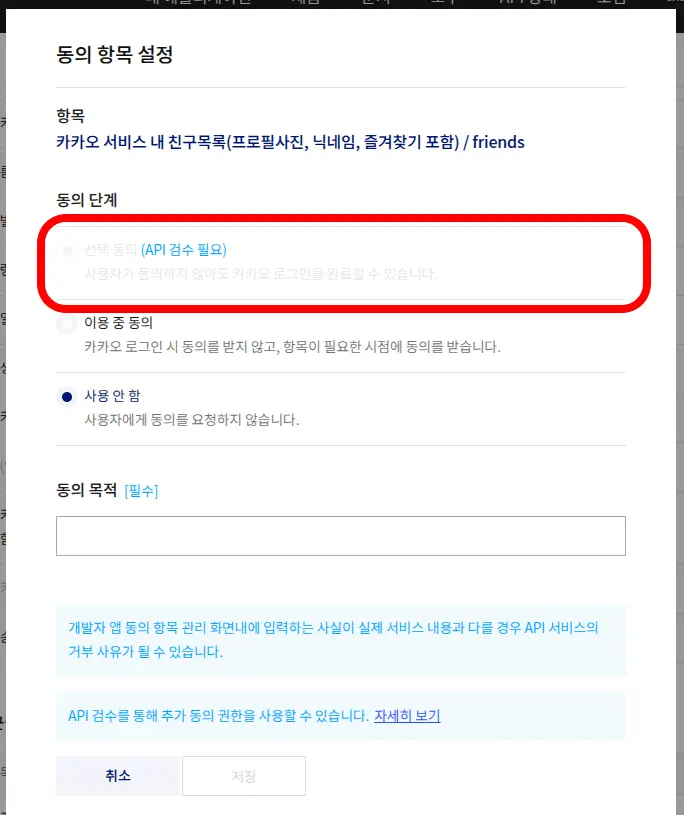
심지어 해당 동의 항목은 API 검수를 받아야 사용가능한데 업체에서 뭔지도 모르는 서비스에 가입 및 동의해줄리가 만무하다.
카카오톡은 포기하고 다른 방법을 찾아보려는데, 메뉴에 등록된 QR코드를 찍어보니 네이버 QR 코드를 통해 생성한 QR 코드 였고, 그래서 m.site.naver 링크가 자동으로 생성되어있어 그곳에서 식단표를 확인할 수 있었다.
이제 새로운 양식의 식단표를 대상으로 구역 나누기 및 OCR을 새로 해야한다. 자연스레 기존의 코드는 폐기하고 새로 작성하면 되는데, 여기에서 세번째 문제가 발생했다.
세번째 문제: 픽셀 컬러값으로 구역 나누기 실패
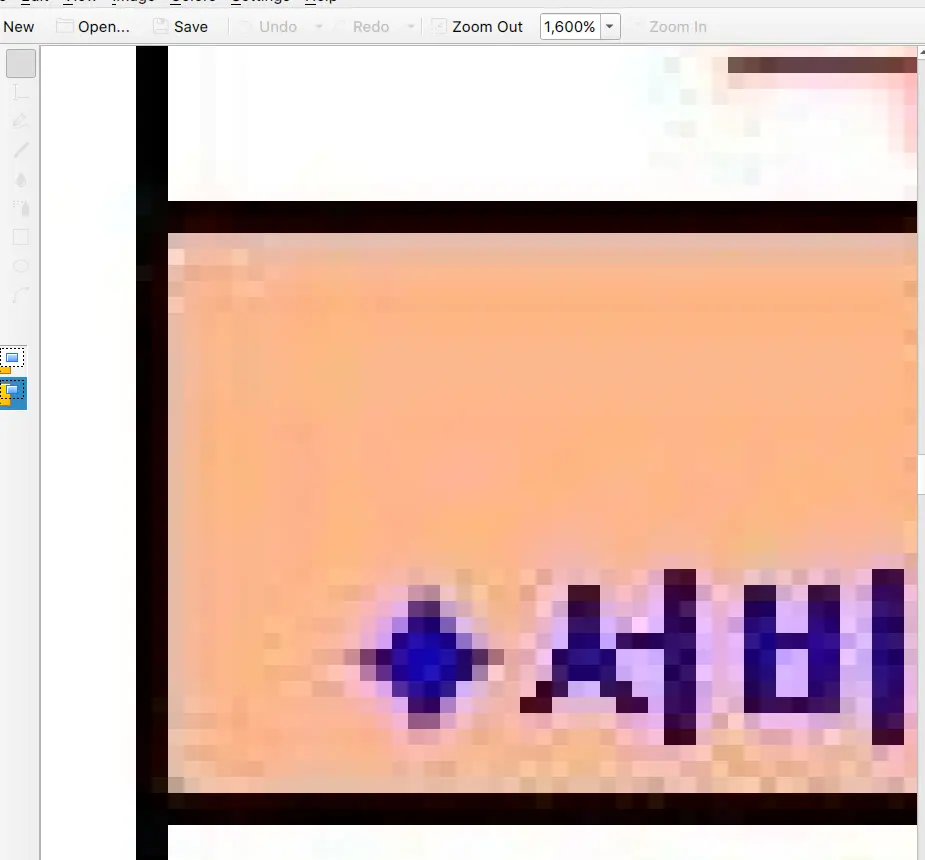
기존의 png 파일과 다르게 이번에는 jpg로 제공되는데 픽셀별 컬러를 따내서 영역을 나누는 전략이 더이상 먹히지 않는다. 확대해서 확인해보니 픽셀별 컬러가 제멋대로다.
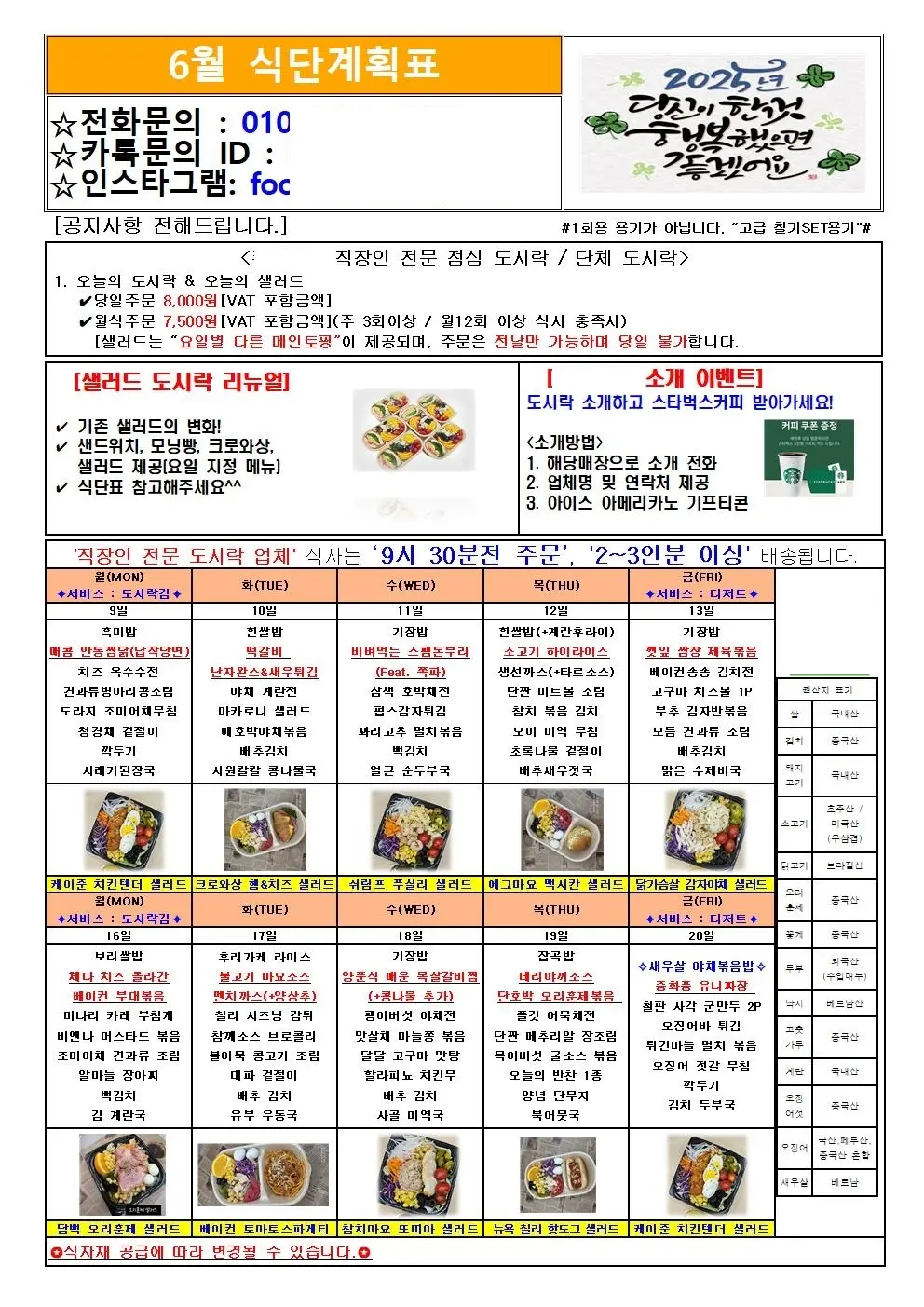
전체 이미지
이제부터는 구역을 나눌 때 새로운 전략으로 접근해야 한다.
기존에는 이미지의 픽셀 컬러만을 이용해서 구역을 나누어 냈다면, 이제는 OCR 결과를 포함해서 활용하기로 했다.
private final Pattern DATE_PATTERN = Pattern.compile("\\d{1,2}일");
private final Pattern DAY_PATTERN = Pattern.compile("MON|TUE|WED|THU|FRI");요일 및 일자 패턴들을 지정해놓고
public GridParser(JsonArray fields) {
for (JsonElement e : fields) {
JsonObject field = e.getAsJsonObject();
String inferText = field.get("inferText").getAsString();
if (DAY_PATTERN.matcher(inferText).find()) {
processDayPattern(field);
continue;
}
if (DATE_PATTERN.matcher(inferText).find()) {
processDate(field);
}
}
if (mondayVertices == null || tuesdayVertices == null) {
throw new IllegalStateException("월요일 또는 화요일 패턴이 발견되지 않았습니다.");
}
int midOfMonday = getMidX(mondayVertices);
int midOfTuesday = getMidX(tuesdayVertices);
width = midOfTuesday - midOfMonday - (GAP / 2);
startX = midOfMonday - (width / 2) - GAP;
}각 패턴에 따라 필요한 process 를 해준다.
- 요일 아래 랜덤하게 적히는
서비스로 인해 텍스트가 올라가는 경우가 있기 때문에 월~금 까지 모두 확인하여 가장 높은 y 값을 찾아낸다. - 월요일 및 화요일 패턴의 좌표로 저장해두는건 메뉴의 폭을 계산하기 위함이다. 각 요일의 텍스트는 가운데 정렬로 되어있기 때문에 월요일, 화요일의 각 중간 값 간의 거리가 거의 정확한 각 셀의 폭이 된다.
width = midOfTuesday - midOfMonday - (GAP / 2);이렇게 가운데 테두리 값만 빼주면 된다.
public void processDayPattern(JsonObject field) {
JsonArray vertices = getVertices(field);
JsonObject leftTop = vertices.get(0).getAsJsonObject();
String inferText = field.get("inferText").getAsString();
if (inferText.startsWith("월") && mondayVertices == null) {
mondayVertices = vertices;
}
if (inferText.startsWith("화") && tuesdayVertices == null) {
tuesdayVertices = vertices;
}
int y = leftTop.get("y").getAsInt();
if (menu1DateStart == -1) {
menu1DateStart = y;
return;
}
if (Math.abs(y - menu1DateStart) < 100) {
menu1DateStart = Math.min(menu1DateStart, y);
return;
}
menu2DateStart = Math.min(menu2DateStart, y);
}- y 값이 크게 변했을때(100 이상으로 조건을 걸었다) 는 그 다음 주로 넘어갔다는 뜻이다. 새로운 셀의 y값을 찾아준다. 자연스럽게 첫주의 메뉴가 끝나는 y값도 찾아진다.
{
"valueType": "ALL",
"boundingPoly": {
"vertices": [
{
"x": 54.0,
"y": 1335.0
},
{
"x": 119.0,
"y": 1335.0
},
{
"x": 119.0,
"y": 1353.0
},
{
"x": 54.0,
"y": 1353.0
}
]
},
"inferText": "c 자자재",
"inferConfidence": 0.8001
},마지막에 "식자재 공급에 따라 변경될 수 있습니다" 텍스트 부분이 아직 완전히 해결되지는 않았는데, 저기 들어간 텍스트만 이상하게 위에 보이는 것 처럼 inferConfidence 0.8에 c 자자재로 읽어버려서 텍스트 기반으로는 제거해낼 수가 없었다.
샐러드 텍스트가 자주 나오는 y값들을 저장해두고 그 끝을 유추해내는 방법을 쓰거나 혹은 ocr 응답을 전처리 해서 마지막 줄에 나오는 내용을 제거해버리는 등의 방법을 고려하고 있다.
앞으로 두어번 정도 새로 발행되는 메뉴 이미지들을 확인해보고 개선해보려 한다.
끝마침
다행히도 이렇게 만든 점심 봇은 반응이 좋은 편이다. 다들 개발자 답게 새로운 기능이나 개선에 대한 요청도 종종 해줘서 기쁜 마음으로 반영하곤 한다. 다만 코드 기여를 좀 해달라는 내 요청을 외면 하는 건 아쉽다.
모든 코드는 아래의 Github 저장소에 공개되어 있다.
'Development > DevLife' 카테고리의 다른 글
| 세번째 LeetCode 티셔츠 (1) | 2025.09.13 |
|---|---|
| Safari 는 또 다른 인터넷 익스플로러 (2) | 2025.03.01 |
| 두번째 LeetCode 티셔츠 (0) | 2024.04.21 |
| 스프링캠프 2023 (0) | 2023.04.25 |
| DEVIEW 2023에 다녀왔습니다 (0) | 2023.02.27 |